【 使用环境 】生产环境
【 OB or 其他组件 】oceanbase
【 使用版本 】 4.2.1-8BP
【问题描述】
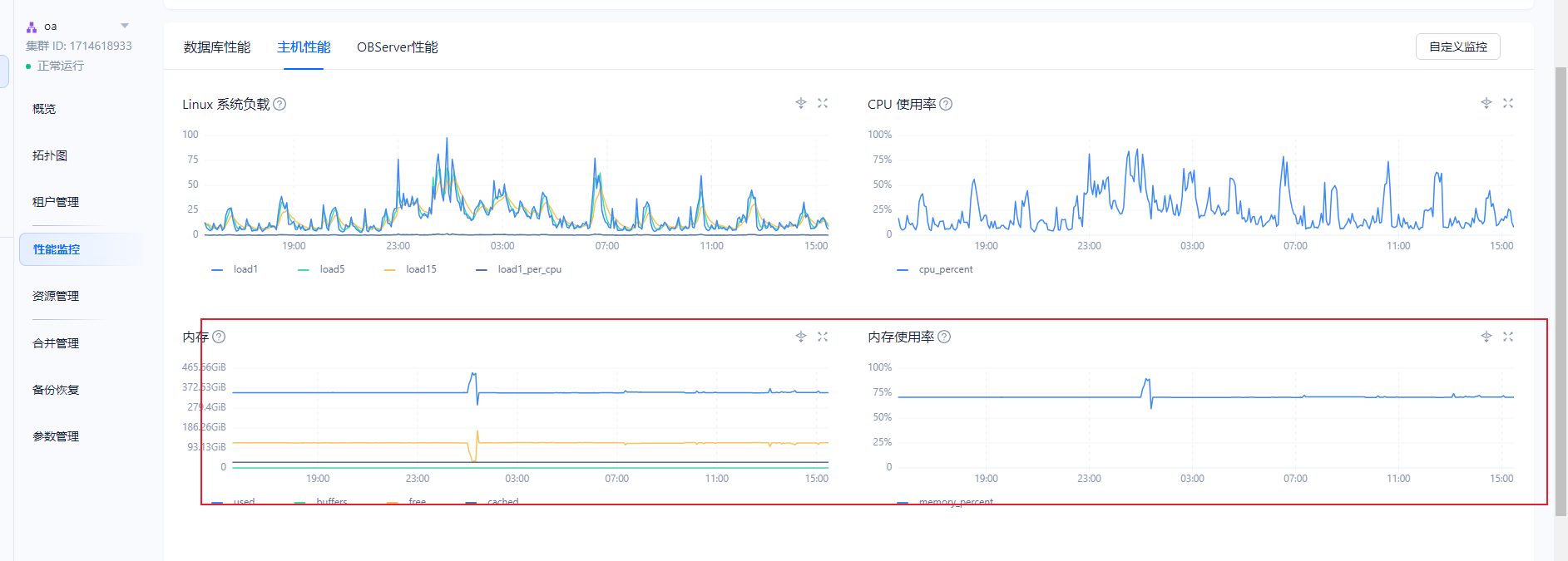
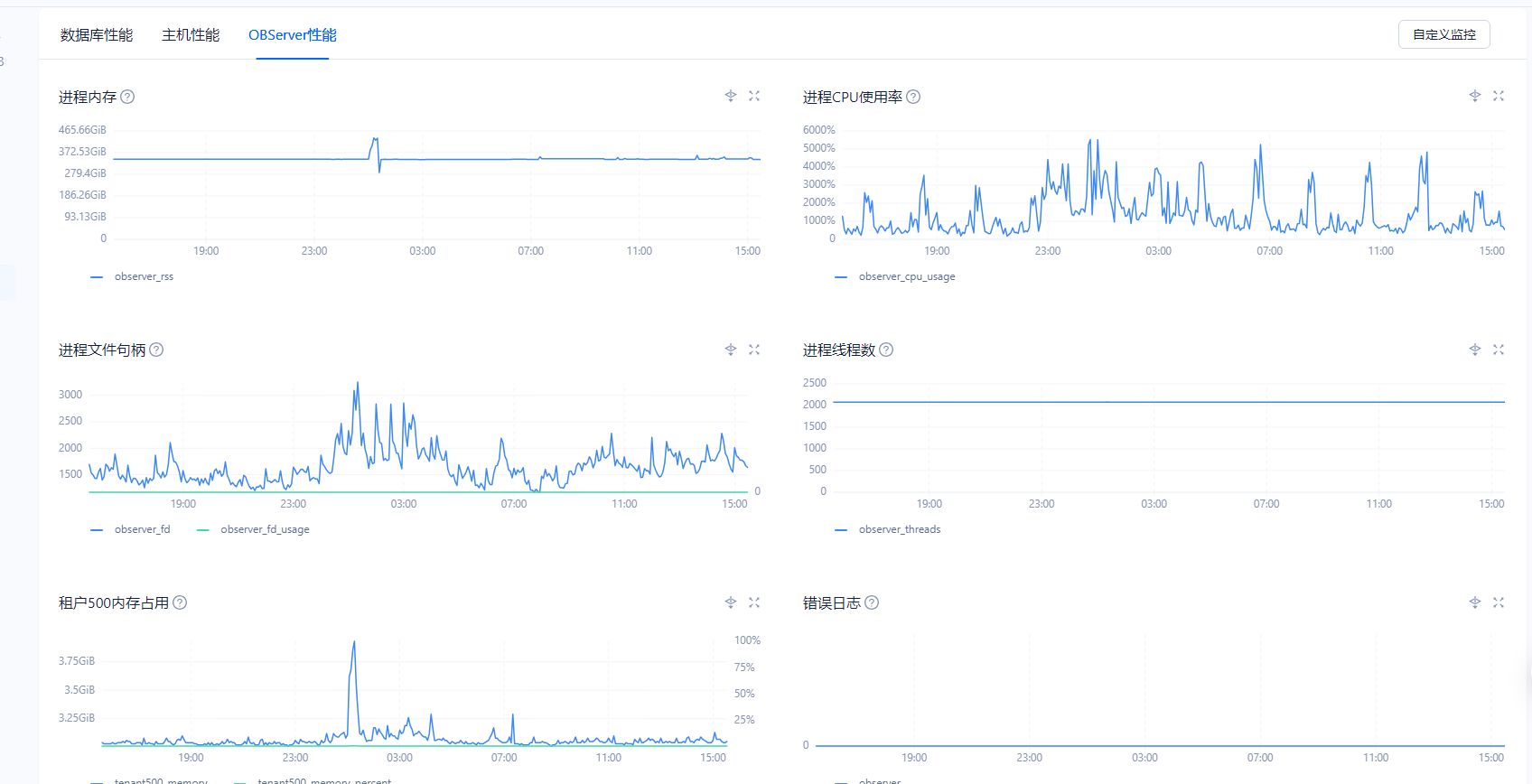
如下图所示, 每天在1点钟,会有2台机器出现内存激增接近20%的情况
该如何排查问题
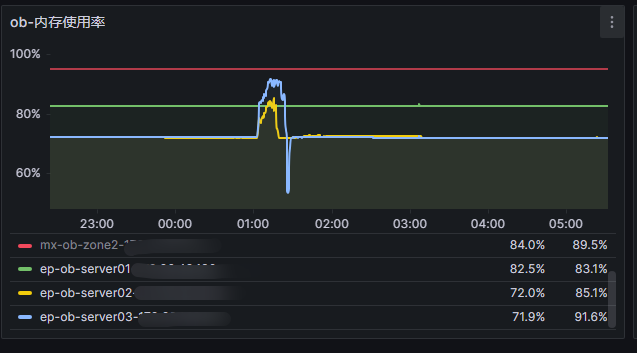
而且三台zone相同配置。 其中一台常驻了82.5%内存。其他2台zone仅72%内存。 如何调整
【 使用环境 】生产环境
【 OB or 其他组件 】oceanbase
【 使用版本 】 4.2.1-8BP
【问题描述】
如下图所示, 每天在1点钟,会有2台机器出现内存激增接近20%的情况
该如何排查问题
而且三台zone相同配置。 其中一台常驻了82.5%内存。其他2台zone仅72%内存。 如何调整
