【 使用环境 】生产环境
【 OB or 其他组件 】 oceanbase
【 使用版本 】4.3.2.1
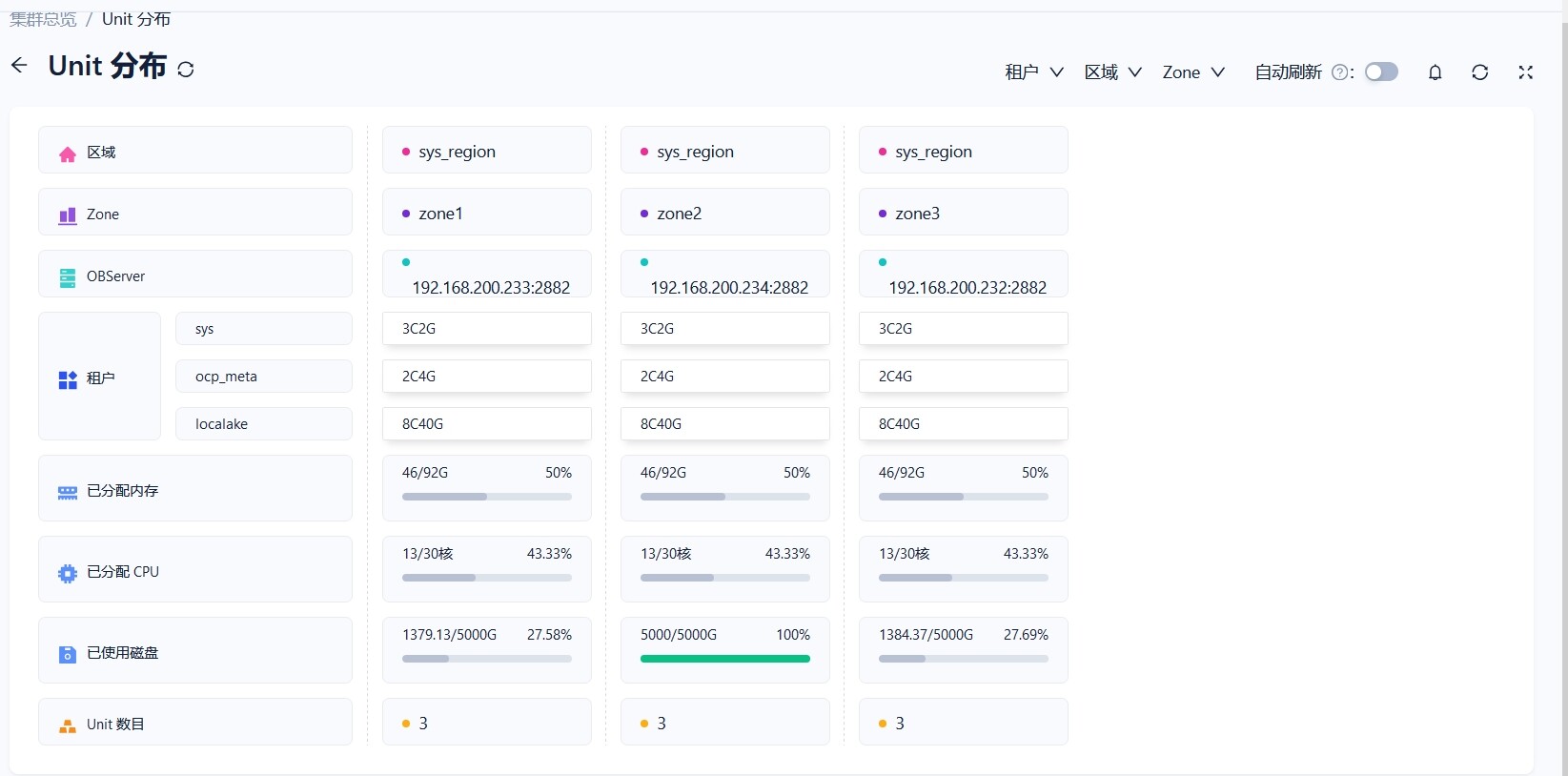
【问题描述】3台机器部署集群,运行一段时间后,单台机器磁盘使用量异常,服务停止。每台机器的数据文件划分了最大2T。
【复现路径】问题出现前后相关操作
【附件及日志】
【 使用环境 】生产环境
【 OB or 其他组件 】 oceanbase
【 使用版本 】4.3.2.1
【问题描述】3台机器部署集群,运行一段时间后,单台机器磁盘使用量异常,服务停止。每台机器的数据文件划分了最大2T。
【复现路径】问题出现前后相关操作
【附件及日志】
查一下集群的datafile_disk_percentage参数和datafile_size当前值
这里看日志报错4184 磁盘满了,但是看你上面的磁盘大小不一致可能是其他原因或者bug导致。麻烦把集群架构,集群信息租户信息也发出来,租户的unit分布。如果是obd搭建的yaml文件也发出来一份
