【 使用环境 】生产环境
【 OB or 其他组件 】OB
【 使用版本 】4.2.2.0
【问题描述】同一个sql在MySQL和OB中执行顺序不通 SQL迁移后耗时过大
该SQL在MySQL中先进行b表查出结果 然后再去特大表中n中寻找数据 为什么在OB中会直接对特大表n进行全表扫描 ,表n中new为longtext字段 无法建设索引 只有INFOCODE有单列索引
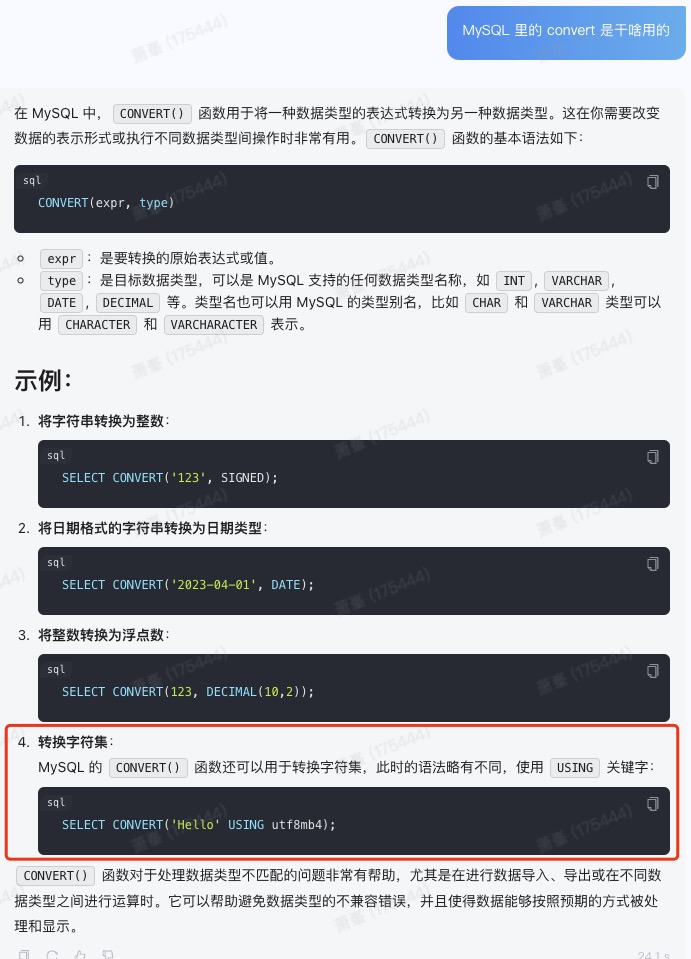
执行SQL
SELECT n.new
FROM info_an_notice_title_special b
JOIN info_an_content n ON b.INFOCODE = n.INFOCODE
WHERE b.SECURITYCODE = '832171' AND b.NOTICETYPE = '50004';
MYSQL执行计划
1 SIMPLE b const unique_key,idx_info_an_noticetitle_f10_isn unique_key 636 const,const 1 100.00
1 SIMPLE n range idx_INFOCODE idx_INFOCODE 603 1 100.00 Using where; Using index
OB执行计划
=================================================================
|ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)|
-----------------------------------------------------------------
|0 |EXCHANGE IN REMOTE | |1 |824458 |
|1 |└─EXCHANGE OUT REMOTE | |1 |824456 |
|2 | └─NESTED-LOOP JOIN | |1 |824450 |
|3 | ├─TABLE RANGE SCAN|b(unique_key) |1 |9 |
|4 | └─TABLE FULL SCAN |n(idx_INFOCODE)|11712799|353698 |
=================================================================
Outputs & filters:
-------------------------------------
0 - output([b.TZT_ID], [b.INFOCODE], [b.SECURITYCODE], [b.NOTICEDATE], [b.ENDDATE], [b.NOTICETITLE], [b.NOTICETYPE], [b.SOURCENAME], [b.TZT_INSERTTIME],
[b.TZT_UPDATETIME]), filter(nil)
1 - output([b.TZT_ID], [b.INFOCODE], [b.SECURITYCODE], [b.NOTICEDATE], [b.ENDDATE], [b.NOTICETITLE], [b.NOTICETYPE], [b.SOURCENAME], [b.TZT_INSERTTIME],
[b.TZT_UPDATETIME]), filter(nil)
2 - output([b.TZT_ID], [b.INFOCODE], [b.SECURITYCODE], [b.NOTICEDATE], [b.ENDDATE], [b.NOTICETITLE], [b.NOTICETYPE], [b.SOURCENAME], [b.TZT_INSERTTIME],
[b.TZT_UPDATETIME]), filter(nil), rowset=256
conds([b.INFOCODE = cast(n.INFOCODE, VARCHAR(1048576))]), nl_params_(nil), use_batch=false
3 - output([b.TZT_ID], [b.INFOCODE], [b.SECURITYCODE], [b.NOTICETYPE], [b.NOTICEDATE], [b.ENDDATE], [b.NOTICETITLE], [b.SOURCENAME], [b.TZT_INSERTTIME],
[b.TZT_UPDATETIME]), filter(nil), rowset=256
access([b.TZT_ID], [b.INFOCODE], [b.SECURITYCODE], [b.NOTICETYPE], [b.NOTICEDATE], [b.ENDDATE], [b.NOTICETITLE], [b.SOURCENAME], [b.TZT_INSERTTIME],
[b.TZT_UPDATETIME]), partitions(p0)
is_index_back=true, is_global_index=false,
range_key([b.SECURITYCODE], [b.NOTICETYPE], [b.shadow_pk_0]), range(832171,50004,MIN ; 832171,50004,MAX),
range_cond([b.SECURITYCODE = cast('832171', VARCHAR(1048576))], [b.NOTICETYPE = cast('50004', VARCHAR(1048576))])
4 - output([n.INFOCODE]), filter(nil), rowset=256
access([n.INFOCODE]), partitions(p0)
is_index_back=false, is_global_index=false,
range_key([n.INFOCODE], [n.EID]), range(MIN,MIN ; MAX,MAX)always true