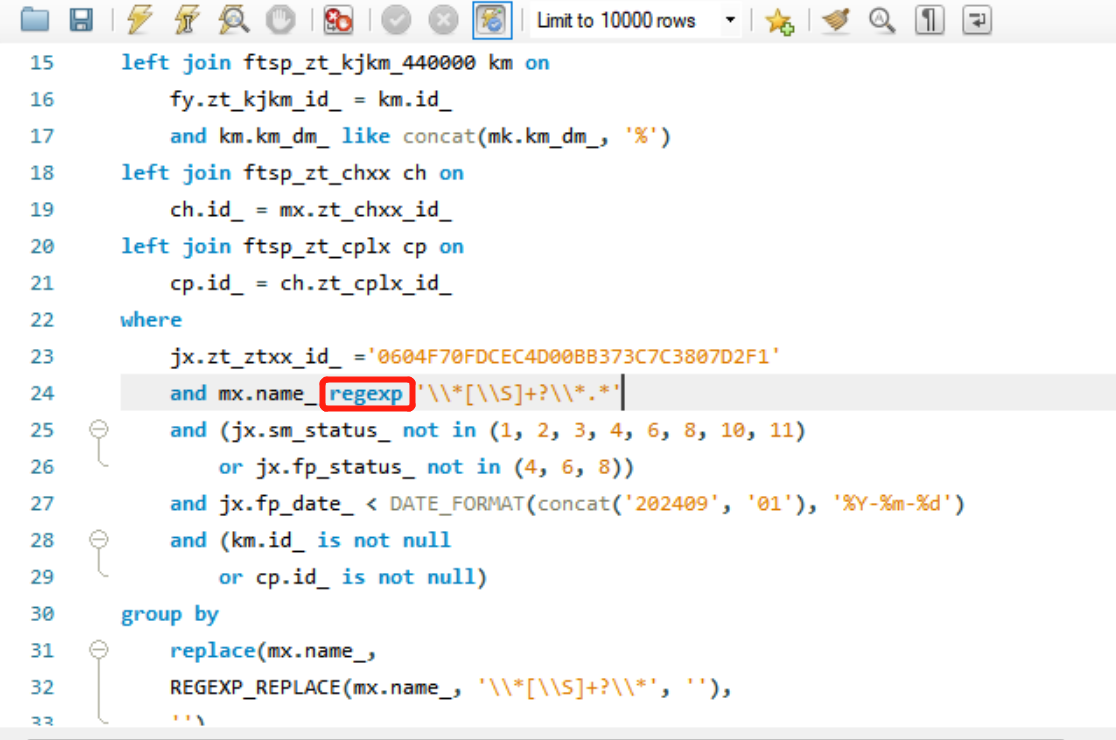
原SQL:
select
if(CHAR_LENGTH(mx.name_) - CHAR_LENGTH(replace(mx.name_, '*', '')) >= 2 ,
SUBSTRING_INDEX(SUBSTRING_INDEX(mx.name_, '*', 2), '*', -1),
mx.name_) ssflJc
from
ftsp_fp_jx jx
left join ftsp_fp_jx_mx mx on
mx.fp_jx_id_ = jx.id_
left join ftsp_zt_kjkm_440000 mk on
mk.zt_ztxx_id_ = jx.zt_ztxx_id_
and mk.km_nbbm_ = '50020'
left join ftsp_zt_fylx fy on
mx.zt_fylx_id_ = fy.id_
left join ftsp_zt_kjkm_440000 km on
fy.zt_kjkm_id_ = km.id_
and km.km_dm_ like concat(mk.km_dm_, '%')
left join ftsp_zt_chxx ch on
ch.id_ = mx.zt_chxx_id_
left join ftsp_zt_cplx cp on
cp.id_ = ch.zt_cplx_id_
where
jx.zt_ztxx_id_ ='0604F70FDCEC4D00BB373C7C3807D2F1'
and mx.name_ regexp '\\*[\\S]+?\\*.*'
and (jx.sm_status_ not in (1, 2, 3, 4, 6, 8, 10, 11)
or jx.fp_status_ not in (4, 6, 8))
and jx.fp_date_ < DATE_FORMAT(concat('202409', '01'), '%Y-%m-%d')
and (km.id_ is not null
or cp.id_ is not null)
group by
replace(mx.name_,
REGEXP_REPLACE(mx.name_, '\\*[\\S]+?\\*', ''),
'')
order by
jx.fp_date_ desc
limit 5;
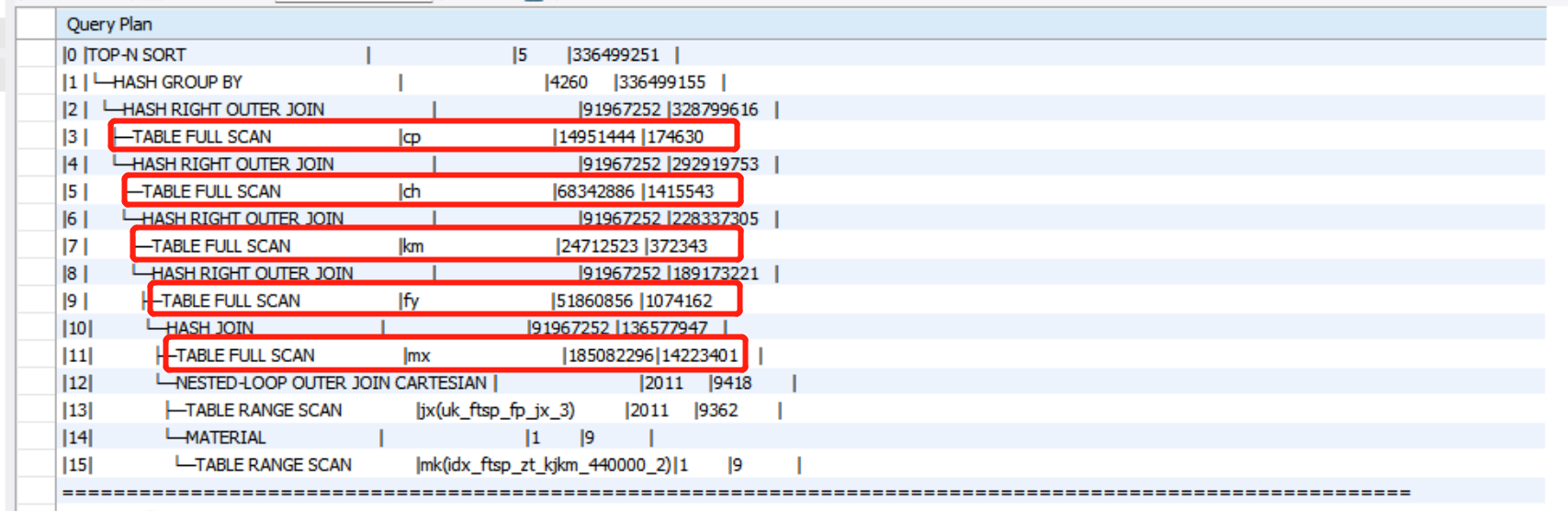
执行计划:
=========================================================================================================
|ID|OPERATOR |NAME |EST.ROWS |EST.TIME(us)|
---------------------------------------------------------------------------------------------------------
|0 |TOP-N SORT | |5 |268358106 |
|1 |└─HASH GROUP BY | |4260 |268358010 |
|2 | └─HASH RIGHT OUTER JOIN | |91967252 |260658471 |
|3 | ├─TABLE FULL SCAN |km |24712821 |372348 |
|4 | └─HASH RIGHT OUTER JOIN | |91967252 |221494207 |
|5 | ├─TABLE FULL SCAN |cp |14951444 |174630 |
|6 | └─HASH RIGHT OUTER JOIN | |91967252 |185614343 |
|7 | ├─TABLE FULL SCAN |ch |68342886 |1415543 |
|8 | └─HASH RIGHT OUTER JOIN | |91967252 |121031896 |
|9 | ├─TABLE FULL SCAN |fy |51861168 |1074168 |
|10| └─HASH JOIN | |91967252 |68436451 |
|11| ├─NESTED-LOOP OUTER JOIN CARTESIAN | |2011 |9418 |
|12| │ ├─TABLE RANGE SCAN |jx(uk_ftsp_fp_jx_3) |2011 |9362 |
|13| │ └─MATERIAL | |1 |9 |