234 这个节点的空间使用异常,内部空间满了。
可以先重启这个 OB 节点看看。
昨天重启过了,跑了一段时间,今天早上登陆上去看到服务又停止了。关键问题,这个集群已经重新部署过一次了,之前也是这个问题,单个节点磁盘爆满。目前运行的集群是重装之后的,还是单个节点异常
有没有尝试过更换台机器呢,重装还屡次出问题可能是硬件缘故了
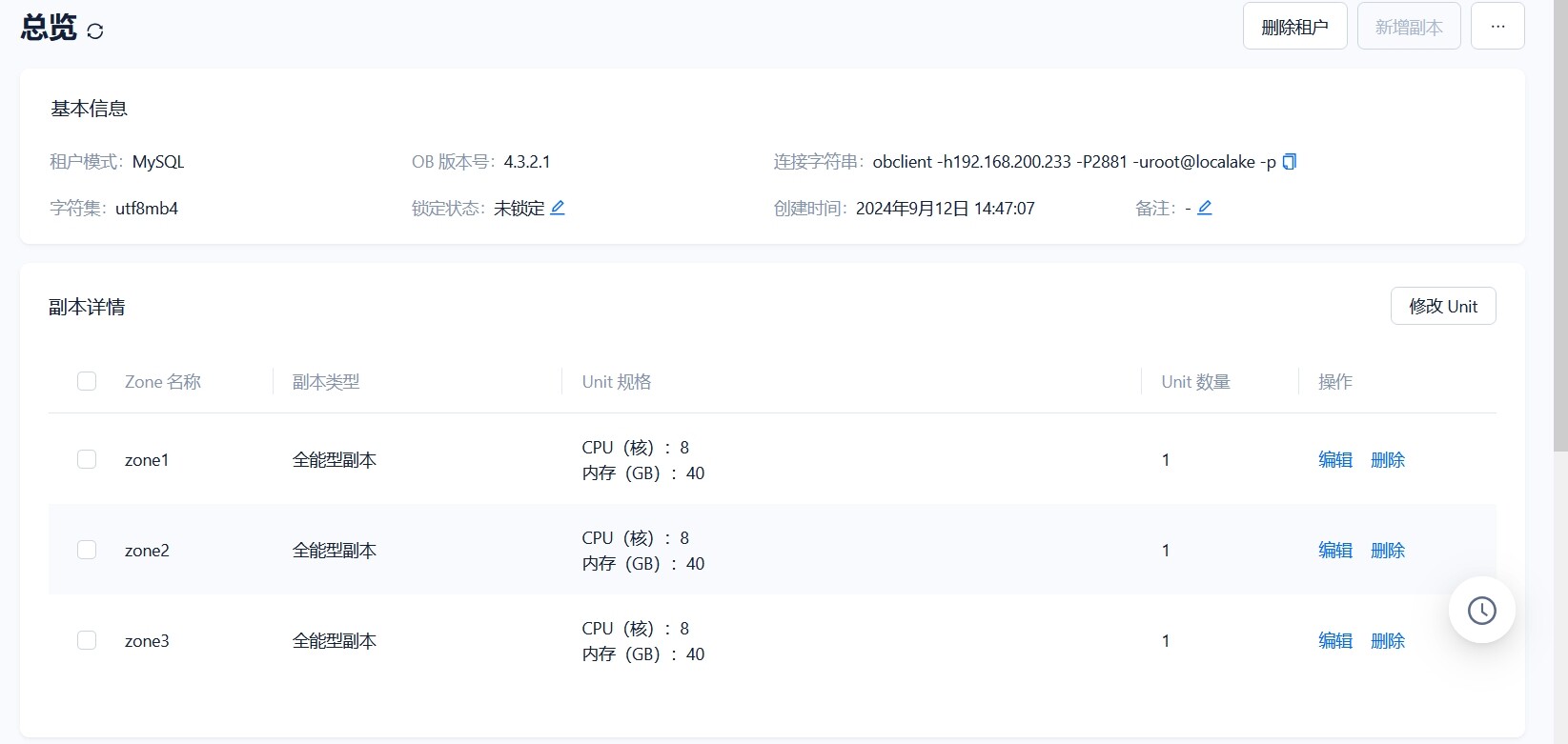
看datafile_size 参数设置2T 实际看OCP上展示的是500G,麻烦看下
show parameters like ‘%datafile%’;
show parameters like ‘%log_disk_size%’;
select * from oceanbase.__all_virtual_disk_stat;
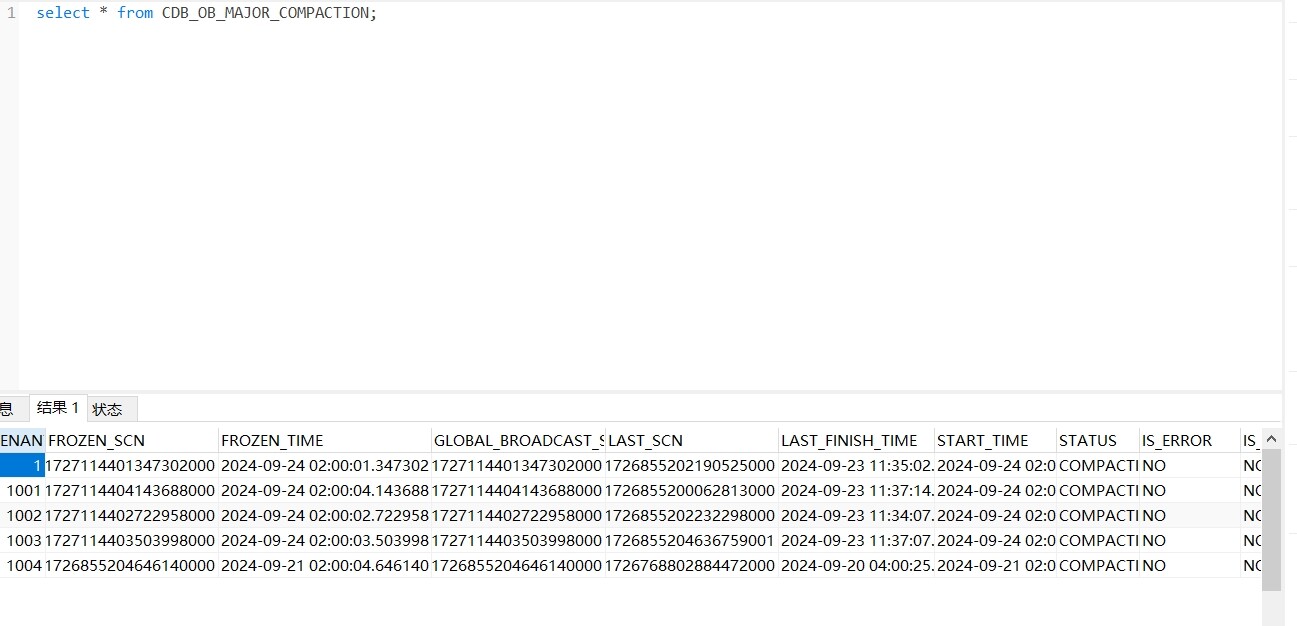
可能是合并问题导致的麻烦查一下该sql 截图看看结果
select * from CDB_OB_MAJOR_COMPACTION;
业务租户的id
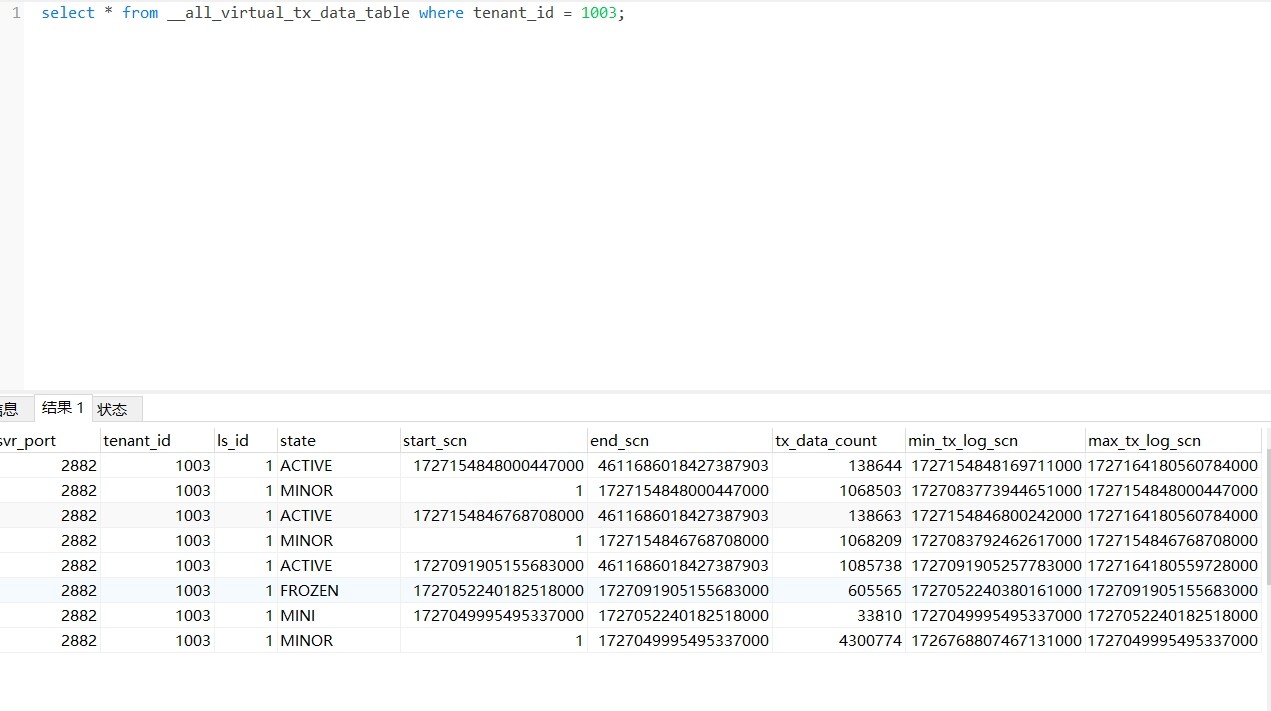
select * from __all_virtual_tx_data_table where tenant_id = xxx;
应该是1004租户吧 1003是1004的meta元租户的ID。
select * from __all_tenant; 可以查看下。
select /*+ query_timeout(30000000) */ a.TENANT_ID, a.DATABASE_NAME,
a.TABLE_NAME, a.TABLE_ID,
sum(
case
when
b.nested_offset = 0 then
IFNULL(b.data_block_count+b.index_block_count+b.linked_block_count, 0) * 2 * 1024 * 1024
else
IFNULL(b.size, 0)
end
) /1024.0/1024/1024 as data_size_in_GB
from CDB_OB_TABLE_LOCATIONS a inner join __all_virtual_table_mgr b
on a.svr_ip = b.svr_ip and a.svr_port=b.svr_port and a.tenant_id =
b.tenant_id and a.LS_ID = b.LS_ID and a.TABLET_ID = b.TABLET_ID
and a.tenant_id = 1004 and a.svr_ip = ‘192.168.200.234’
and b.table_type >= 10 and b.size > 0 group by a.TABLE_ID;
帮忙查询下该表
select * from CDB_OB_TABLET_REPLICAS where COMPACTION_SCN<GLOBAL_BRO…and tenant_id=1004;
在RS leader所在的observer上去查看日志,基于’replica not merged’关键字

有没有在单个节点徒增数据量期间执行建索引?