论坛小助手
#12
根据您提供的信息,您已经分配了足够的磁盘空间给OceanBase集群,但从日志来看,似乎并没有实际生效。这可能是因为OceanBase集群尚未正确识别到新的磁盘空间分配。以下是一些可能的原因和解决方案:
1. 确认磁盘挂载情况
首先确保新分配的磁盘空间已经被正确挂载到OceanBase集群所需的目录。您可以使用df -h命令来检查磁盘挂载情况,并确认是否已经挂载到预期的位置。例如,OceanBase集群通常会将数据存储在/data目录下,因此请确保该目录有足够的空间。
2. 重新初始化集群
如果磁盘已经正确挂载,但集群仍然无法识别新的磁盘空间,您可以尝试重新初始化集群。具体步骤如下:
# 停止集群
obd cluster stop <cluster_name>
# 删除集群数据
rm -rf /data/*
# 重新初始化集群
obd cluster init <cluster_name>
3. 调整配置文件
如果重新初始化集群后仍然存在问题,您可以尝试调整集群的配置文件,确保配置文件中的磁盘路径设置正确。使用以下命令编辑配置文件:
obd cluster edit-config <cluster_name>
在配置文件中,确保data_dir和redo_dir指向正确的磁盘路径。例如:
data_dir: /data
redo_dir: /data
4. 检查日志文件
如果以上步骤仍然无法解决问题,建议查看集群的日志文件,以获取更详细的错误信息。您可以使用以下命令查看日志:
tail -f /data/observer.log
5. 使用obdiag工具
最后,推荐使用OceanBase敏捷诊断工具obdiag来收集诊断信息,以便于进一步分析问题原因。详情参见链接:https://ask.oceanbase.com/t/topic/35605619。
示例命令
假设您已经分配了新的磁盘空间,并将其挂载到/data目录,您可以按照以下步骤操作:
# 检查磁盘挂载情况
df -h
# 停止集群
obd cluster stop test-ob-62
# 删除集群数据
rm -rf /data/*
# 重新初始化集群
obd cluster init test-ob-62
# 编辑配置文件
obd cluster edit-config test-ob-62
# 在配置文件中设置正确的磁盘路径
data_dir: /data
redo_dir: /data
# 启动集群
obd cluster start test-ob-62
总结
-
确认磁盘挂载情况:使用
df -h命令检查磁盘挂载情况。
-
重新初始化集群:停止集群、删除数据、重新初始化。
-
调整配置文件:确保配置文件中的磁盘路径设置正确。
-
检查日志文件:查看集群日志文件获取详细错误信息。
-
使用obdiag工具:收集诊断信息以便进一步分析问题原因。
希望这些步骤能帮助您解决问题。如果问题依然存在,请提供更多详细信息以便进一步诊断。
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
1 个赞
tiutiu
#13
user:
username: admin
password: JWIKu1PXrUNi51couY
port: 22
oceanbase-ce:
version: 4.2.0.0
release: 101000032023091319.el7
package_hash: 176ae96ab6ea606c860e0a9db09f8046eec0ceba
172.16.17.3:
zone: zone1
172.16.17.4:
zone: zone2
172.16.17.5:
zone: zone3
servers:
- 172.16.17.3
- 172.16.17.4
- 172.16.17.5
global:
appname: fjjfoceanbase
root_password: XY2zBc6J7mBnnt0Y_@0307
mysql_port: 2881
rpc_port: 2882
data_dir: /data
redo_dir: /redo
home_path: /home/admin/fjjfoceanbase/oceanbase
devname: ens192
datafile_size: 150G
log_disk_size: 100G
memory_limit: 36G
ocp_meta_tenant_max_cpu: ‘1’
ocp_meta_tenant_memory_size: 2G
ocp_agent_monitor_password: qwvIryGU0q
proxyro_password: SxvtQOAULf
ocp_meta_password: tN0Td7waHY
ocp_meta_tenant_log_disk_size: 7G
enable_syslog_recycle: true
enable_syslog_wf: false
max_syslog_file_count: 4
system_memory: 3G
cpu_count: 16
production_mode: false
obproxy-ce:
version: 4.2.0.0
package_hash: b3ead2f667d69fe3195fd22002de83df6eb19382
release: 7.el7
servers:
- 172.16.17.3
- 172.16.17.4
- 172.16.17.5
global:
prometheus_listen_port: 2884
listen_port: 2883
home_path: /home/admin/fjjfoceanbase/obproxy
obproxy_sys_password: 18F5r01Tbk
skip_proxy_sys_private_check: true
enable_strict_kernel_release: false
enable_cluster_checkout: false
rs_list: 172.16.17.3:2881;172.16.17.4:2881;172.16.17.5:2881
observer_sys_password: SxvtQOAULf
cluster_name: fjjfoceanbase
observer_root_password: XY2zBc6J7mBnnt0Y_@0307
depends:
- oceanbase-ce
obagent:
version: 4.2.0
package_hash: 30793df12dc6b8ec5ccdc93262e5e9f1d51ed50a
release: 3.el7
servers:
- 172.16.17.3
- 172.16.17.4
- 172.16.17.5
global:
monagent_http_port: 8088
mgragent_http_port: 8089
home_path: /home/admin/fjjfoceanbase/obagent
http_basic_auth_user: admin
http_basic_auth_password: CFPJmCAi9G
ob_monitor_status: active
depends:
- oceanbase-ce
ocp-express:
version: 4.2.0
package_hash: ccec08112a29067633797d20685b6e6d70e890d9
release: 100000042023073111.el7
servers:
- 172.16.17.2
global:
port: 8180
home_path: /home/admin/fjjfoceanbase/ocpexpress
java_bin: java
logging_file_max_size: 100MB
logging_file_total_size_cap: 1GB
admin_passwd: I8rF2#_z
memory_size: 872M
depends:
- obagent
- oceanbase-ce
- obproxy-ce
旭辉
#14
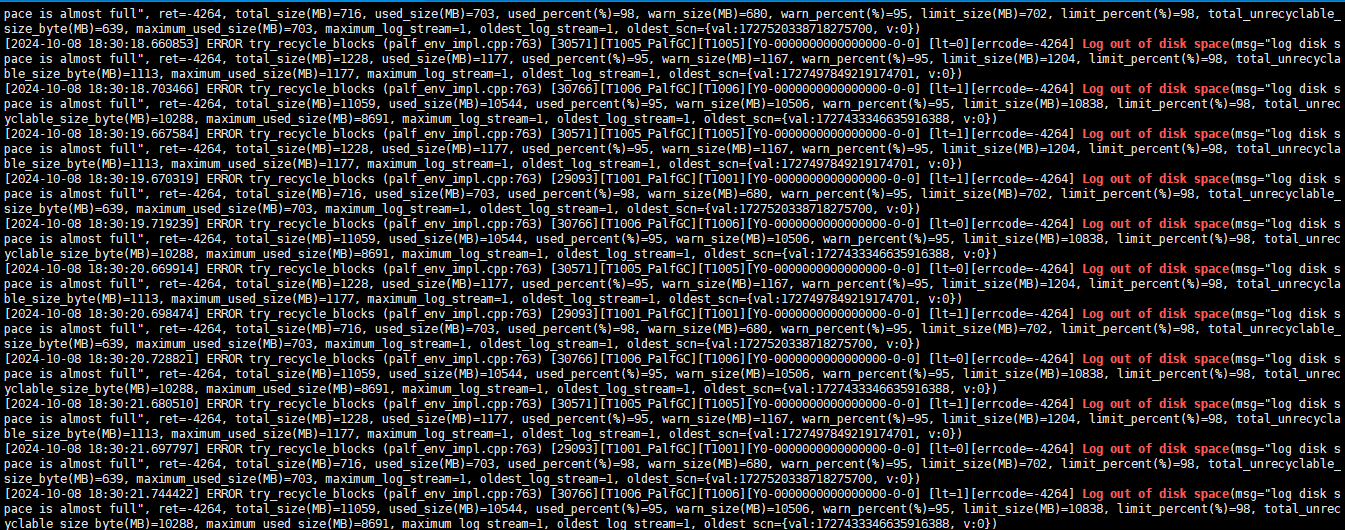
1001租户,1005租户clog空间满了,clog有自动清理机制,不能手动删除
yaml文件中 log_disk_size 先尝试扩容为150G ,再重启试下
修改方式:obd cluster edit-confog 部署名称 --修改参数
tiutiu
#15
收到,我试下。
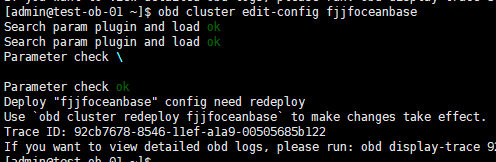
但是启动时用 start命令,它提示我要用reload
tiutiu
#17
reload还是报这个。
我用 obd cluster edit-config 修改的 yaml
然后reload
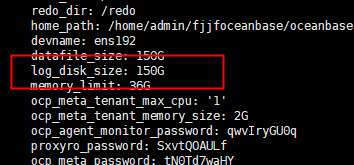
看了下server好像没有生效配置
旭辉
#19
ocp_meta_tenant_log_disk_size 也调整下,按同样的方式调整为10G,再试下
旭辉
#20
如果不生效,带参数启动下
进入ob安装路径 bin目录下
./bin/observer -o “log_disk_size=150G,ocp_meta_tenant_log_disk_size=10G,log_disk_utilization_threshold=95,log_disk_utilization_limit_threshold=98”
或者
./bin/observer -o “log_disk_size=150G,ocp_meta_tenant_log_disk_size=10G,log_disk_utilization_threshold=95,log_disk_utilization_limit_threshold=98”
如果报错libmariadb.so.3: cannot open shared object file修复方式:#将 OceanBase 数据库的 LIB 加到环境变量 LD_LIBRARY_PATH 中,按实际路径替换下面路径即可。echo ‘export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/oceanbase-ce/lib/’ >> ~/.bash_profileexport LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/oceanbase-ce/lib/
旭辉
#22
一样的命令,yaml文件中有这个参数
obd cluster edit-confog 部署名称 --修改参数
旭辉
#25
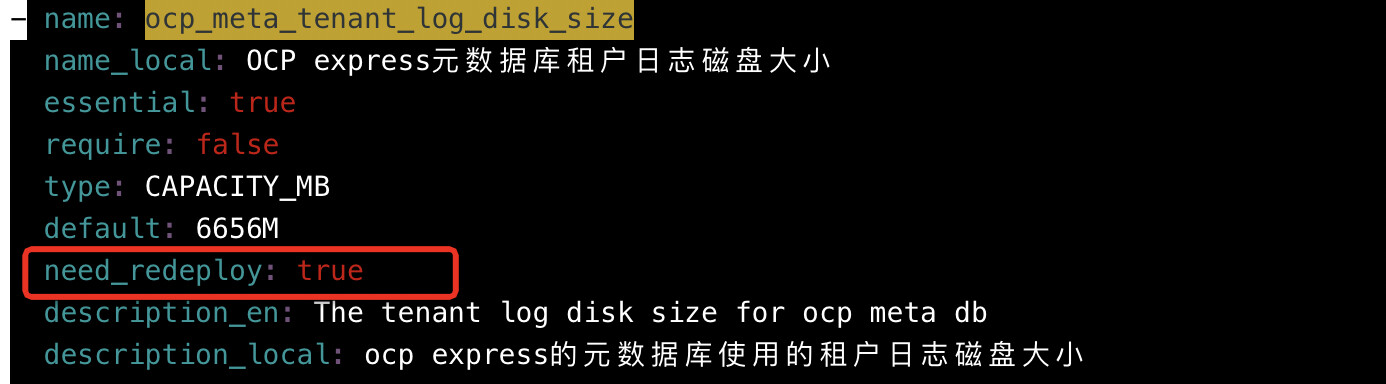
obd修改这个参数ocp_meta_tenant_log_disk_size的确需要重新部署才能生效,如果是新环境建议重新部署吧,如果已有大量数据建议使用带参启动方式
秃蛙
#29
问题已解决:
1)和合并相关导致,数据库实际存储达到阀值。
2)多个租户报日志空间不足,无法回收复用空间,需要等待慢慢回收。
修复方式,启动十几分钟后日志不在打印clog不足问题,集群恢复正常。
./bin/observer -o “memory_limit=36G,log_disk_size=108G,datafile_size=150G,log_disk_utilization_threshold=95,log_disk_utilization_limit_threshold=98”
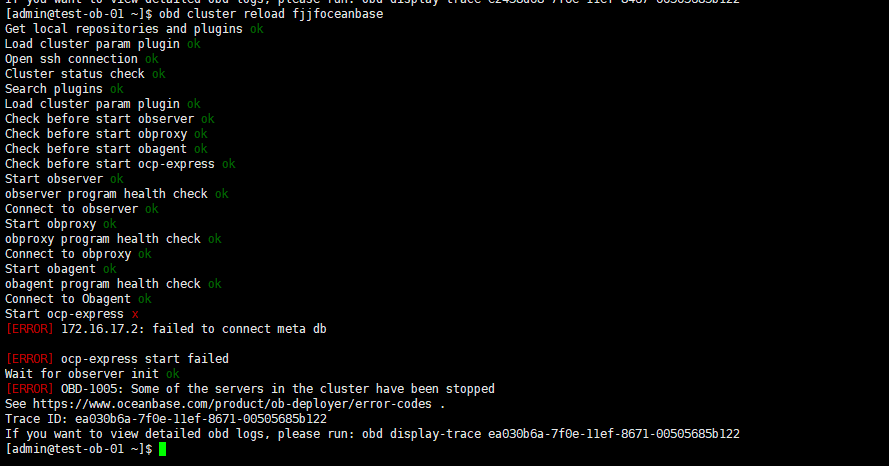
你好 我这边的错误提示是和你第一个图片的内容一致,麻烦问下怎么处理?
淇铭
#31
麻烦重新发帖 具体的版本的信息,日志信息等提供一下