【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】
【 使用版本 】4.2.1.0
【问题描述】清晰明确描述问题
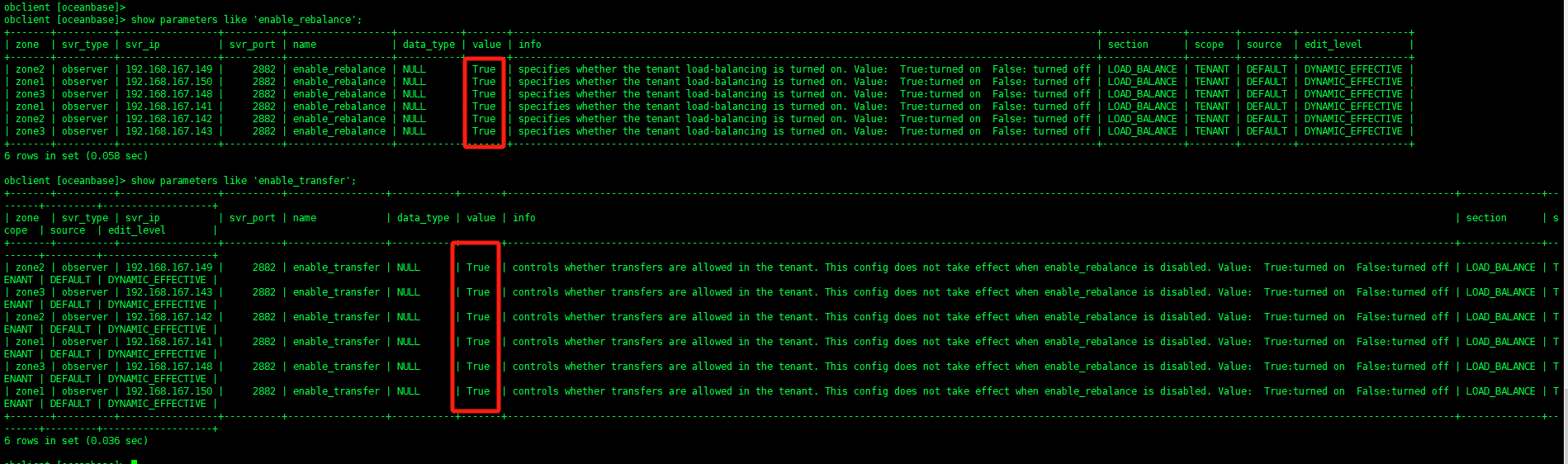
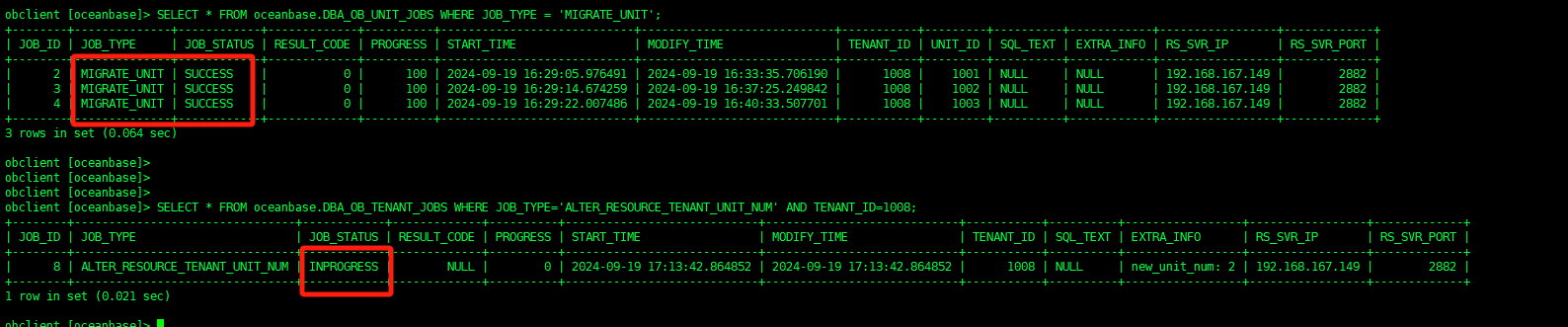
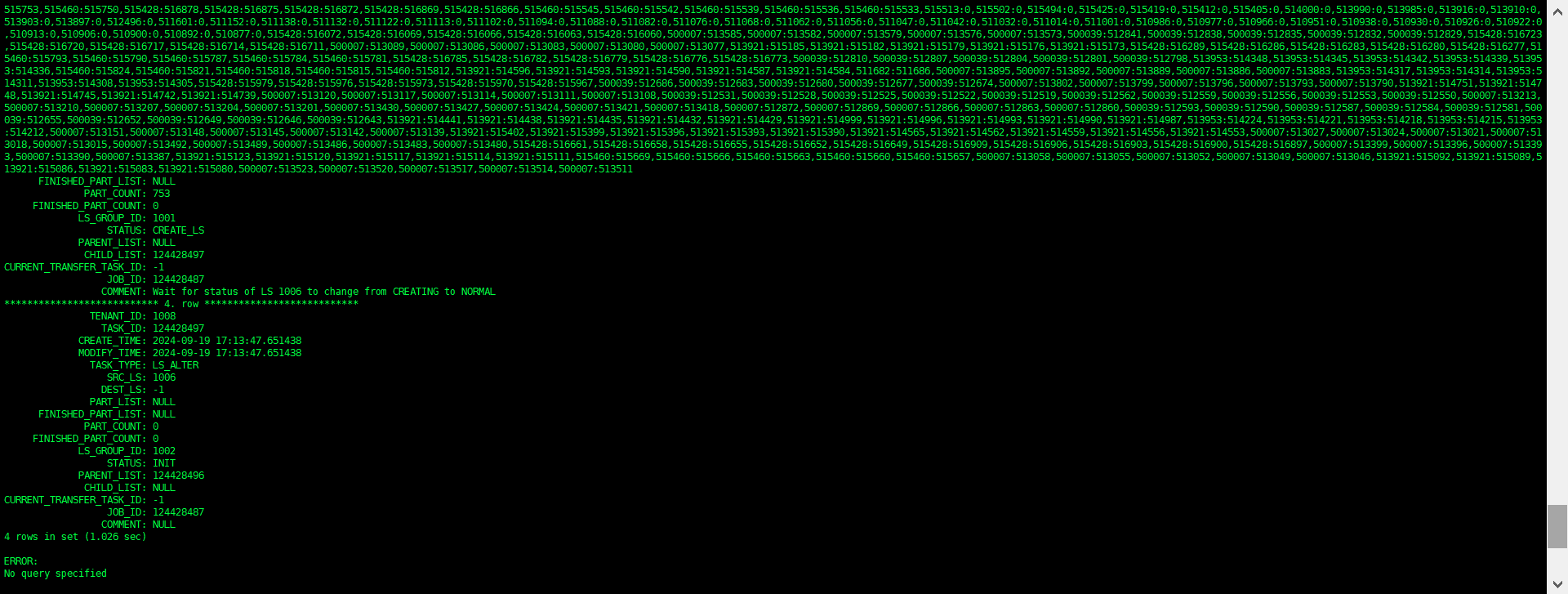
我的架构是1-1-1,每个zone加了个节点变成2-2-2,然后对一个业务租户调整unit number 从1 调成2,但是现在一直卡在这个状态,14个小时了,还没有结束,请问我该怎么查找这个问题的原因,相关信息如下截图:
查看正在执行的transfer任务
