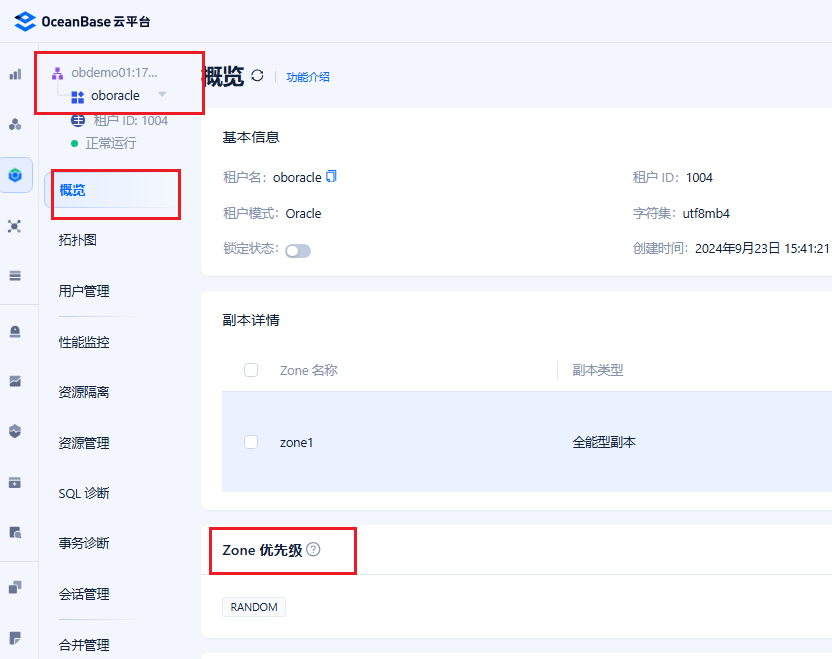
【 使用环境 】测试环境1-1-1 集群模式。没有 设置读写分离,用的是OB默认的强一致性读 。
不过,我们通过 OCP 的 SQL诊断 功能发现:
INSERT INTO 某分区表 这个 SQL 在 集群 的 3个 Zone 中都有被执行(都能搜索到)。
作为对比,我们也检查了一下非分区表,发现 INSERT INTO 某非分区表 的 SQL 就只有在该表主副本所在的 Zone 上被执行。
至于这个 某分区表,它有2000个左右的分区,我们通过将该表加入一个表组( SHARDING = 'NONE' ),从而让该表的所有表分区都集中在同一个 Zone 上。
理论上,在强一致性的前提下,该表的 读写 都应该由 主副本所在的 Zone 来执行才对。
1 个赞
估计租户的 zone优先级(primary_zone)是 random 或者 zone1,zone2,zone3 这种。
当租户的primary_zone 是多个zone 的时候,租户的表的分区会自动做负载均衡。其中分区表的多个分区会分布在不同节点上,所以 insert sql 会出现在多个节点上。
关于这个 primary_zone 应该设置为单zone 还是多zone,不同客户有不同的考虑点。
一种观点是 业务刚迁移到 ob上来,性能问题比较多(并不全是ob的问题,sql自身问题更多),先将 primary_zone 设置为 单zone,这样使用起来跟单机效果一样。此时可以专注优化慢sql。这种是比较贴切实际的变通用法。
第二种观点还有个变通用法就是将 odp 版本升级到 4.2.2 以上最新版本。 enable_transaction_internal_routing-V4.2.2-OceanBase 数据库代理文档-分布式数据库使用文档
如果租户的zone 优先级不是上面猜测的这种而是单zone,那就是事务路由问题。 insert into sql 在事务中路由到哪个节点默认是跟开启事务的第一个 sql 有关(前提是odp 版本低于4.2.1 )。
表组的用途不是说把一个分区表的所有分区几种在一起,而是在租户的zone优先级是多个zone 的时候,让表组中的同号分区的同类型副本(主或备)在同一个节点上,不同分区的同类副本是会分布在不同节点上。
3 个赞
shiyh
2024 年9 月 26 日 06:53
#4
赞同obpilot的说法,感觉是primary zone设置成了多zone的原因。 楼主对tablegroup的理解不太准确 。
1 个赞
旭辉
2024 年9 月 26 日 09:34
#5
obpilot老师的分析你可以参考下,大概率是这个情况,可以确认下:
–查下租户zone的优先级设置
–查下分区表leader的分布情况
@obpilot @旭辉 @shiyh
我们的 Primary Zone 确实是 RANDOM 。
但是,我们的表组设置是 SHARDING = 'NONE',这种设置是不需要考虑分区表和非分区表的,什么表都可以往里面添加。都会集中在同一个 Zone。
SELECT
zone, tablegroup_name, COUNT( table_name ) AS table_count
FROM
oceanbase.DBA_OB_TABLE_LOCATIONS
WHERE
database_name IN ( '数据库名称')
AND role = 'LEADER'
AND table_type = 'USER TABLE'
AND table_name = '分区表名称'
GROUP BY
database_name, zone;
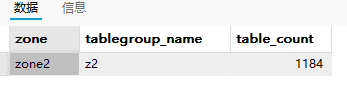
我们查询这个表的主副本分布,也能看到它的所有表分区的主副本全部集中在 zone2 这个节点上。
SELECT
zone, table_name, COUNT(*) AS table_count
FROM
oceanbase.DBA_OB_TABLE_LOCATIONS
WHERE
database_name IN ( '数据库名称')
AND role = 'LEADER'
AND table_type = 'USER TABLE'
AND tablegroup_name = '表组名称'
GROUP BY
database_name, zone, table_name;
我们直接查询这个表组中所有表分区的主副本分布,也可以看到,全部都集中在 zone2 。
旭辉
2024 年9 月 26 日 11:03
#8
INSERT INTO 某分区表 这个 SQL 在 集群 的 3个 Zone 中都有被执行(都能搜索到)
这个你是怎么搜索的?gv$ob_sql_audit 吗?
