【 使用环境 】生产环境
【 OB or 其他组件 】obdiag
【 使用版本 】
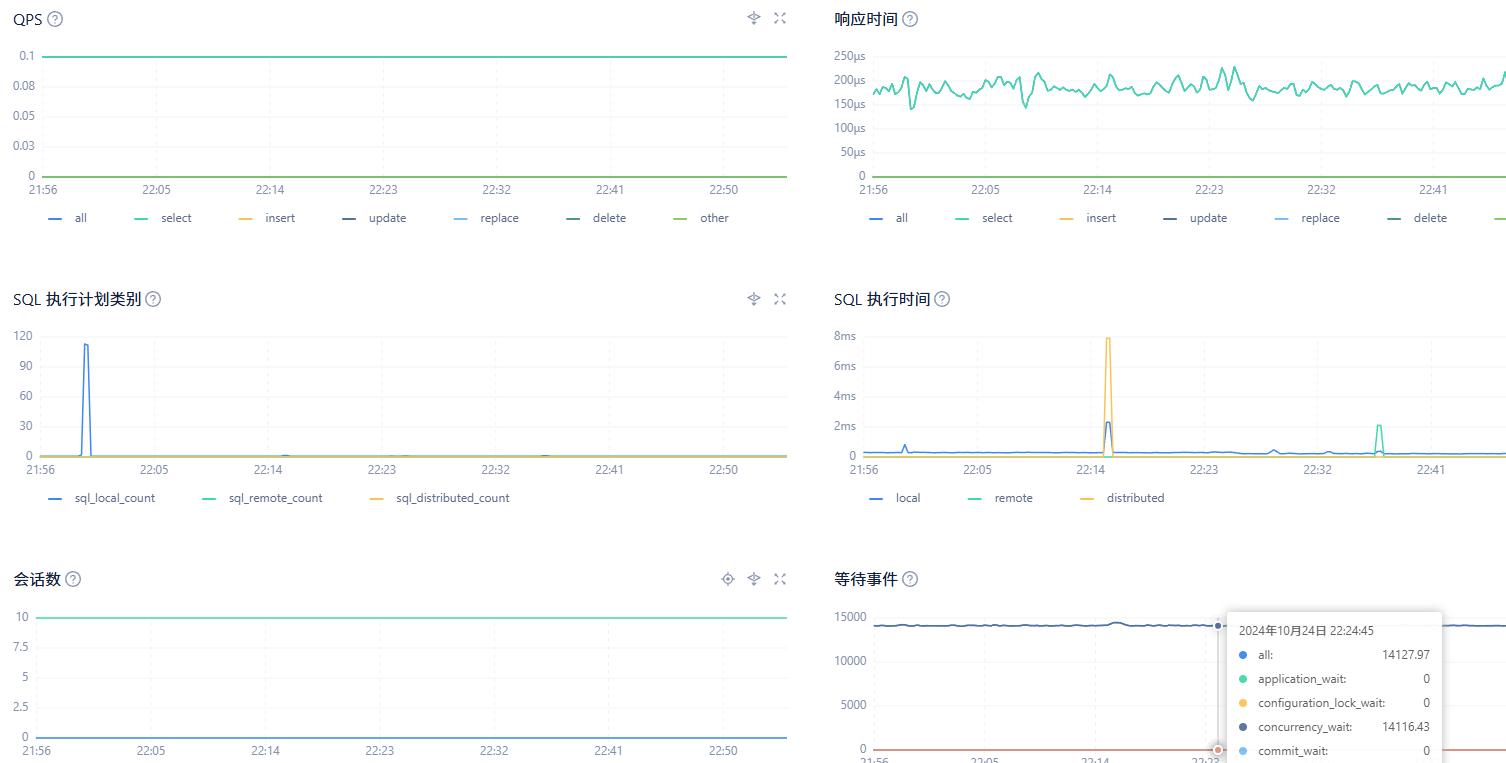
【问题描述】发现生产上SQL执行concurrency_wait_time高,用obdiag分析全链路日志,只能发现response_result比较高,无具体信息。请问该怎么进一步排查确定慢在哪里的问题?
【复现路径】无
【附件及日志】


【 使用环境 】生产环境
【 OB or 其他组件 】obdiag
【 使用版本 】
【问题描述】发现生产上SQL执行concurrency_wait_time高,用obdiag分析全链路日志,只能发现response_result比较高,无具体信息。请问该怎么进一步排查确定慢在哪里的问题?
【复现路径】无
【附件及日志】
推荐使用 obdiag 工具进行日志采集和根因分析,以便更深入地了解慢 SQL 的具体情况。
日志采集场景: SQL性能问题
日志采集命令: obdiag gather scene run --scene=observer.perf_sql --env “{db_connect=’-h127.0.0.1 -P2881 -utest@test -p****** -Dtest’, trace_id=‘Yxx’}”
在执行上述命令之前,请确保您已经替换了命令中的 <trace_id> 和数据库连接信息(如 -h127.0.0.1 -P2881 -utest@test -p****** -Dtest)为您实际环境中的值。此命令将收集与指定 trace_id 相关的 SQL 性能信息,帮助我们进一步分析慢 SQL 的原因。
另外,为了确定具体的问题,在此需要您提供一些信息:
trace_id 或者慢 SQL 的 sql_id?请您按照上述命令执行日志采集,并将采集到的日志压缩包提供给我们,以便我们能够更好地帮助您分析问题。
具体信息可参考以下文档:
附上敏捷诊断工具 obdiag 使用帮助链接
你使用的obdiag命令及分析结果方便发下吗?
