

【 使用环境 】生产环境
【 OB or 其他组件 】obproxy
【 使用版本 】生产环境
【问题描述】32核心64G的obproxy,但是生产环境,一旦稍微有点负载,代理就崩溃了,基本上是一直在自动重启过程中,排查了内存、磁盘、网络、日志、系统资源占用没有看到什么影响到崩溃的。整体负载就百分之零点几,好像每秒TPS超过600以上就会崩溃
【复现路径】重启,按文档、论坛方式调优 均没有用处
【附件及日志】
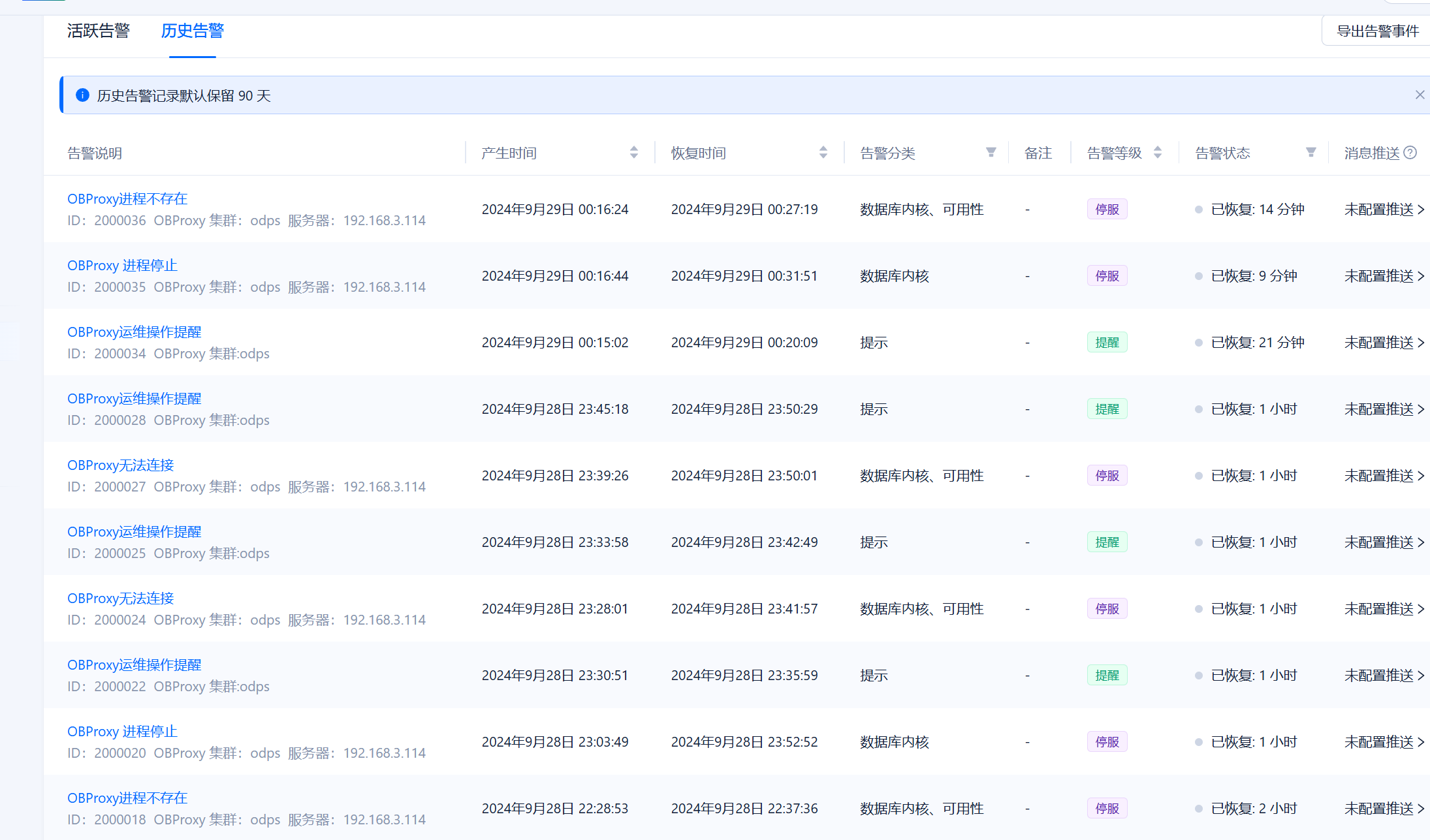
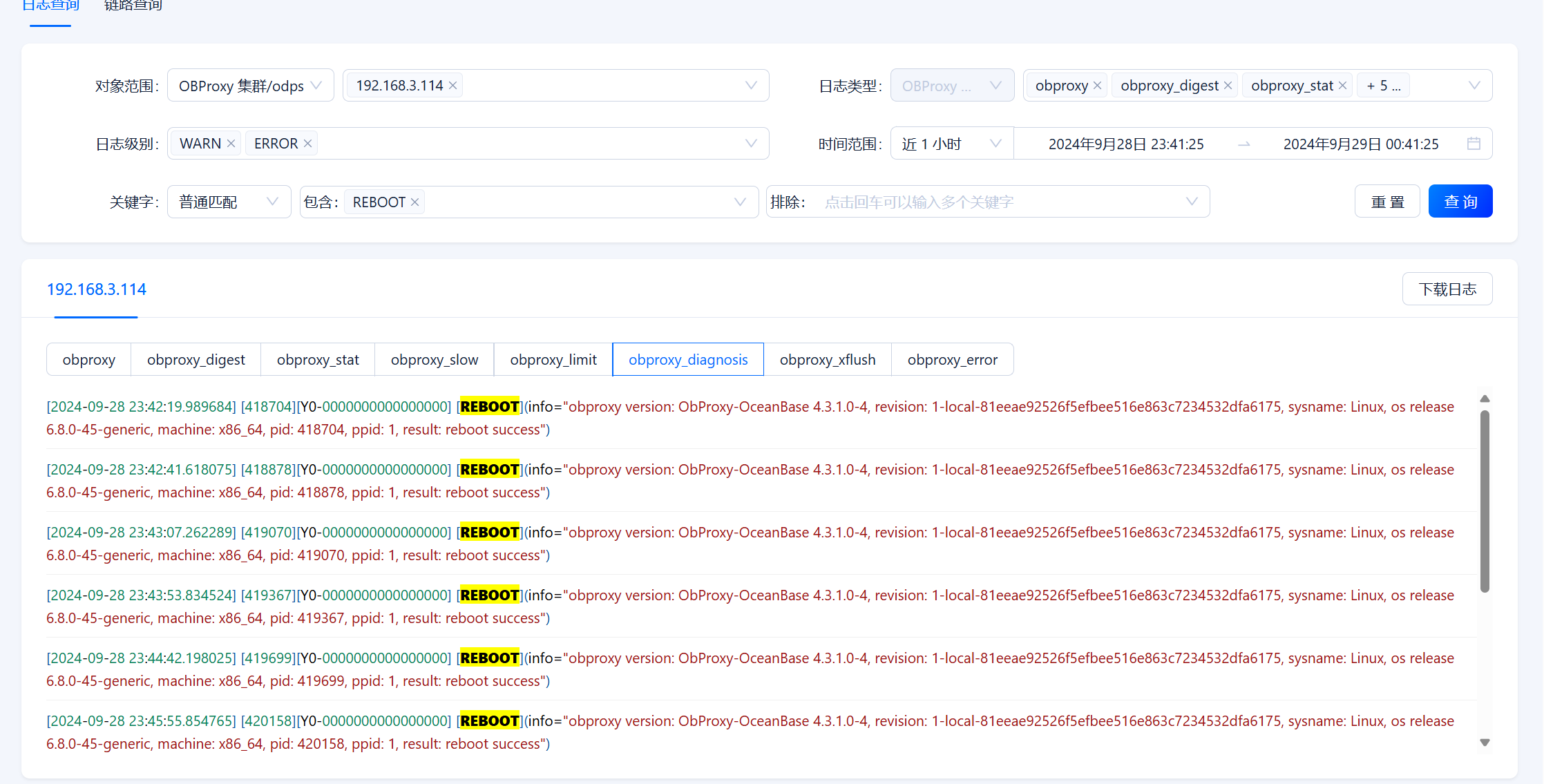
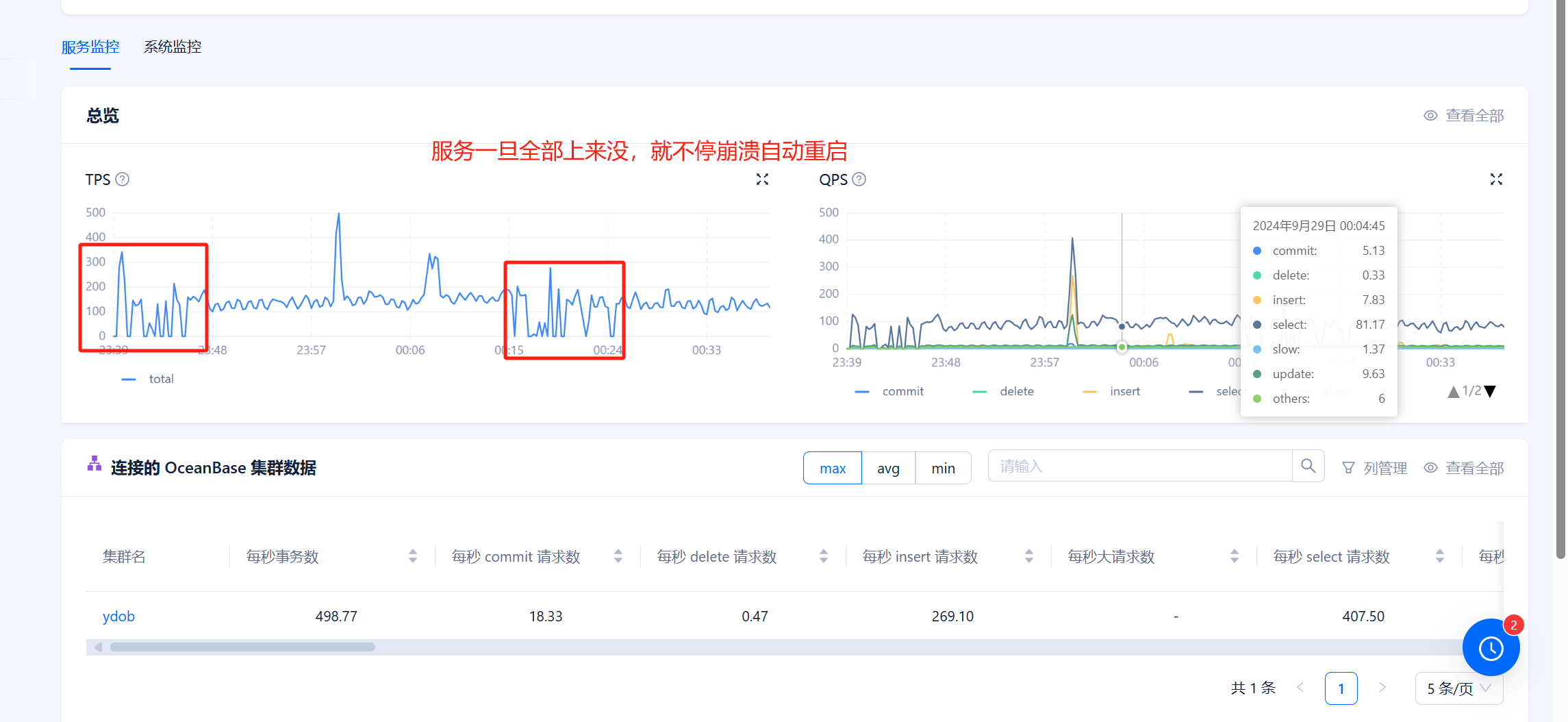
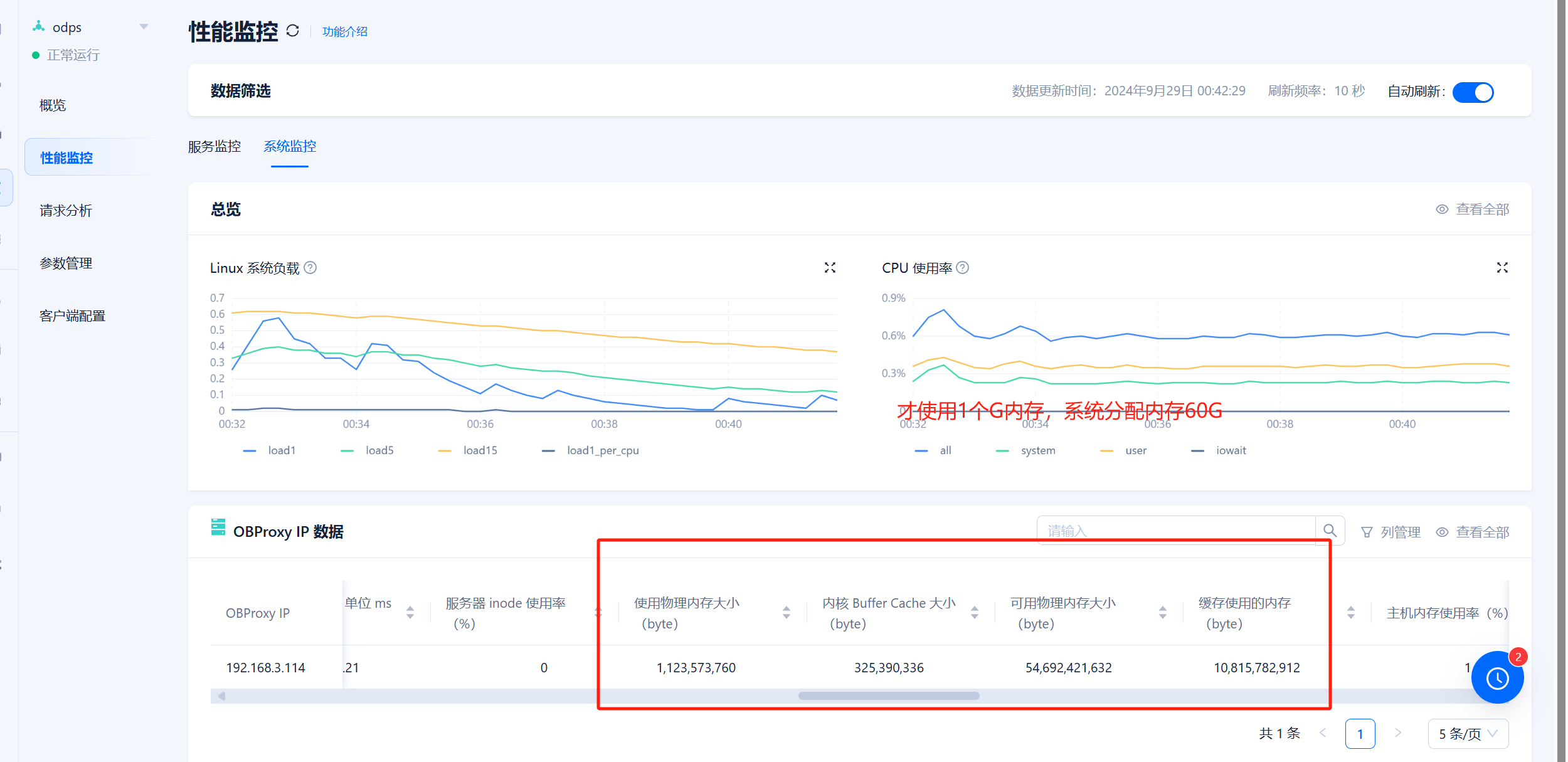

70 个赞
根据您提供的信息,obproxy 在生产环境中频繁崩溃且自动重启,但您已经排查了内存、磁盘、网络、日志和系统资源占用情况,并未发现问题所在。从您提供的日志信息来看,obproxy 的确在频繁重启,并且每次重启都有日志记录重启成功的信息。 [2]
分析与建议
-
内存不足
- 您提到整体负载只有百分之零点几,因此内存不足的可能性较小。不过,尽管如此,还是建议检查
proxy_mem_limited参数的设置。 [1]
ALTER proxyconfig SET proxy_mem_limited = 2G;- 您提到已经尝试将
proxy_mem_limited设置为 50G 和 32G,但问题依旧存在。 [9] 这表明内存不足不是问题的根本原因。
