

问题1:在OceanBase数据库中,如何查看租户内的数据量大小,是看数据量,还是磁盘占用量?
问题2:从Oracle迁移到OceanBase租户中后,OCP中显示的数据量比Oracle中显示的数据量小很多,这是为什么?
问题3:明明在OCP中显示的数据量才100G左右,用ob-dumper导出来的文件却有好几百G,这是怎么回事?
1、表的数据量几乎没有办法衡量磁盘占用大小的 你可以看表占用磁盘的大小
某租户下所有表占用磁盘大小
SELECT /*+ query_timeout(30000000) */ a.TENANT_ID, a.DATABASE_NAME,
a.TABLE_NAME, a.TABLE_ID,
sum(case when b.nested_offset = 0 then IFNULL(b.data_block_count+b.index_block_count+b.linked_block_count, 0) * 2 *
1024 * 1024 else IFNULL(b.size, 0) end) /1024.0/1024/1024 as data_size_in_GB
FROM oceanbase.CDB_OB_TABLE_LOCATIONS a inner join oceanbase.__all_virtual_table_mgr b on a.svr_ip = b.svr_ip and a.svr_port=b.svr_port and a.tenant_id = b.tenant_id and a.LS_ID = b.LS_ID and a.TABLET_ID = b.TABLET_ID and a.role =‘LEADER’ and a.tenant_id = ${租户ID}
and b.table_type >= 10 and b.size > 0 group by a.TABLE_ID;
2、这个牵扯到商业版 这里是开源社区 没有办法回答你的问题 你可以咨询商业版哪里 非常抱歉
3、ocp的显示的磁盘大小ob的sstable的数据 是有压缩的 显示的会小
那怎么看租户里的数据量有多大呢
oceanbase.CDB_TABLES 这个表能查看租户下所有的表 这个表可以查看表的行数
如果是查询数据量大小使用CDB_OB_TABLET_REPLICAS;
我的是4.2企业版的,您这个视图查不出来想要的结果
4.2企业版的oracle模式么
- OB 里不同的统计方式有“数据量”、“数据占用量”等多个概念。最紧要的是 “数据占用量”,数据文件里分配空间体现在这个上面。 表数量很多但是数据量不大的时候,二者统计会有些差异。因为有些表的宏块最小粒度就是 2MB,虽然数据量少(填不满宏块),但是数据占用量 是 2MB 。当然宏块下还有微块,微块默认大小是 64KB 。
表的数据量很大的时候,二者差异就相对不大了。
- sys 租户查询sql:
SELECT /*+ read_consistency(weak) query_timeout(1000000000) */ t1.tenant_id, t1.database_name, round(sum(t2.required_size)/1024/1024/1024) required_size_gb, count(*) cnt
FROM oceanbase.CDB_OB_TABLE_LOCATIONS t1
JOIN oceanbase.cdb_ob_tablet_replicas t2 ON (t1.tenant_id=t2.tenant_id and t1.tablet_id=t2.tablet_id AND t1.ls_id=t2.ls_id and t1.svr_ip=t2.svr_ip and t1.SVR_PORT=t2.svr_port )
WHERE t1.tenant_id in (1002) and t1.ROLE='LEADER'
GROUP BY t1.tenant_id, t1.database_name
;
SELECT /*+ read_consistency(weak) query_timeout(1000000000) */ t1.tenant_id, t1.database_name, round(sum(s.size)/1024/1024/1024) data_size_gb, count(*) cnt
FROM oceanbase.CDB_OB_TABLE_LOCATIONS t1
JOIN oceanbase.cdb_ob_tablet_replicas t2 ON (t1.tenant_id=t2.tenant_id and t1.tablet_id=t2.tablet_id AND t1.ls_id=t2.ls_id and t1.svr_ip=t2.svr_ip and t1.SVR_PORT=t2.svr_port )
