【 使用环境 】生产环境
【 OB or 其他组件 】ob
version: 3.1.2
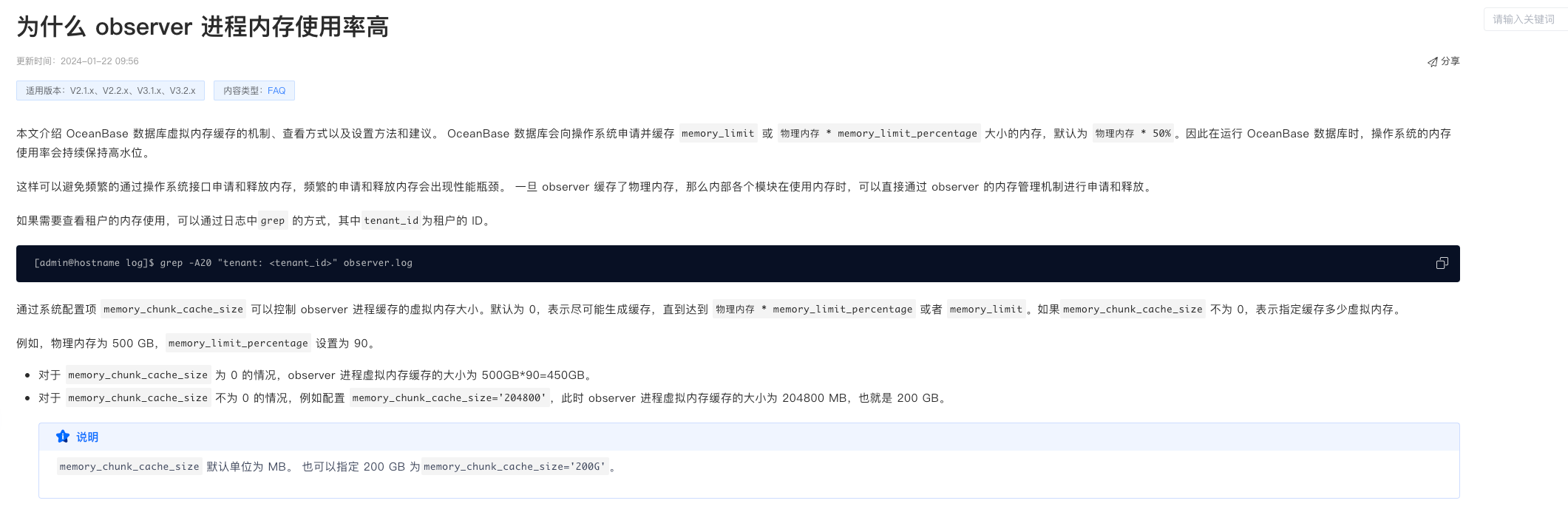
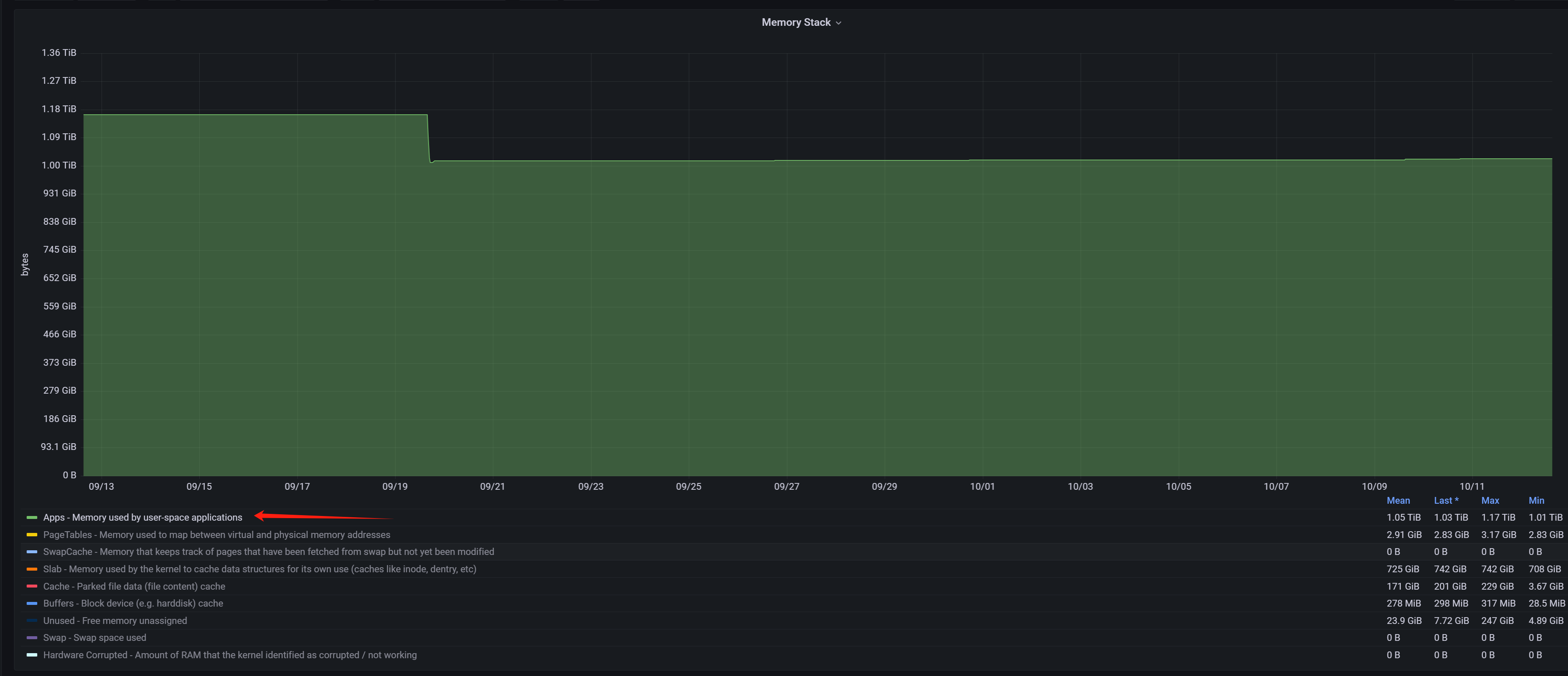
free -h 显示2TB的内存使用了1.9TB:

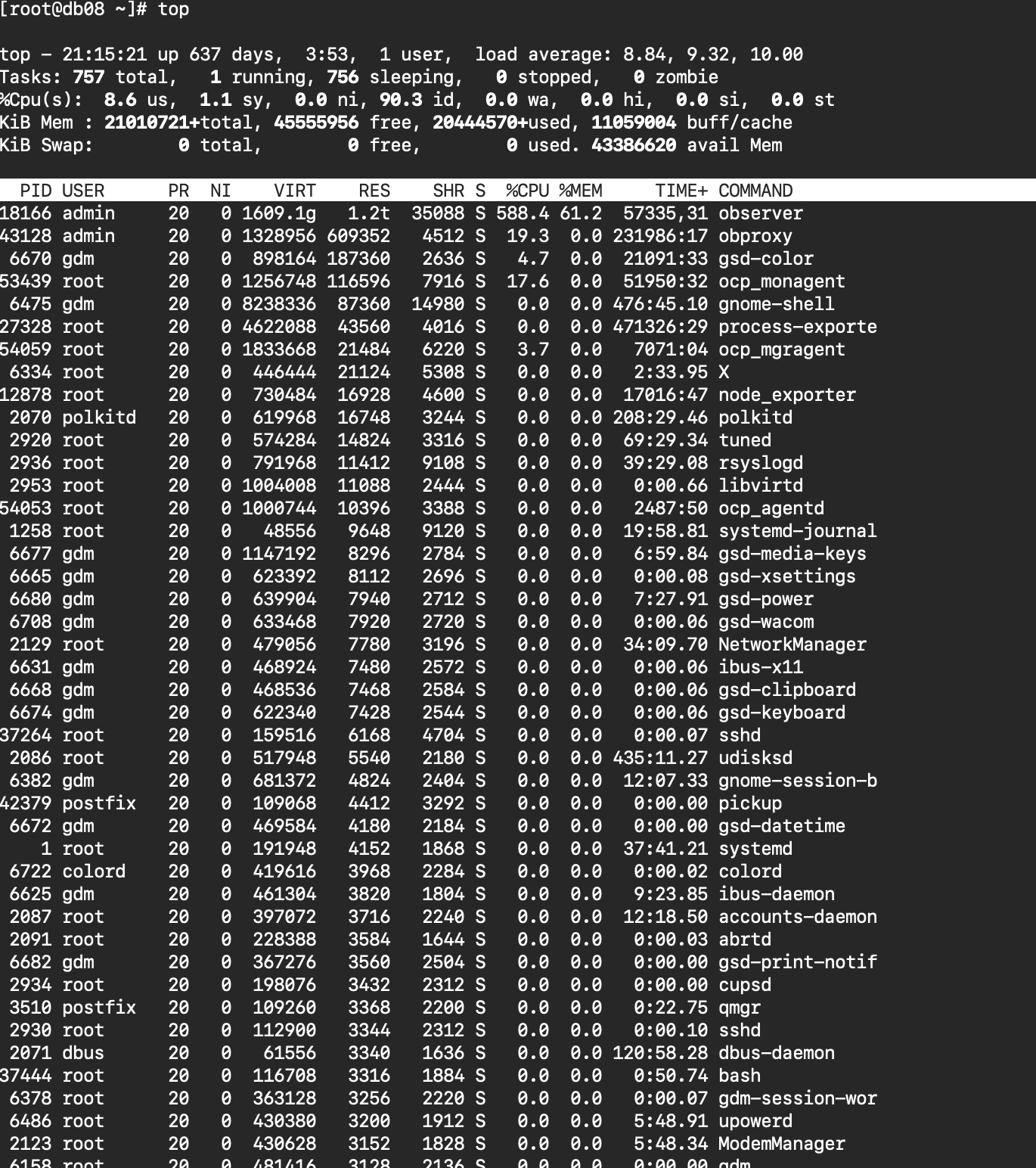
top 按照内存排序
全量加起来也不足1.3TB,使用sync;echo 3 > /proc/sys/vm/drop_caches 尝试清理缓存,无效。
请问,是否Observer预占了内存? 内存被什么占用了? 是否可以释放内存? 否则节点内存很快100%了,我看集群中的其他节点内存使用率没这么高。
【 使用环境 】生产环境
【 OB or 其他组件 】ob
version: 3.1.2
free -h 显示2TB的内存使用了1.9TB:
top 按照内存排序
全量加起来也不足1.3TB,使用sync;echo 3 > /proc/sys/vm/drop_caches 尝试清理缓存,无效。
请问,是否Observer预占了内存? 内存被什么占用了? 是否可以释放内存? 否则节点内存很快100%了,我看集群中的其他节点内存使用率没这么高。
OB 的设计理念就是占用主机的 绝大部分计算和存储资源。CPU 理论上占总cpu核数-2(参数 cpu_count),内存默认占80%(参数 memory_limit_percentage 或 memory_limit),磁盘默认占目录的70% ( datafile_size_percentage 或 datafile_size , 以及 log_disk_size) 。
部署的时候如果没有指定这些参数就都变成默认值了。内存参数后期也可以再修改(OB 的扩容和缩容能力),数据文件只能扩容不能缩容,日志空间可以扩容和缩容。
机器 2T 内存非常富裕。如果是测试服务器,还是做几个虚拟机给 OB 用。如果是生产服务器, memory_limit=1T 足够用了。 OB 机器上也不建议跟其他数据库混用。
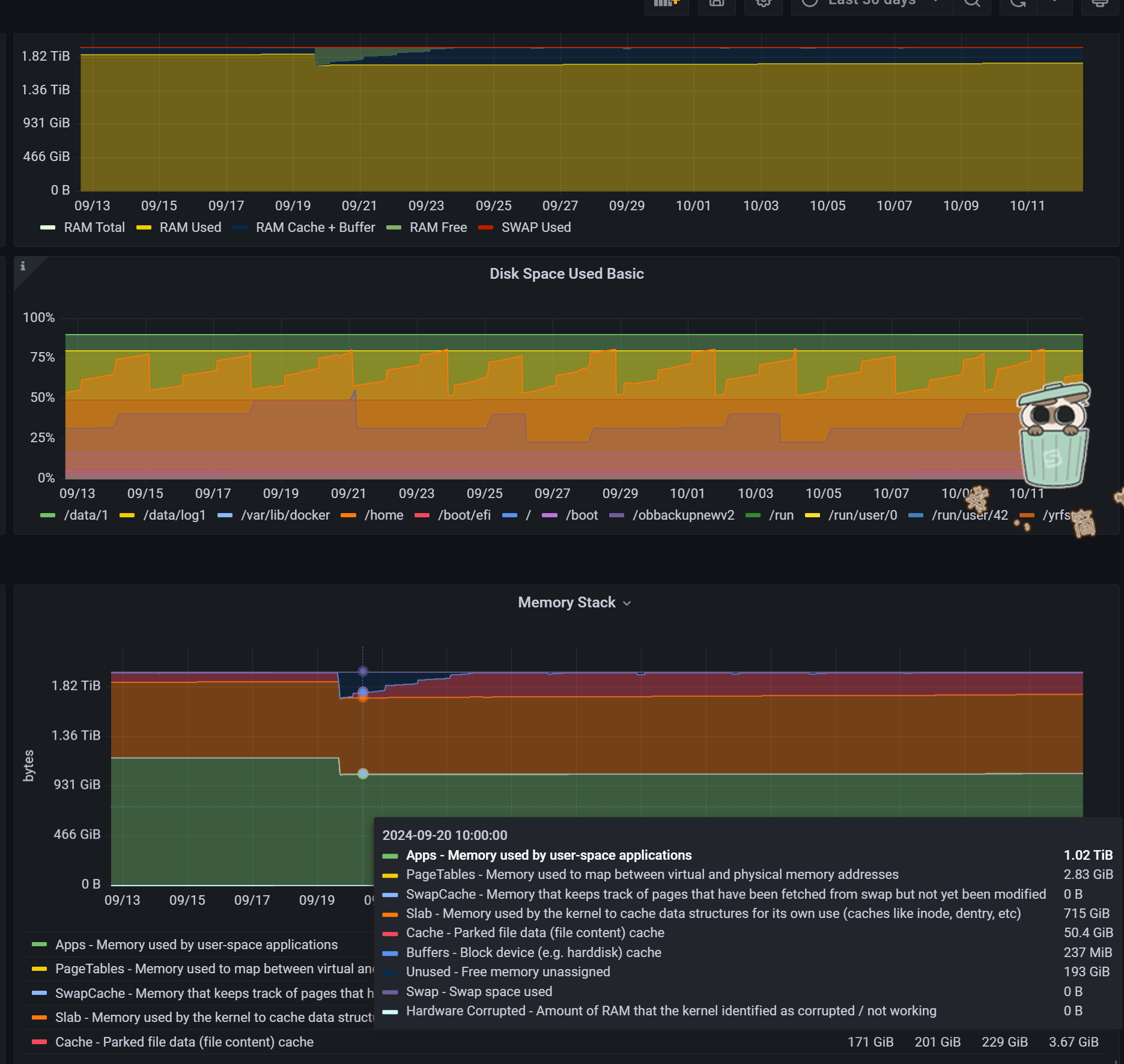
free -h 中 内存占用1.9TB,free 43G,几乎耗尽,
top 中observer占用 61.2% 即1.2TB左右,
从这些数据看内存应该是被其它程序占用了,要从OS层面深入分析下,
OB的内存占用受限于memory_limit_percentage 或 memory_limit,不会超过这个限制
sys租户查下 OB内存设置情况:
show parameters like ‘%memory%’\G;
另外 网上下载一个 命令 smem ,这个可以查看 内存使用细节。按进程、用户统计等等。
[root@server065 ~]# smem -k -t -u
User Count Swap USS PSS RSS
chrony 1 0 516.0K 593.0K 1.4M
rpc 1 0 592.0K 613.0K 1.1M
dbus 1 0 984.0K 1.2M 2.5M
zabbix 5 0 1.7M 2.6M 9.4M
polkitd 1 0 5.6M 6.1M 8.1M
nginx 25 0 4.8M 7.6M 72.3M
proxysql 2 0 18.3M 19.2M 21.2M
grafana 1 0 69.6M 69.6M 70.3M
tidb 8 0 93.0M 93.2M 96.3M
oracle 51 0 252.0M 575.5M 1.7G
root 118 0 820.6M 1.0G 8.7G
vastbase 1 0 2.0G 2.0G 2.0G
admin 8 0 7.9G 7.9G 8.0G
---------------------------------------------------
223 0 11.2G 11.8G 20.7G
[root@server065 ~]#
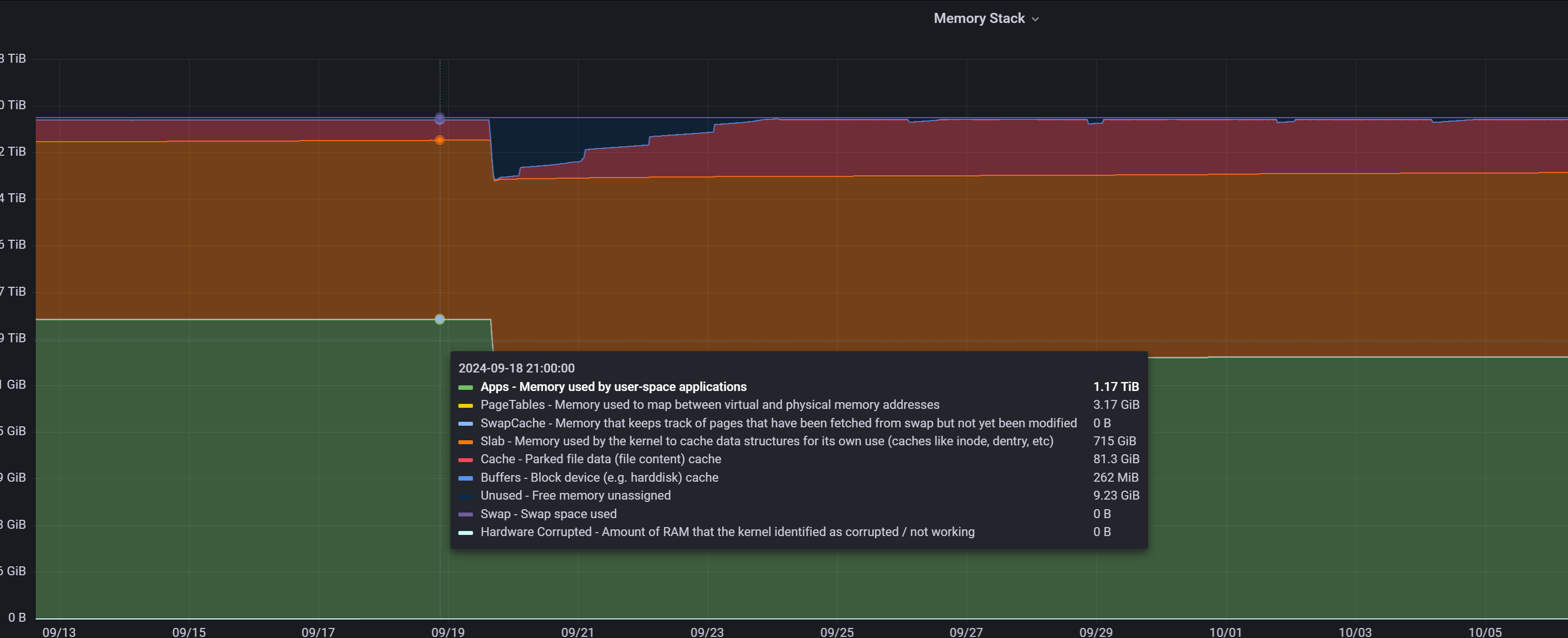
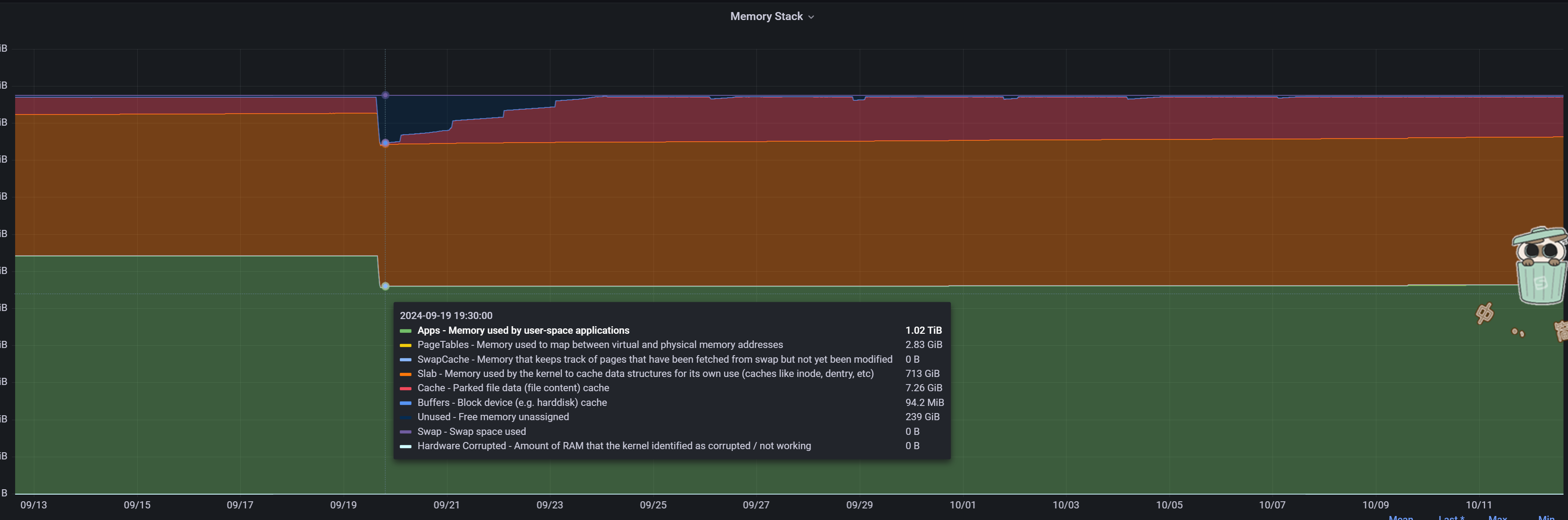
有几百G的内存确实不知道哪里去了
[root@db08 yum.repos.d]# smem -k -t -u -p
User Count Swap USS PSS RSS
libstoragemgmt 1 0 156.0K 163.0K 776.0K
nobody 1 0 84.0K 242.0K 904.0K
rtkit 1 0 400.0K 419.0K 1.7M
rpc 1 0 564.0K 570.0K 1.0M
avahi 2 0 356.0K 695.0K 2.5M
ntp 1 0 764.0K 839.0K 1.9M
colord 1 0 1.7M 1.7M 4.0M
dbus 1 0 1.7M 1.8M 3.3M
postfix 2 0 3.2M 3.5M 7.6M
polkitd 1 0 14.1M 14.2M 16.4M
gdm 32 0 316.4M 319.7M 383.8M
root 47 0 448.1M 462.1M 538.4M
admin 3 0 1.2T 1.2T 1.2T
---------------------------------------------------
94 0 1.2T 1.2T 1.2T
其他节点也是这样的
[root@db10 ~]# smem -k -t -u -p
User Count Swap USS PSS RSS
libstoragemgmt 1 0 160.0K 168.0K 784.0K
nobody 1 0 164.0K 319.0K 996.0K
rtkit 1 0 400.0K 420.0K 1.7M
rpc 1 0 560.0K 568.0K 1.0M
avahi 2 0 476.0K 817.0K 2.6M
ntp 1 0 756.0K 831.0K 1.9M
colord 1 0 1.7M 1.8M 4.2M
dbus 1 0 2.5M 2.5M 4.1M
postfix 2 0 2.9M 3.3M 7.1M
polkitd 1 0 12.1M 12.1M 14.4M
gdm 32 0 218.1M 224.0M 294.3M
root 47 0 375.9M 407.8M 523.8M
admin 4 0 1.4T 1.4T 1.4T
---------------------------------------------------
95 0 1.4T 1.4T 1.4T
[root@db10 ~]# free -h