- 您提到整体负载只有百分之零点几,因此内存不足的可能性较小。不过,尽管如此,还是建议检查
-
守护进程异常
-
其他潜在问题
-
系统资源
- 您提供的监控数据显示,系统负载较低,CPU 使用率也很低。 [6]
- 这表明系统资源并不是问题所在,因此需要进一步排查其他方面的问题。
综合建议
- 检查
obproxyd.sh脚本是否正确配置,并确保其能够正常工作。 - 通过查看
obproxy_error.log和obproxy_digest.log来定位具体的 SQL 请求问题。 - 如果问题依然存在,建议联系 OceanBase 的技术支持团队获取进一步的帮助和支持。
综上所述,根据文档库中的信息,您需要进一步排查 obproxy 的日志文件,并确保 obproxyd.sh 脚本能够正常工作。 [2], [3], [8]
详情请参考:
9 个赞
信息太少了。筛选了的话可能会错过某些信息。
digest和error的日志可以download后上传一下。
7 个赞
重新开了一台服务器,一样的32核心64G,我们使用 sysbench --threads=5 --events=0 --time=30 --report-interval=1 --mysql-host=192.168.3.111 --mysql-port=2883 --mysql-user=root@gaosu#ydob --mysql-password= --mysql-db=test --tables=40 --table-size=10000000 oltp_read_only prepare