select * From CDB_OB_TRANSFER_TASKS \G;
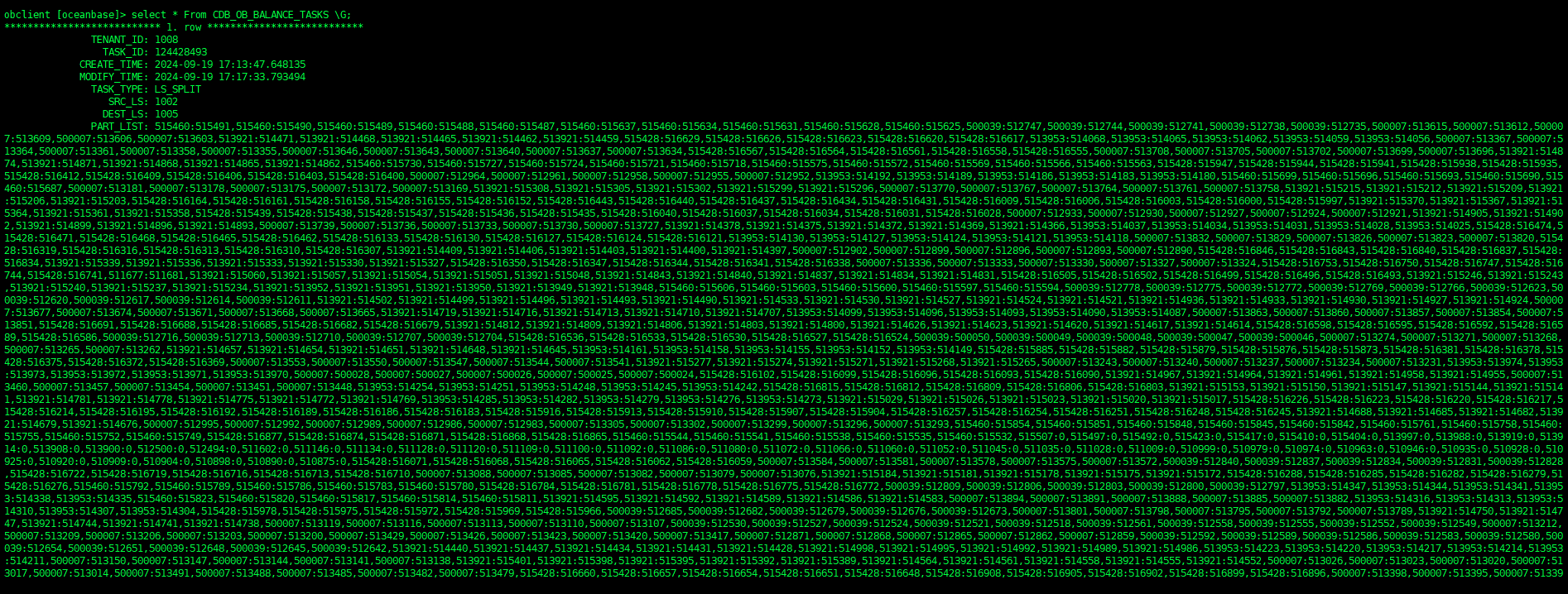
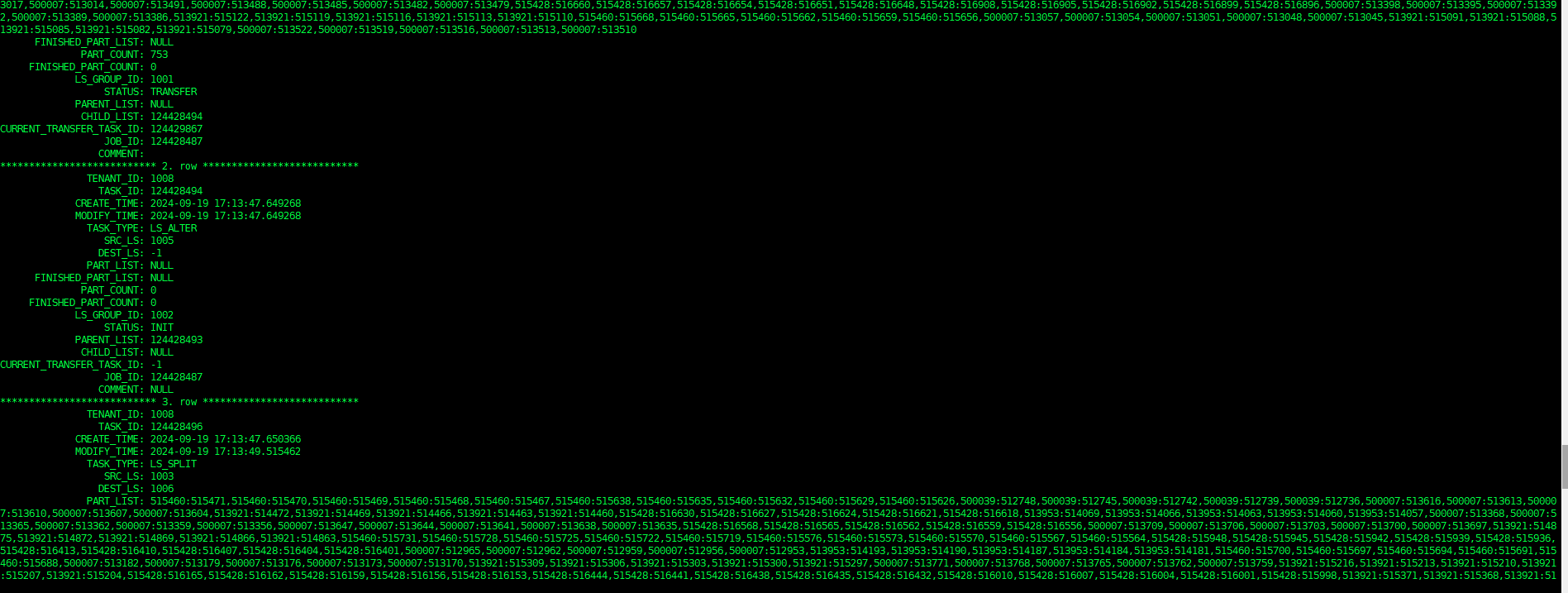
查看正在执行的LS均衡任务
select * From CDB_OB_BALANCE_TASKS \G;
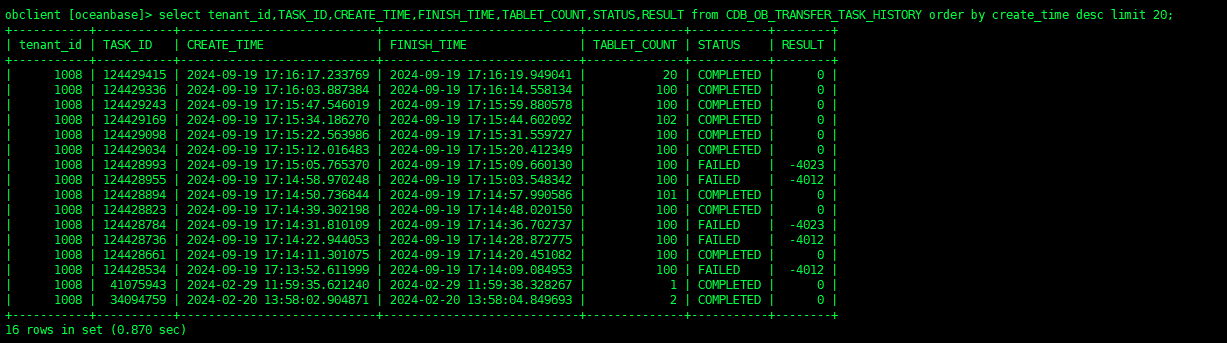
查看transfer任务的历史记录
select tenant_id,TASK_ID,CREATE_TIME,FINISH_TIME,TABLET_COUNT,STATUS,RESULT from CDB_OB_TRANSFER_TASK_HISTORY order by create_time desc limit 20;