官网有各tag的介绍,你把结果文件发出来我们安排研发看一下。(ip 建议混淆一下)
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000000818770
使用的obdiag analyze flt_trace --flt_trace_id 命令,结果是
67detail.txt (5.4 KB)
,实际是concurrency_wait_time高,也不是锁的问题,另外我们这个集群,即使是空闲的租户,也有很高的concurrency_wait事件。
根据您提供的信息,concurrency_wait_time 高且 response_result 时间长,但没有详细的慢 SQL 信息。这可能是因为 concurrency_wait_time 主要反映了 SQL 在执行过程中等待资源(如 CPU、内存、IO 等)的时间,而不仅仅是锁等待时间。即使在空闲的租户中,也可能因为资源竞争或其他内部调度问题导致 concurrency_wait_time 较高。
检查系统资源使用情况:
top -H 命令查看租户的 CPU 使用情况,确认是否有其他进程或任务占用了大量 CPU 资源。使用 sql_plan_monitor 获取性能报告:
/*+ monitor */ Hint,执行后获取 trace_id,然后使用以下 SQL 查询性能报告:-- 汇总
SELECT op_id, op, rows, rescan, threads, (close_time - open_time) open_dt, (last_row_eof_time - first_row_time) row_dt, open_time, close_time, first_row_time, last_row_eof_time
FROM (
SELECT plan_line_id op_id, CONCAT(LPAD('', plan_depth, ' '), plan_operation) op, SUM(output_rows) rows, SUM(STARTS) rescan, MIN(first_refresh_time) open_time, MAX(last_refresh_time) close_time, MIN(first_change_time) first_row_time, MAX(last_change_time) last_row_eof_time, COUNT(1) threads
FROM oceanbase.gv$sql_plan_monitor
WHERE trace_id = 'Yxxxxxxxxx'
GROUP BY plan_line_id, plan_operation
ORDER BY plan_line_id
) a;
-- 明细
SELECT op_id, thread, op, rows, rescan, (close_time - open_time) open_dt, (last_row_eof_time - first_row_time) row_dt, open_time, close_time, first_row_time, last_row_eof_time
FROM (
SELECT plan_line_id op_id, PROCESS_NAME thread, CONCAT(LPAD('', plan_depth, ' '), plan_operation) op, output_rows rows, STARTS rescan, first_refresh_time open_time, last_refresh_time close_time, first_change_time first_row_time, last_change_time last_row_eof_time
FROM oceanbase.gv$sql_plan_monitor
WHERE trace_id = 'Yxxxxxxxxx'
ORDER BY plan_line_id, PROCESS_NAME
) a;
检查 SQL 执行计划:
EXPLAIN 命令查看慢 SQL 的执行计划,确认是否存在索引缺失、全表扫描等问题。EXPLAIN SELECT * FROM t1 WHERE user_id = 'xxx' AND product_type = 'xxx' AND standard_category NOT IN ('xxx', 'xxx') ORDER BY gmt_last_trans DESC LIMIT 35;
检查系统监控指标:
GV$SYSSTAT 视图查看系统级别的监控指标,特别是与 SQL 执行相关的指标,如 sql insert time 和 sql insert count。SELECT /*+ read_consistency(weak) */ NAME, VALUE
FROM GV$SYSSTAT
WHERE SVR_IP = 'xxx'
AND STAT_ID IN (10000, 10001, 10002, 10003, 10005, 10006, 140002, 140003, 40006, 40007, 40008, 40009, 40010, 40011, 40012, 50000, 50001, 50008, 50009, 60000, 60001, 60002, 60003, 60004, 60005, 60019, 60020, 60021, 60022, 60023, 60024, 80057)
AND (CON_ID > 1000);
检查日志文件:
fgrep '[slow query]' /home/admin/oceanbase/log/observer.log | sed -e 's/|/\n/g' | more
top -H 和磁盘 I/O 使用情况显示有其他进程或任务占用了大量资源,可能是资源竞争导致的 concurrency_wait_time 高。EXPLAIN 显示存在索引缺失或全表扫描,优化索引或 SQL 语句可能有助于解决问题。GV$SYSSTAT 显示某些 SQL 执行时间较长,可以进一步分析这些 SQL 的执行计划和性能报告。希望以上步骤能帮助您进一步排查和解决问题。如果仍有疑问,欢迎继续提问。 [3]
具体信息可参考以下文档:
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
1.麻烦发下OB的版本,OCP版本 及concurrency_wait等待事件高的这个租户的配置
2.这里response_result比较高,麻烦使用obdiag采集下SQL性能信息
obdiag gather scene run --scene=observer.perf_sql --env “{db_connect=’-h127.0.0.1 -P2881 -utest@test -p****** -Dtest’, trace_id=‘Yxx’}”
https://www.oceanbase.com/docs/common-obdiag-cn-1000000001491226
3.发下如下执行结果
select sql_id, elapsed_time, queue_time, get_plan_time, execute_time, application_wait_time, concurrency_wait_time, user_io_wait_time, schedule_time, event, wait_class, wait_time_micro, total_wait_time_micro
from gv$ob_sql_audit
where trace_id = ‘xxxxx'\G;
提供一下ob的版本,另外concurrency_wait等待事件高要想进一步分析可以获取一下ash报告:https://www.oceanbase.com/docs/common-obdiag-cn-1000000001491196