进行测试,坚持不到10秒钟就会崩溃
7 个赞
根据您提供的日志分析结果,obdiag 对离线日志进行了分析,并未发现明显的错误或异常信息。具体分析结果如下:
日志分析结果
- 状态:PASS
- 文件名:无异常文件
- 错误码:无
- 信息:无
- 计数:无
这表明在您提供的日志文件中,并未发现明显的错误或异常信息。 [1]
日志文件列表
obproxy_diagnosis.logobproxy_error.log
进一步排查建议
-
查看详细日志
- 您可以查看详细的日志文件
/root/ob-dba-agent/obdiag_analyze_pack_20240929023919/result_details.txt,以获取更多的日志信息。 - 运行命令:
cat /root/ob-dba-agent/obdiag_analyze_pack_20240929023919/result_details.txt
- 您可以查看详细的日志文件
-
查看 Trace ID
- 您可以查看具体的 Trace ID 信息:
obdiag display-trace f8a32ebc-7dc8-11ef-8e9c-00163e187a6c
- 您可以查看具体的 Trace ID 信息:
-
检查
obproxy_diagnosis.log和obproxy_error.log- 检查
obproxy_diagnosis.log和obproxy_error.log文件,看是否有具体的错误信息或异常日志。 - 特别关注
obproxy_diagnosis.log中的登录类型日志,如[LOGIN]日志,以及obproxy_error.log中的错误信息。 [1]
- 检查
-
检查系统资源
- 尽管您已经排查了内存、磁盘、网络和系统资源占用情况,但建议再次检查系统资源,特别是 CPU 使用率、磁盘 I/O 等。
- 使用
top或htop命令查看系统资源使用情况。
-
检查配置参数
- 检查 obproxy 的配置参数,特别是
proxy_mem_limited、proxy_thread_pool_size等参数。 - 确保这些参数设置合理,并且符合您的实际需求。
- 检查 obproxy 的配置参数,特别是
综合建议
- 仔细查看详细的日志文件
/root/ob-dba-agent/obdiag_analyze_pack_20240929023919/result_details.txt。 - 使用
obdiag display-trace f8a32ebc-7dc8-11ef-8e9c-00163e187a6c查看具体的 Trace ID 信息。 - 检查
obproxy_diagnosis.log和obproxy_error.log文件,看是否有具体的错误信息或异常日志。 - 再次检查系统资源使用情况,特别是 CPU 使用率、磁盘 I/O 等。
- 检查 obproxy 的配置参数,确保设置合理。
如果您仍然无法解决问题,建议联系 OceanBase 的技术支持团队获取进一步的帮助和支持。
详情请参考:
详情请参考:
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
8 个赞
obproxy 本省崩溃进程停止了 怎么查看日志文件
6 个赞
(gdb) core-file core._home_oceanbase_obproxy_bin_obproxy.0.bf306db9-a7ba-49f2-ac12-8e8b5672f73d.506558.10227200
[New LWP 506598]
[New LWP 506588]
[New LWP 506570]
[New LWP 506563]
[New LWP 506575]
[New LWP 506579]
[New LWP 506571]
[New LWP 506564]
[New LWP 506591]
[New LWP 506600]
[New LWP 506589]
[New LWP 506577]
[New LWP 506565]
[New LWP 506573]
[New LWP 506572]
[New LWP 506582]
[New LWP 506586]
[New LWP 506595]
[New LWP 506581]
[New LWP 506585]
[New LWP 506569]
[New LWP 506583]
[New LWP 506590]
[New LWP 506566]
[New LWP 506568]
[New LWP 506596]
[New LWP 506574]
[New LWP 506599]
[New LWP 506597]
[New LWP 506601]
[New LWP 506584]
[New LWP 506576]
[New LWP 506561]
[New LWP 506580]
[New LWP 506592]
[New LWP 506578]
[New LWP 506560]
[New LWP 506567]
[New LWP 506587]
[New LWP 506558]
[New LWP 506594]
[New LWP 506562]
[New LWP 506593]
Core was generated by `/home/oceanbase/obproxy/bin/obproxy -p 2883 -n odps’.
Program terminated with signal SIGABRT, Aborted.
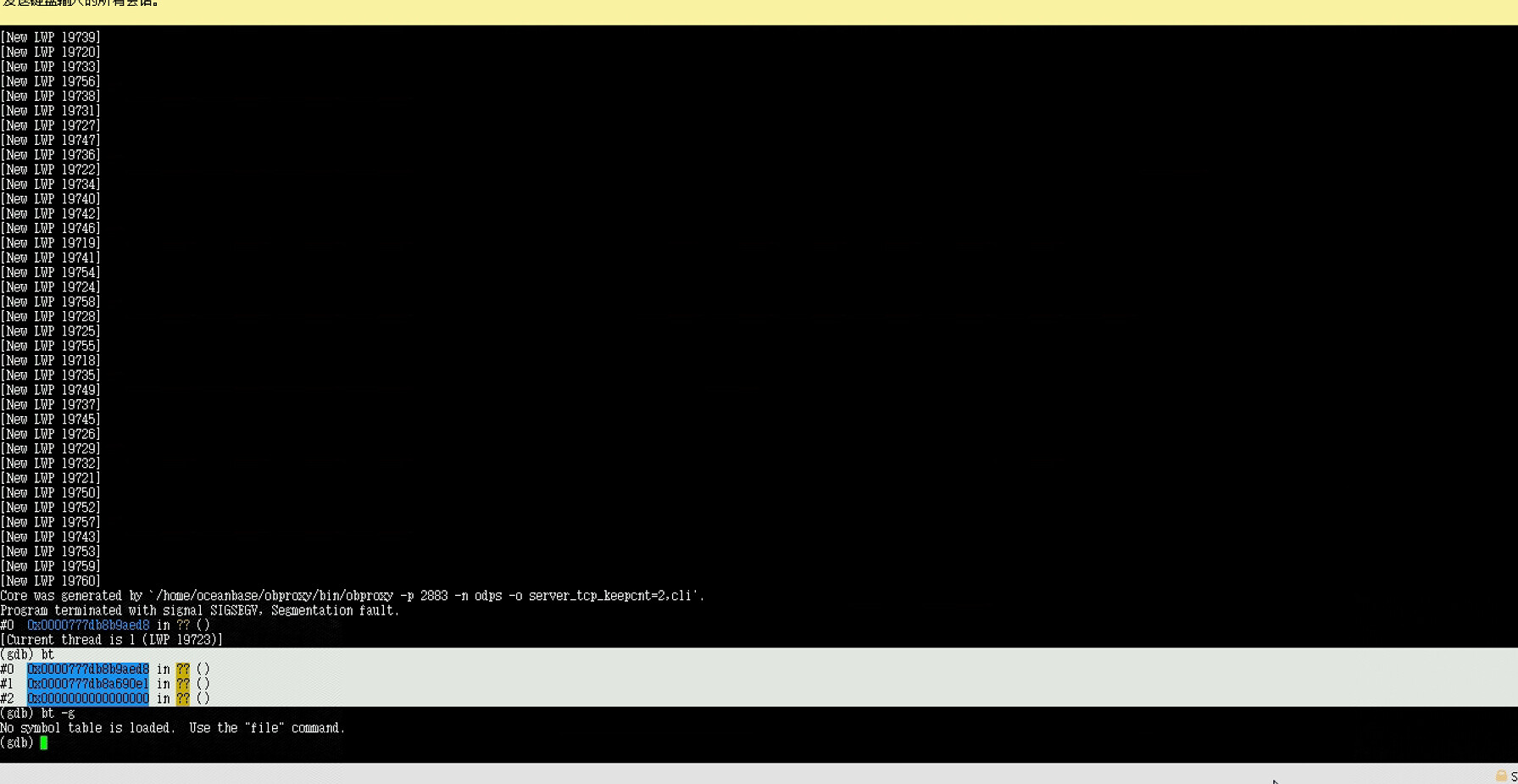
#0 0x00007646d489eb1c in ?? ()
[Current thread is 1 (LWP 506598)]
5 个赞
版本应该有问题,obproxy4.3.1 不行,OCP4.3.1 ObServer4.3.1。obproxy就会崩溃,折腾一个通宵都不行,,最后proxy重新更换4.2.1-11版本,就没问题了
6 个赞
希望配合能找到什么问题
6 个赞
1.请上传一下包含报错时段的obproxy.log,产生的core日志或者core文件
2.发下observer,obproxy的详细版本