查看LS均衡任务的历史记录
select tenant_id,TASK_ID,CREATE_TIME,FINISH_TIME,PART_COUNT,STATUS,RESULT from CDB_OB_BALANCE_TASK_HISTORY order by create_time desc limit 20;
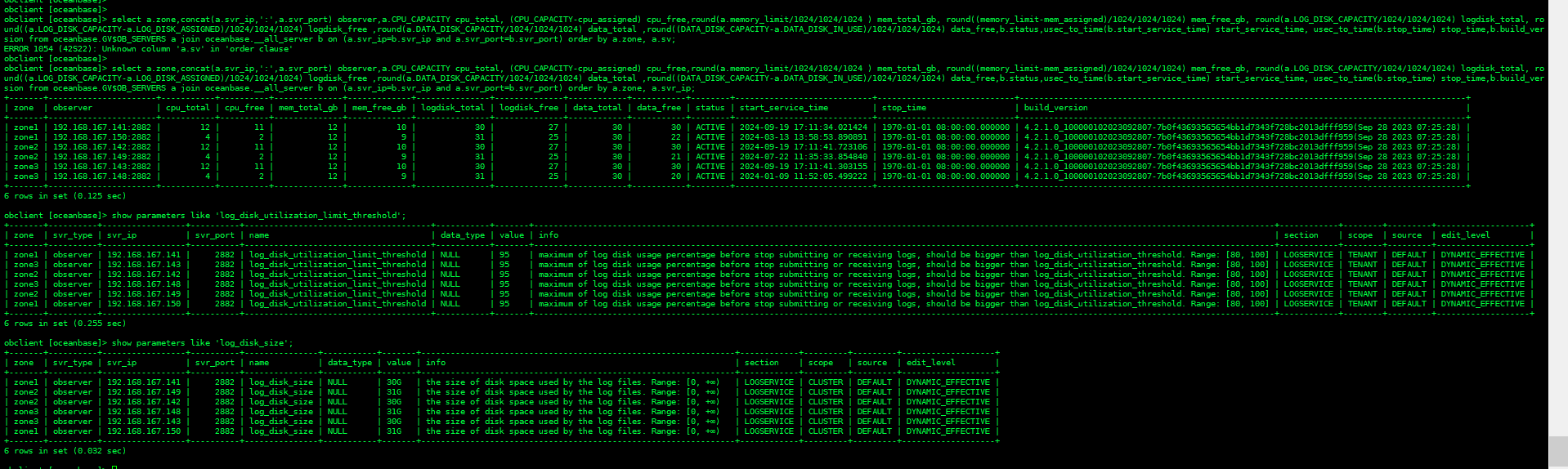
先查询一下 这几个信息
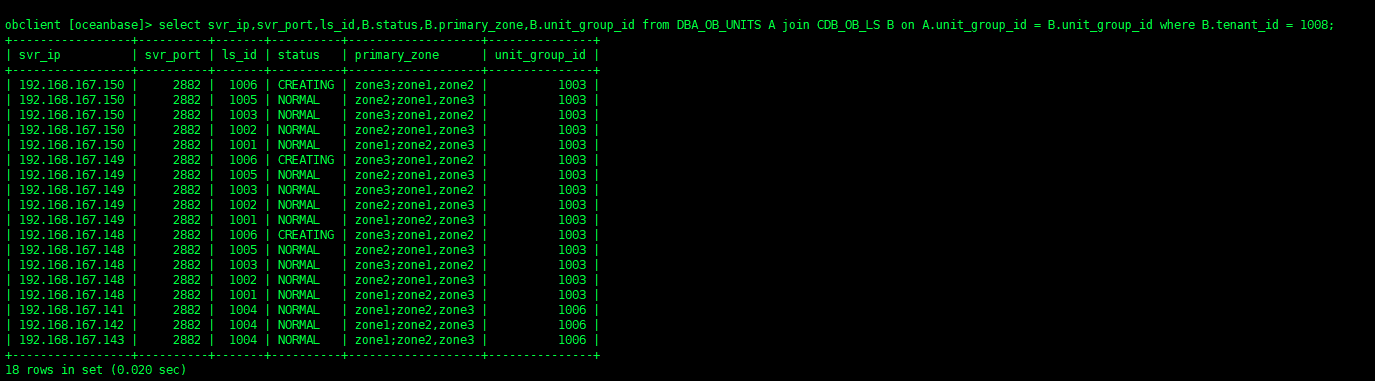
(1) 查询src_ls和dest_ls的当前分布和目标分布情况,确认分布不正常的LS