是通过 OCP 的 【SQL诊断】 界面查询出来的。OBServer 依次切换3个zone的 IP,都能搜索出执行的SQL记录数据。
如果是非分区表,就只有在下拉框 OBServer 中选择其主副本所在的 Zone IP 才能被搜索出来。
SELECT * FROM oceanbase.gv$ob_sql_audit
WHERE QUERY_SQL LIKE 'INSERT INTO `数据表名`%'
AND SVR_IP = '每个Zone IP'
LIMIT 10;
我通过 gv$ob_sql_audit 也是能够搜索出来的。
@旭辉
很奇怪,我用 oceanbase.gv$ob_sql_audit 查询另一个分区表(简称 表2,也加入了一个 SHARDING = 'NONE' 的表组 ),又只能从其主副本所在的 Zone 中查询到记录。
我能想到唯一的区别是, 表1(即 在所有zone都能查询到执行记录的这个分区表) 的 INSERT INTO 会和 另外一个分区表 的 INSERT INTO 是在同一个事务 里完成的,不过这两个分区表都在同一个表组 中,分区键和分区方式也完全不一样,不至于出现这种情况才对。
这里表分组 的使用目的理解不对。
如果只是单纯的想让所有分区主副本在一个zone,设置 primary_zone 为 单个 zone 就是了,不要用表分组。
表分组误用最极端的形式就是所有表放到一个表分组里了,那还不如设置 primary_zone 。
我不是想让所有表的主副本都在一个 Zone,而是根据业务划分,分成了几个表组。
最终实现的效果就是:
表组1 全部位于 Zone 1
表组2 全部位于 Zone 2
表组3 全部位于 Zone 3
其他表(没有业务关联 或 负载极低) 让 OB 自行随机负载均衡
这样做,既避免了业务上跨Zone的分布式处理开销,又起到了负载均衡的作用。
这比使用单一的 Primary Zone —— 所有写操作热点全部集中在一个 Zone,效果要好多了。
我们本来就是按照业务关联来规划表组的,用法没有问题。
只不过 我们疑惑的 就是这个分区表,明明主副本都聚集在同一个Zone,却在其他2个Zone上也看到了它相关的读写SQL执行。按照 OB 官方的文档描述,这都解释不通。
恩,你这个目标效果是合理的对的。
你的表分组尽量不要把非分区表跟分区表放在一起,虽然技术上是可以。那个有点别扭。强用也行。
假设这一步不是问题。当主副本位置已经符合你的预期了。
事务里的insert sql 实际还是有可能不在那个表的主副本所在位置。前面说了,早期的版本(odp 4.2.1以及以前版本)路由下,事务路由是跟随第一条开启事务的sql 的。
你看看你的 odp 的版本。
然后要在 gv$ob_sql_audit里把这个事务的所有 sql 都抓出来 (同一个 tx_id ),分析看看。
SELECT usec_to_time(request_time) req_time,svr_ip, client_ip, sid, tx_id, tenant_name,user_name,sql_id,query_sql,ret_code,affected_rows+return_rows total_rows,trace_id,plan_id
FROM oceanbase.gv$ob_sql_audit
WHERE 1=1 -- AND client_ip='0.0.0.0'
AND tenant_id = 1002
AND tx_id=29291526
AND is_executor_rpc=0
ORDER BY request_time DESC LIMIT 100;
从事务第一条sql看起,看实际执行节点 svr_ip 和 sql 类型 (plan_type) 去分析。
我这个分区表的 INSERT INTO 语句 是和另一个分区表的 INSERT INTO 语句在一个事务里面。
这个事务里面,就只有这两个表 的 插入语句,而且这两个表都在同一个表组 里面。
OB 版本:OceanBase_CE_V4.3.2.1 ( OceanBase_CE_V4.2.1.7 也有类似的情况 )
ODP 版本:是最新的 4.3.1 ( OceanBase_CE_V4.2.1.7 用的是 4.2.3 )
JDBC 连接字符串:jdbc:mysql://proxy地址:2883/db_name?useUnicode=true&allowMultiQueries=true&rewriteBatchedStatements=true
表结构有二级分区,一级 LIST,二级 HASH。
两个分区表的所有表分区的所有主副本 都在 zone 2。
我查了一下SQL审计,部分分区表的 INSERT INTO 语句,其 EVENT 属性显示为 das wait remote response 。
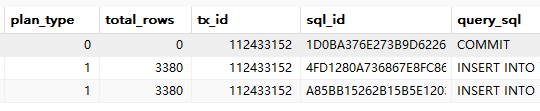
执行你给的SQL语句,结果如下
5、 不看 event ,看 svr_ip, plan_type 字段。 svr_ip 是 sql 执行节点,plan_type 表示 sql 执行计划类型(1:本地;2:远程;3:分布式)。where 条件:is_executor_rpc=0
其实从这个图的 sid 是一样的,也看出来了这 4 条 sql 是在同一个节点执行的。
但是,我查的这个IP,它并不是主副本所在的 Zone。
我重新找了一个,sid、svr_ip 都是相同的。plan_type 如下所示: