基本上排查
1、租户调度是否异常
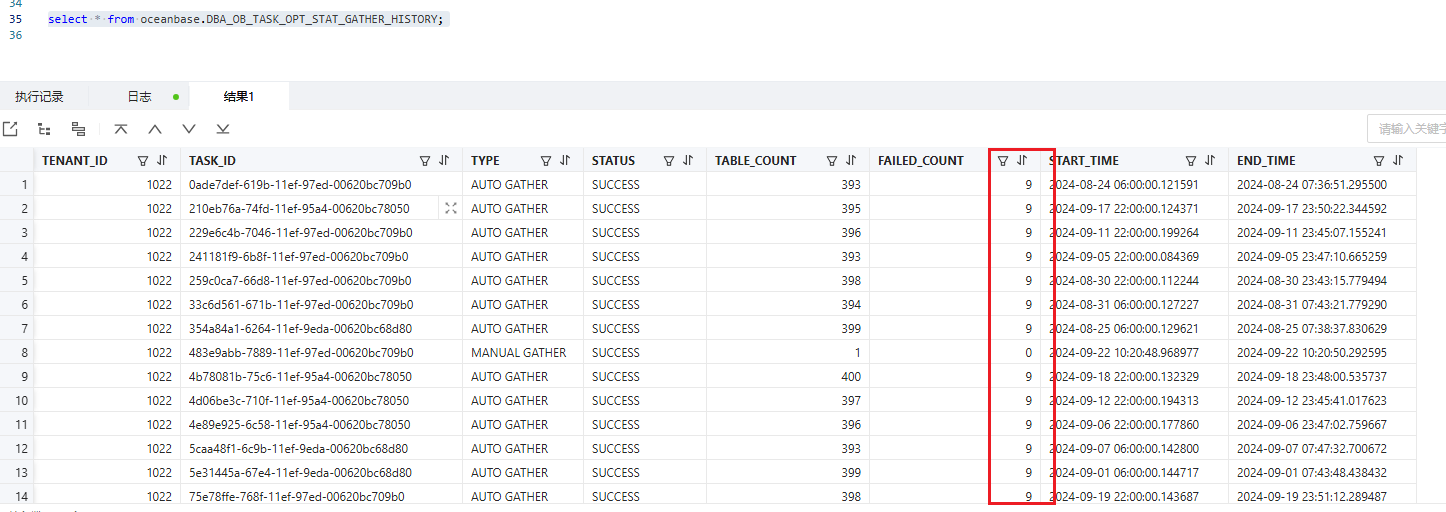
2、自动收集任务调度是否有问题
– sys租户,获取的所有租户信息,可以指定租户查询(推荐)
SELECT t_opt.tenant_id,
t_opt.task_id,
task_opt.start_time AS task_start_time,
task_opt.end_time AS task_end_time,
d.database_name,
t.table_name,
t_opt.table_id,
t_opt.ret_code,
t_opt.start_time,
t_opt.end_time,
t_opt.memory_used,
t_opt.stat_refresh_failed_list,
t_opt.properties
FROM (
SELECT tenant_id,
task_id,
start_time,
end_time,
table_count
FROM oceanbase.__all_virtual_task_opt_stat_gather_history
WHERE type = 1
– AND tenant_id = {tenant_id}
AND start_time > date_sub(Now(), interval 1 day)) task_opt
JOIN oceanbase.__all_virtual_table_opt_stat_gather_history t_opt
JOIN oceanbase.__all_virtual_table t
JOIN oceanbase.__all_virtual_database d
WHERE t_opt.ret_code != 0
AND task_opt.task_id = t_opt.task_id
AND task_opt.tenant_id = t_opt.tenant_id
AND t_opt.tenant_id = t.tenant_id
AND t_opt.table_id = t.table_id
AND t.tenant_id = d.tenant_id
AND t.database_id = d.database_id
AND t_opt.table_id > 200000;
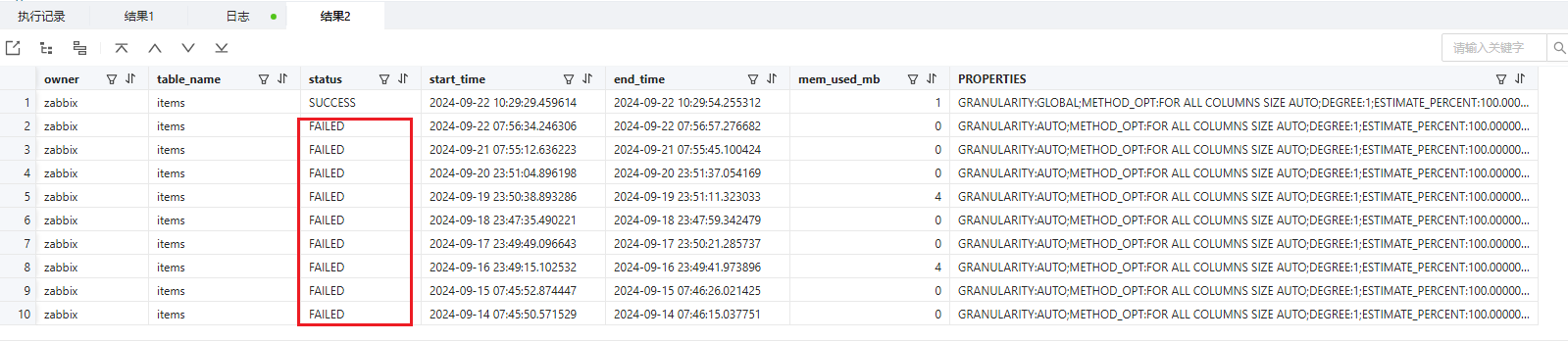
3、如果租户调度没有问题基本上都是根据__all_virtual_table_opt_stat_gather_history的status的状态来判断是否有问题
例如:自动收集卡在超大表运维手段
使用如下SQL检查当前大表过去一段时间的收集情况,观察是否都是一个收集耗时长的过程,如果查询sys租户的 ret_code 字段非0表示收集失败,查询业务租户视图的 status 字段非 ‘SUCCESS’ 或者 NULL 表示收集失败
– sys租户
SELECT *
FROM oceanbase.__all_virtual_table_opt_stat_gather_history
WHERE table_id = {table_id}
ORDER BY start_time;
– MySQL业务租户
SELECT *
FROM oceanbase.dba_ob_table_opt_stat_gather_history
WHERE table_name = ‘{table_name}’
ORDER BY start_time;
4、确实没有特别细粒度的排查信息