LS目标分布查询
select svr_ip,svr_port,ls_id,B.status,B.primary_zone,B.unit_group_id from DBA_OB_UNITS A join CDB_OB_LS B on A.unit_group_id = B.unit_group_id where B.tenant_id = 1004 and B.ls_id = 1001;
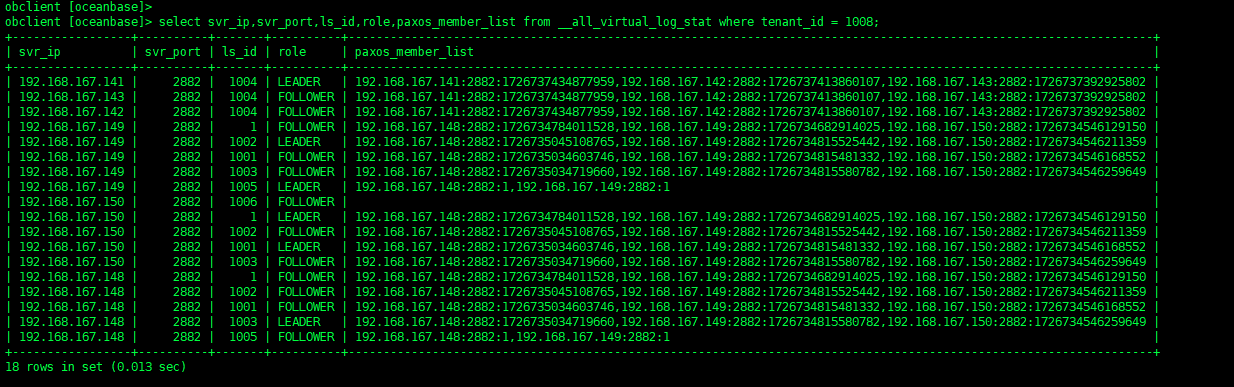
LS当前分布查询
select svr_ip,svr_port,ls_id,role,paxos_member_list from __all_virtual_log_stat where tenant_id = 1004 and ls_id = 1001;