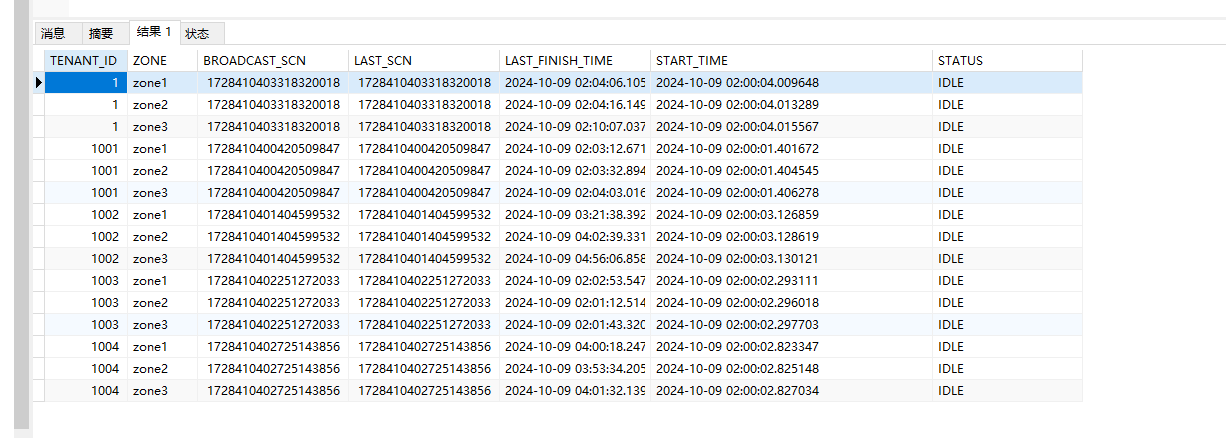
–查看下合并操作的信息
SELECT
*
FROM
cdb_ob_zone_major_compaction;
推荐先用诊断工具 obdiag 巡检一下看看是不是有已知的问题,把巡检报告发出来,使用文档:https://www.oceanbase.com/docs/common-obdiag-cn-1000000001326848
看obdiag巡检报告中有一条
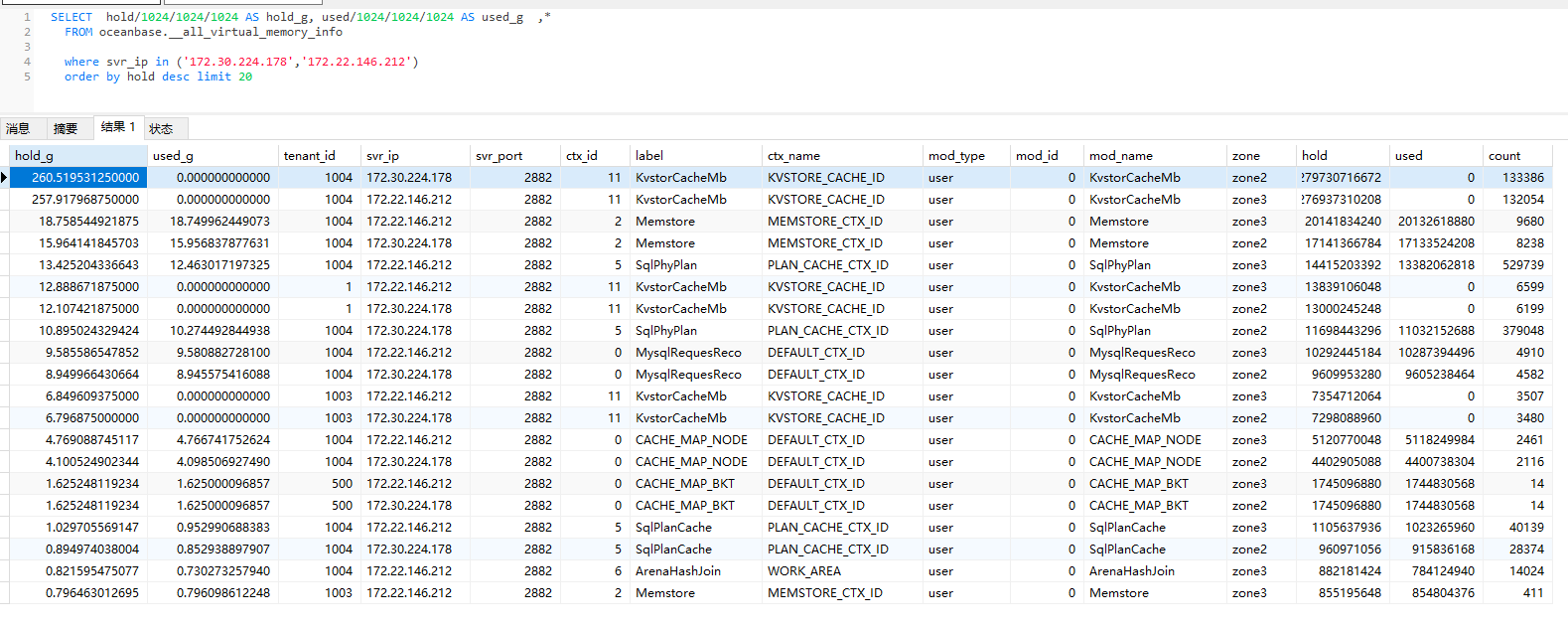
[warning] [cluster:obcluster] mod max memory over 10G,Please check on oceanbase.__all_virtual_memory_info to find some large mod。这条是扫到内存有超过10GB的模块存在,建议发一下oceanbase.__all_virtual_memory_info表的信息出来。语句:
SELECT hold/1024/1024/1024 AS hold_g, used/1024/1024/1024 AS used_g
FROM oceanbase.__all_virtual_memory_info
order by hold desc limit 20
从 memstore内存使用率看起来就是业务写导致内存有波动。
可以问问应用有什么定时任务大批量更新或写入数据。
此外,从 gv$ob_sql_audit 里查询这段时间内的业务sql,select 带上 affected_rows ,更新或插入很多的或者 tps很高的sql 大概就是源头了。
从内存使用率看很平,上面memstore 的一点点波动对总的内存使用率影响也不是很大。
你的问题里那个 监控图取数据逻辑就需要看看 到底是哪个内存使用率。
这是哪里的监控看到的呢?