3.描述下当前部署架构,obproxy是和ob同服务器吗?
1、obproxy.log日志前面传递了,没有产生core日志,不知道core日志的产生规则是什么,之前崩溃是产生了几个,但是我们想看看最新的,结果怎么崩溃都没有在obproxy服务商尝试core日志。
2、目前:observer4.3.2.1,崩溃的obproxy版本4.3.1.0-4
3、obproxy和observe是不同服务器,在同一个机房,不同的虚拟机上,操作系统ubuntu24.02。
我看了前面发的 obproxy_diagnosis.log 和 obproxy_error.log 文件,是没有有效信息的,如果异常时段的obproxy.log还在的话 麻烦发下 以便于确定根因
我们马上再装一个,然后压测提供日志
OBPROXY_LOG_tsz_192.168.3.108_20240929140545_20240929150545.zip (3.5 MB)
刚新装的,就证明不是配置问题,我们是把代理集群都删除,操作系统还原重装的压测的,坚持了4秒
有几个obproxy节点呢?自动重启的是192.168.3.114节点吗?发的日志是192.168.3.114节点的吗?
另外看下 obproxy根目录下是否生成了 minidump 目录?如果有麻烦打包发下
我们有两个节点,108和114 现在114是已经装成4.2.1在用了,108是没有用起来的,刚刚重新装了4.3.1
OK,发的日志和报错节点对得上就可以下,另外看下 obproxy根目录下是否生成了 minidump 目录?如果有麻烦打包发下