(2) 查询RS端LS迁移的调度情况
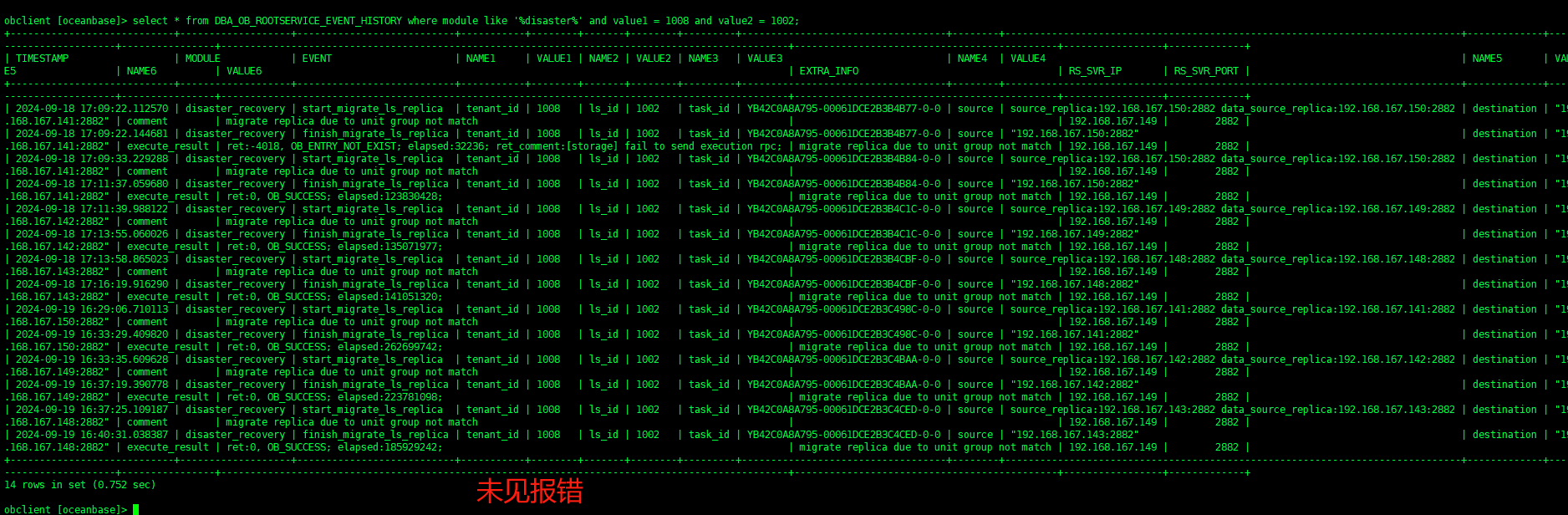
查看迁移调度
select * from DBA_OB_ROOTSERVICE_EVENT_HISTORY where module like “%disaster%” and value1 = 1004 and value2 = 1001;
LS迁移卡住的场景,一般会有明显报错。
(3) 查询底层LS迁移执行情况
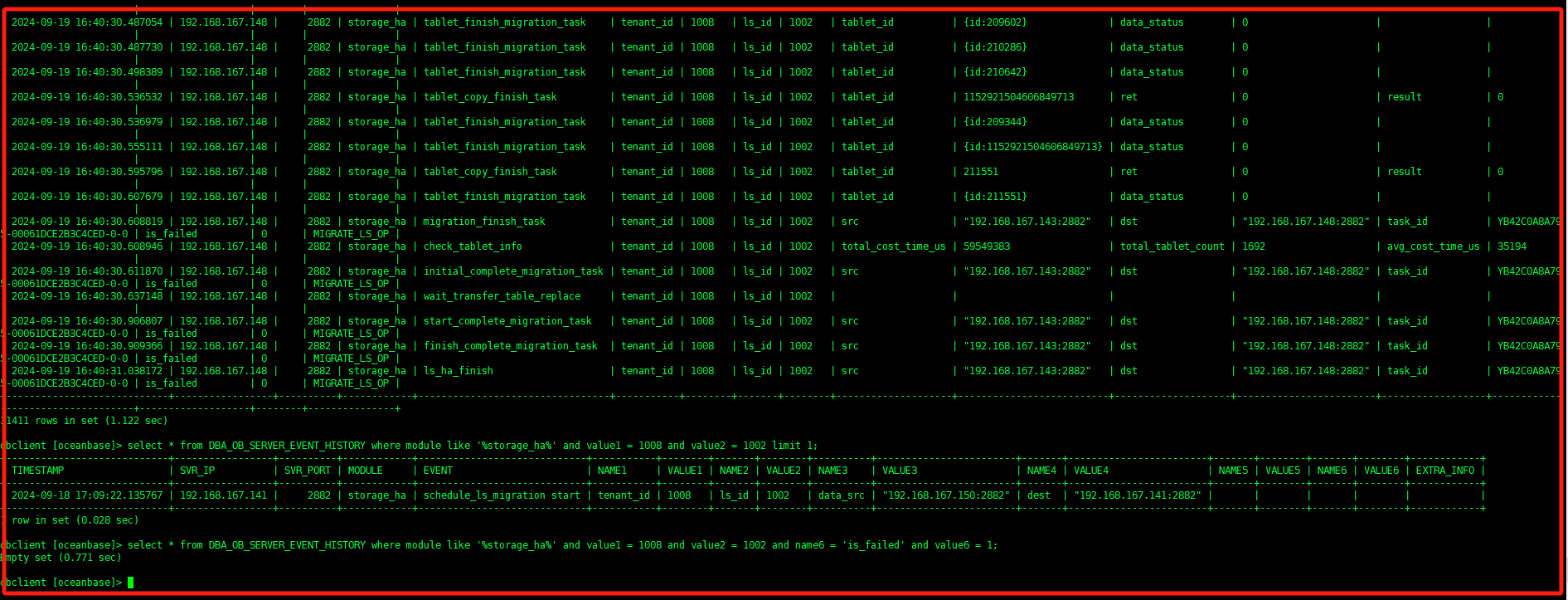