|14| │ └─TABLE RANGE SCAN |mk(idx_ftsp_zt_kjkm_440000_2)|1 |9 |
|15| └─TABLE FULL SCAN |mx |185082296|14223401 |
=========================================================================================================
Outputs & filters:
-------------------------------------
0 - output([CASE WHEN CHAR_LENGTH(mx.name_) - CHAR_LENGTH(replace(mx.name_, '*', '')) >= 2 THEN SUBSTRING_INDEX(SUBSTRING_INDEX(mx.name_, '*', 2), '*',
-1) ELSE mx.name_ END]), filter(nil), rowset=8
sort_keys([jx.fp_date_, DESC]), topn(5)
1 - output([jx.fp_date_], [mx.name_]), filter(nil), rowset=8
group([replace(mx.name_, cast(REGEXP_REPLACE(cast(mx.name_, VARCHAR(1048576)), cast('\\*[\\S]+?\\*', VARCHAR(1048576)), cast('', VARCHAR(1048576))),
VARCHAR(1048576)), '')]), agg_func(nil)
2 - output([jx.fp_date_], [mx.name_]), filter([km.id_ IS NOT NULL OR cp.id_ IS NOT NULL]), rowset=8
equal_conds([fy.zt_kjkm_id_ = km.id_]), other_conds([(T_OP_LIKE, km.km_dm_, concat(mk.km_dm_, '%'), '\\')])
3 - output([km.id_], [km.km_dm_]), filter(nil), rowset=8
access([km.id_], [km.km_dm_]), partitions(p0)
is_index_back=false, is_global_index=false,
range_key([km.id_]), range(MIN ; MAX)always true
4 - output([jx.fp_date_], [mx.name_], [cp.id_], [fy.zt_kjkm_id_], [mk.km_dm_]), filter(nil), rowset=8
equal_conds([cp.id_ = ch.zt_cplx_id_]), other_conds(nil)
5 - output([cp.id_]), filter(nil), rowset=8
access([cp.id_]), partitions(p0)
is_index_back=false, is_global_index=false,
range_key([cp.id_]), range(MIN ; MAX)always true
6 - output([jx.fp_date_], [mx.name_], [ch.zt_cplx_id_], [fy.zt_kjkm_id_], [mk.km_dm_]), filter(nil), rowset=8
equal_conds([ch.id_ = mx.zt_chxx_id_]), other_conds(nil)
7 - output([ch.id_], [ch.zt_cplx_id_]), filter(nil), rowset=8
access([ch.id_], [ch.zt_cplx_id_]), partitions(p0)
is_index_back=false, is_global_index=false,
range_key([ch.id_]), range(MIN ; MAX)always true
8 - output([jx.fp_date_], [mx.name_], [fy.zt_kjkm_id_], [mk.km_dm_], [mx.zt_chxx_id_]), filter(nil), rowset=8
equal_conds([mx.zt_fylx_id_ = fy.id_]), other_conds(nil)