JOIN oceanbase.GV$OB_SSTABLES s ON (t1.tenant_id=s.tenant_id AND t1.ls_id=s.ls_id AND t1.svr_ip=s.svr_ip and t1.SVR_PORT =s.svr_port AND t1.tablet_id=s.tablet_id)
WHERE t1.tenant_id in (1004) AND t1.ROLE='LEADER' AND s.table_type <> 'MEMTABLE'
GROUP BY t1.tenant_id, t1.database_name
;
- 业务租户查询 SQL:
SELECT /*+ read_consistency(weak) query_timeout(1000000000) */ t1.database_name, round(sum(t2.required_size)/1024/1024/1024) required_size_gb, count(*) cnt
FROM oceanbase.DBA_OB_TABLE_LOCATIONS t1
JOIN oceanbase.DBA_OB_TABLET_REPLICAS t2 ON (t1.tablet_id=t2.tablet_id AND t1.ls_id=t2.ls_id and t1.svr_ip=t2.svr_ip and t1.SVR_PORT=t2.svr_port )
WHERE t1.ROLE='LEADER'
GROUP BY t1.database_name
;
SELECT /*+ read_consistency(weak) query_timeout(1000000000) */t1.database_name, round(sum(s.size)/1024/1024/1024,2) data_size_gb, count(*) cnt
FROM oceanbase.DBA_OB_TABLE_LOCATIONS t1
JOIN oceanbase.DBA_OB_TABLET_REPLICAS t2 ON (t1.tablet_id=t2.tablet_id AND t1.ls_id=t2.ls_id and t1.svr_ip=t2.svr_ip and t1.SVR_PORT=t2.svr_port )
JOIN oceanbase.GV$OB_SSTABLES s ON (t1.ls_id=s.ls_id AND t1.svr_ip=s.svr_ip and t1.SVR_PORT =s.svr_port AND t1.tablet_id=s.tablet_id)
WHERE t1.ROLE IN ('LEADER','FOLLOWER') AND s.table_type <> 'MEMTABLE'
GROUP BY t1.database_name WITH ROLLUP
;
为了防止数据文件内部空间不够,紧盯 OCP 里【集群】-【资源管理】里的数据文件使用率,这个最贴近实际。
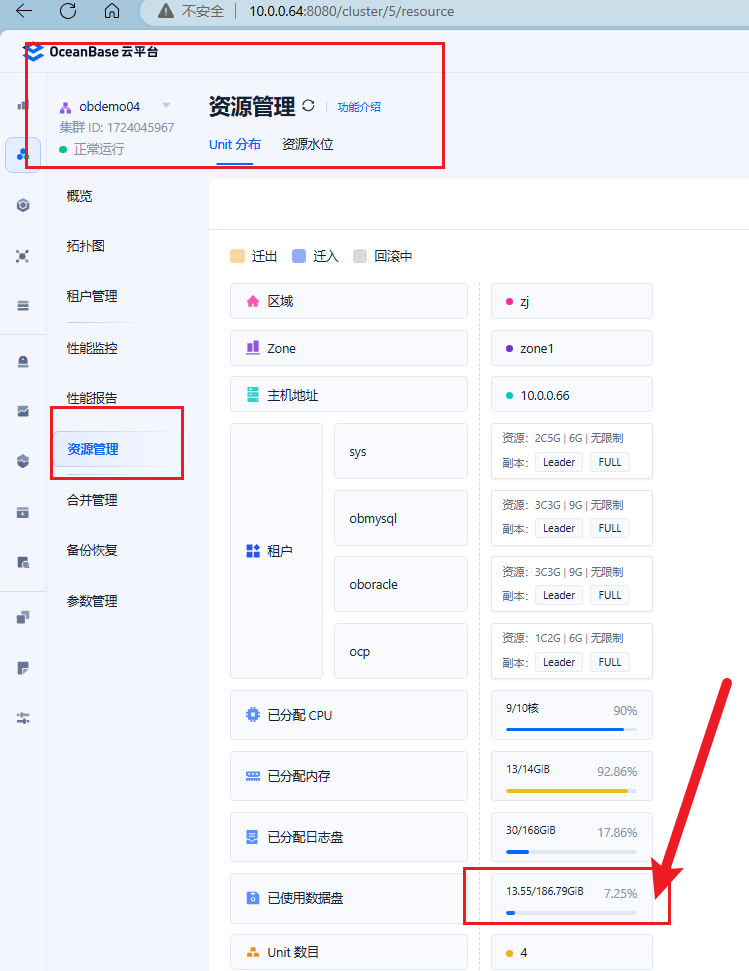
-
OB 里数据会有压缩。来自两个技术:一是数据分层压缩。有 lz4和 zstd ;二是数据编码。将来用了列存后,数据压缩效果更大。
-
ob-dumper导出来的数据就相当于“解压缩”后的文本数据,变大是肯定的。这也进一步证明 OB 的数据是有压缩的,且压缩效果还不错。
更多原理阅读: OB 空间分配分析 (qq.com)
1 个赞
是的
obdumper导出很快,但是obloader导入要慢的多,是这个压缩功能导致的吗?
社区这边只有mysql模式与oracle还是存在差异的
建议你通过以下方式寻求帮助:
1.如你所在的企业客户已签署OceanBase企业版销售合同,请你联系客户经理;
2.如你所在的企业客户尚未签署OceanBase企业版销售合同,你可通过OceanBase官网商务咨询页面留下你的联系方式,OceanBase企业版的业务顾问会在一个工作日内与你联系。
OceanBase官网商务咨询
obdumper 导出的时候是查询,一般不用怎么优化。但是 obloader导入的时候,快不快就跟 集群环境、参数配置、表结构有密切关系。
一般经验,obloader 导入都有优化空间。
一般最好用的提升导入速度的方法是什么?
请问这个“sys租户查询sql”和“业务租户查询sql”里的第二条sql,查出的数据占用量有什么区别呢?为什么同一个数据库,用两条sql查出来的数据占用量相差很大?