select * from DBA_OB_SERVER_EVENT_HISTORY where module like ‘storage_ha’ and value1 = 1004 and value2 = 1001;
一般会有明显报错。
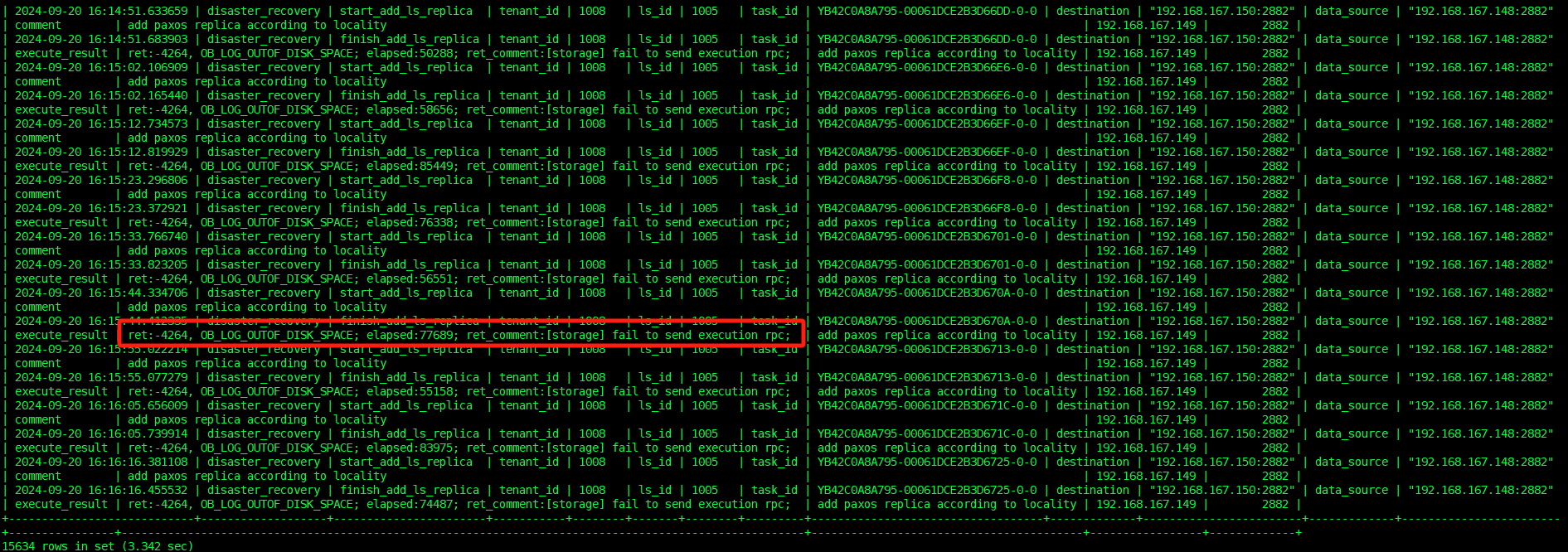
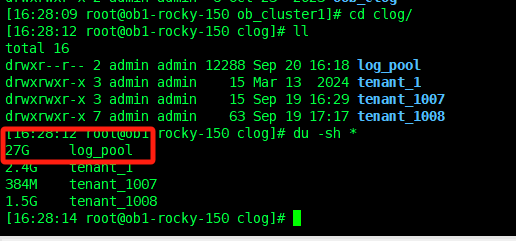
刚才查的是tenant_id=1008和ls_id=1002的 现在查一下 tenant_id=1008和ls_id=1005
(2) 查询RS端LS迁移的调度情况
查看迁移调度
select * from DBA_OB_ROOTSERVICE_EVENT_HISTORY where module like “%disaster%” and value1 = 1008 and value2 = 1005;