9 - output([fy.id_], [fy.zt_kjkm_id_]), filter(nil), rowset=8
access([fy.id_], [fy.zt_kjkm_id_]), partitions(p0)
is_index_back=false, is_global_index=false,
range_key([fy.id_]), range(MIN ; MAX)always true
10 - output([jx.fp_date_], [mx.name_], [mk.km_dm_], [mx.zt_fylx_id_], [mx.zt_chxx_id_]), filter(nil), rowset=8
equal_conds([mx.fp_jx_id_ = jx.id_]), other_conds(nil)
11 - output([jx.fp_date_], [jx.id_], [mk.km_dm_]), filter(nil), rowset=8
conds(nil), nl_params_(nil), use_batch=false
12 - output([jx.id_], [jx.fp_date_]), filter([jx.fp_date_ < INTERNAL_FUNCTION(DATE_FORMAT(concat('202409', '01'), '%Y-%m-%d'), 113, 17)], [(T_OP_NOT_IN,
jx.sm_status_, (1, 2, 3, 4, 6, 8, 10, 11)) OR (T_OP_NOT_IN, jx.fp_status_, (4, 6, 8))]), rowset=8
access([jx.id_], [jx.sm_status_], [jx.fp_status_], [jx.fp_date_]), partitions(p0)
is_index_back=true, is_global_index=false, filter_before_indexback[false,false],
range_key([jx.zt_ztxx_id_], [jx.fp_dm_], [jx.fp_hm_], [jx.shadow_pk_0]), range(0604F70FDCEC4D00BB373C7C3807D2F1,MIN,MIN,MIN ; 0604F70FDCEC4D00BB373C7C3807D2F1,
MAX,MAX,MAX),
range_cond([jx.zt_ztxx_id_ = '0604F70FDCEC4D00BB373C7C3807D2F1'])
13 - output([mk.km_dm_]), filter(nil), rowset=8
14 - output([mk.km_dm_]), filter(nil), rowset=8
access([mk.id_], [mk.km_dm_]), partitions(p0)
is_index_back=true, is_global_index=false,
range_key([mk.zt_ztxx_id_], [mk.km_nbbm_], [mk.id_]), range(0604F70FDCEC4D00BB373C7C3807D2F1,50020,MIN ; 0604F70FDCEC4D00BB373C7C3807D2F1,50020,MAX),
range_cond([cast(mk.km_nbbm_, DECIMAL(11, 0)) = cast('50020', DECIMAL(1, -1))], [mk.zt_ztxx_id_ = '0604F70FDCEC4D00BB373C7C3807D2F1'])
15 - output([mx.fp_jx_id_], [mx.zt_fylx_id_], [mx.zt_chxx_id_], [mx.name_]), filter([(T_OP_REGEXP, cast(mx.name_, VARCHAR(1048576)), cast('\\*[\\S]+?\\*.*',
VARCHAR(1048576)))]), rowset=8
access([mx.fp_jx_id_], [mx.zt_fylx_id_], [mx.zt_chxx_id_], [mx.name_]), partitions(p0)
is_index_back=false, is_global_index=false, filter_before_indexback[false],
range_key([mx.id_]), range(MIN ; MAX)always true