

【 使用环境 】生产环境
【 OB or 其他组件 】oceanbase
【 使用版本 】4.2.1-8BP
【问题描述】
如图,晚上19:00,集群中一台机器,磁盘使用量从77%飙升到了98%
请问这该从什么方面进行排查原因
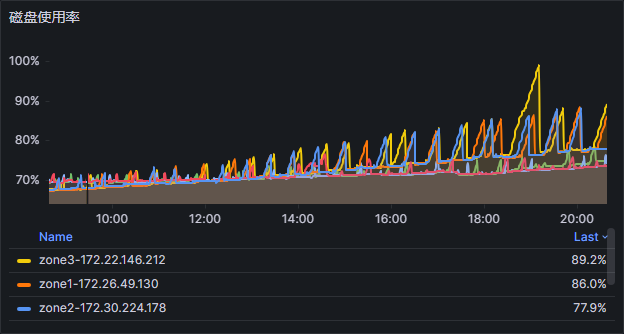
如图为近七天的磁盘使用情况
今天的磁盘使用量波动幅度比较大。原理是啥?
【 使用环境 】生产环境
【 OB or 其他组件 】oceanbase
【 使用版本 】4.2.1-8BP
【问题描述】
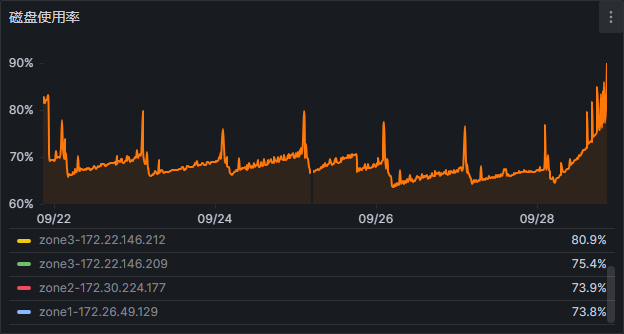
如图,晚上19:00,集群中一台机器,磁盘使用量从77%飙升到了98%
请问这该从什么方面进行排查原因
如图为近七天的磁盘使用情况
今天的磁盘使用量波动幅度比较大。原理是啥?
OCP 里 租户 SQL 诊断看看有没有特别慢的大查询,看看 SQL 是否有排序、分组统计等逻辑。
此外,查一下 DDL 历史看看有没有人发起 大表的 OFFLINE DDL。
此外,SYS 租户下查一下这个 SQL :
select svr_ip,total_count,tmp_file_count,data_block_count,shared_data_block_count,disk_block_count,pending_free_count,free_count,mark_cost_time
from __all_virtual_macro_block_marker_status;
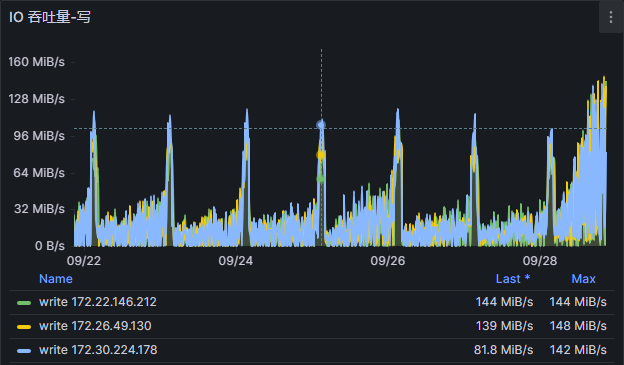
根据io吞吐量指标排查到, io吞吐量特别大。
然查询sql诊断。 发现有一条update语句执行特别多。 整天执行了4.6亿次。 猜测这个业务出现了bug
恩。可以再看一下 租户 的监控【存储与缓存】下的 【MemStore 】监控。看看转储次数是不是很多。
用诊断工具obdiag 2.4.0 版本巡检一下看看看看有没有什么隐藏问题:
obdiag check \
--config db_host=xx.xx.xx.xx \
--config db_port=xxxx \
--config tenant_sys.user=root@sys \
--config tenant_sys.password=*** \
--config obcluster.servers.global.ssh_username=test \
--config obcluster.servers.global.ssh_password=****** \
--config obcluster.servers.global.home_path=/home/admin/oceanbase
--config obcluster.servers.nodes[1].data_dir=/home/admin/oceanbase/store
--config obcluster.servers.nodes[1].redo_dir=/home/admin/oceanbase/store
--config obproxy.servers.nodes[0].ip=xx.xx.xx.1 \
--config obproxy.servers.nodes[1].ip=xx.xx.xx.xx.2 \
--config obproxy.servers.global.ssh_username=test \
--config obproxy.servers.global.ssh_password=****** \
--config obproxy.servers.global.home_path=/home/admin/obproxy
文档:https://www.oceanbase.com/docs/common-obdiag-cn-1000000001326848
这个磁盘使用率是数据盘还是日志盘 或者是在同一个目录?
可以按照楼上老师的方法 分别使用ocp监控数据和obdiag排查下
1、可以查看一段时间sql诊断信息 看看sql执行是否合理
–这里为了展示方便,对 query_sql 做了截断
select /*+ parallel(15) */ sql_id, elapsed_time, trace_id, substr(query_sql, 1, 6)
from oceanbase.gv$ob_sql_audit
where tenant_id = 1
and IS_EXECUTOR_RPC = 0
and request_time > (time_to_usec(now()) - 10000000)
and request_time < time_to_usec(now())
order by elapsed_time desc
limit 10;
2、可以查看冻结的情况
select round(ACTIVE_SPAN/1024/1024/1024,2) as ACTIVE_SPAN_GB , round(FREEZE_TRIGGER/1024/1024/1024,2) as FREEZE_TRIGGER_GB, round(MEMSTORE_USED/1024/1024/1024,2) as MEMSTORE_USED_GB , round(MEMSTORE_LIMIT/1024/1024/1024, 2) as MEMSTORE_LIMIT_GB,FREEZE_CNT from GV$OB_MEMSTORE where tenant_id = 1002;
3、也可以分析服务器上哪个文件目录占用多大
建议先紧急扩容一下磁盘容量,防止合并导致磁盘打满节点故障
查出来原因了吗?可以分享下
有个定时任务的程序bug。 当天一直在执行update语句。 一天对一张仅几十万数据的表。执行了6亿次update