LS迁移卡住的场景,一般会有明显报错。
(3) 查询底层LS迁移执行情况
select * from DBA_OB_SERVER_EVENT_HISTORY where module like ‘storage_ha’ and value1 = 1008 and value2 = 1005;
一般会有明显报错。
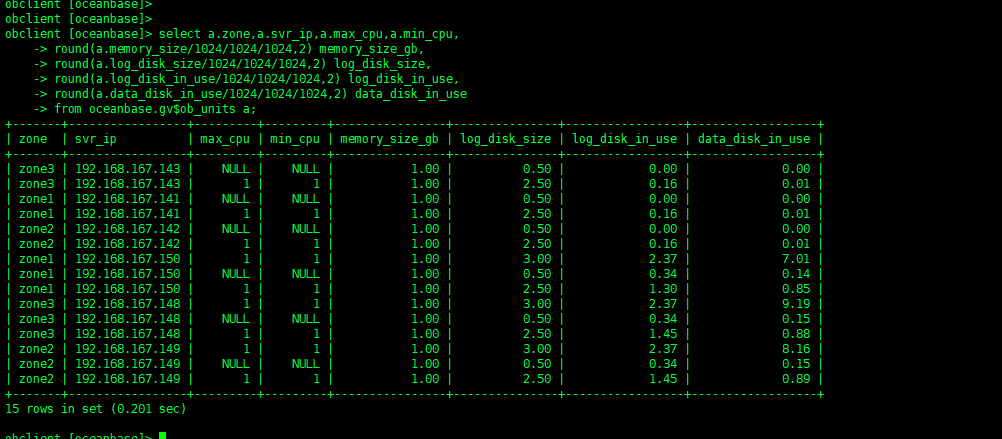
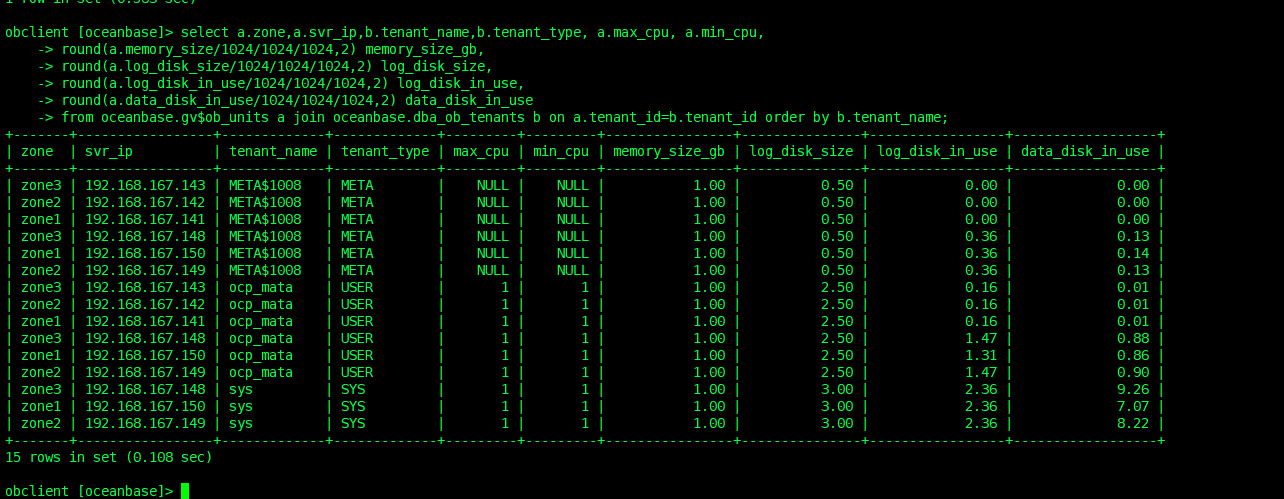
在查租户的资源
select a.zone,a.svr_ip,b.tenant_name,b.tenant_type, a.max_cpu, a.min_cpu,
round(a.memory_size/1024/1024/1024,2) memory_size_gb,
round(a.log_disk_size/1024/1024/1024,2) log_disk_size,
round(a.log_disk_in_use/1024/1024/1024,2) log_disk_in_use,
round(a.data_disk_in_use/1024/1024/1024,2) data_disk_in_use
from oceanbase.gv$ob_units a join oceanbase.dba_ob_tenants b on a.tenant_id=b.tenant_id order by b.tenant_name;