你在ocp–>集群–>性能监控–>主机性能–>内存 看下呢?
需要先确认下是否为OB导致的内存使用率突增,
在服务器上设个定时任务,收集下内存使用率发生变化时间附近的各个程序的内存使用率情况,然后分析下对比哪个程序的内存占用发生了较大变化
top -b -n 7200 > mem.log
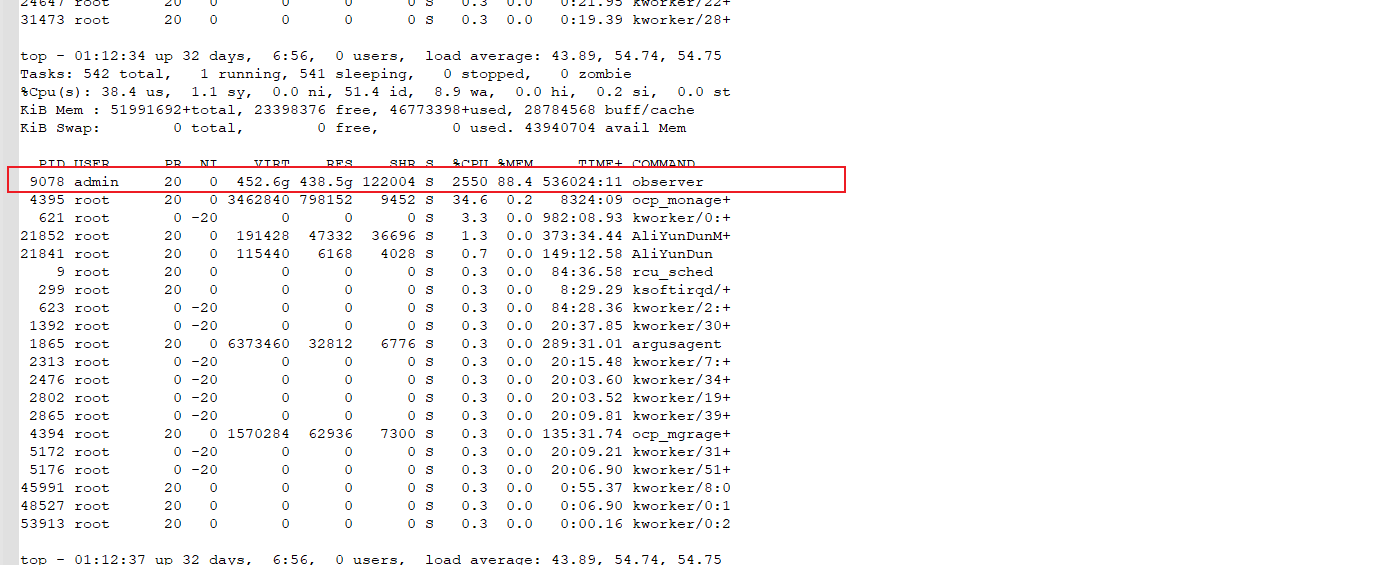
确实属于observer进程的内存波动。如下,
第一张为平时常驻使用内存
第二张为突增时间段使用的内存
以下为从凌晨 0:58开始执行 top -b -n 1000 命令打印的日志信息
memory.log (1.9 MB)
现象:observer的内存使用率在20分钟的时间突增20%左右,随后又降下来恢复正常,已排除合并原因
1.麻烦发下这段时间的observer.log
2.需要在这段时间间隔几秒(5秒)持续执行如下SQL,看下哪个或哪些mod占用的内存增加了
select * from gv$ob_memory where SVR_IP=‘xxxx’ order by used desc limit 20;
3.查下自动统计信息收集任务的窗口
SELECT tenant_id,
job_name,
what,
start_date,
this_date,
last_date,
next_date,
enabled
FROM oceanbase.__all_virtual_tenant_scheduler_job
WHERE job_name IN ( 'MONDAY_WINDOW', 'TUESDAY_WINDOW', 'WEDNESDAY_WINDOW',
'THURSDAY_WINDOW',
'FRIDAY_WINDOW', 'SATURDAY_WINDOW', 'SUNDAY_WINDOW' )
AND job != 0;
4.查下备份任务窗口
SELECT * FROM oceanbase.DBA_OB_BACKUP_JOB_HISTORY;