total used free shared buff/cache available
Mem: 2.0T 1.7T 146G 1.1G 106G 242G
Swap: 0B 0B 0B
[root@db10 ~]#
我们OB集群资源分配不大,先减少下memory_limit看看
内存确实很大,集群内存分配率45%,其他2T的机器做了虚机给OCP,这个observer是独占的
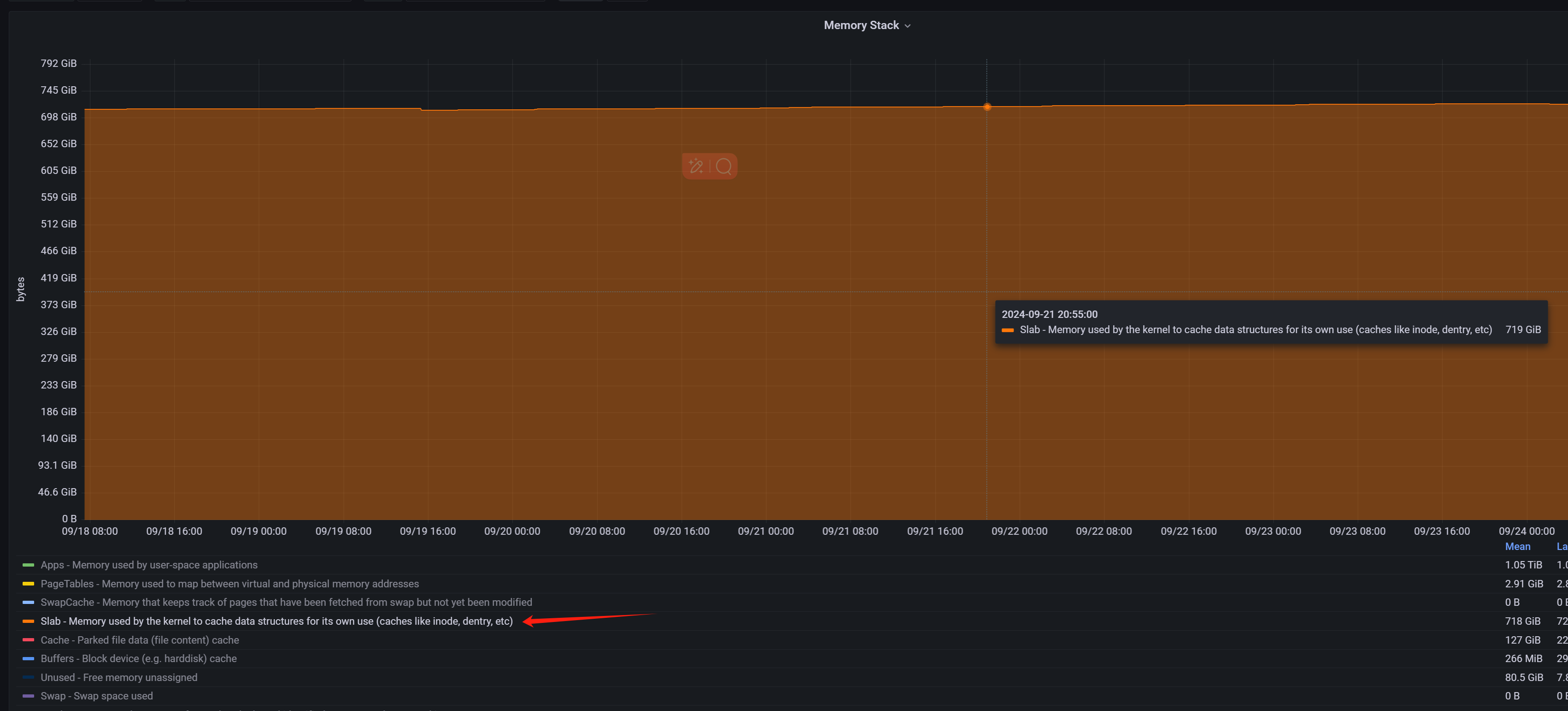
刚看了下可能是slab占了
[root@db08 slab_1024K]# cat /proc/meminfo | grep -i slab
Slab: 699630928 kB
[root@db08 slab_1024K]#
SLAB分为SReclaimable可回收和SUnreclaim不可回收
cat /proc/meminfo | grep -i SReclaimable
cat /proc/meminfo | grep -i SUnreclaim
查看slabinfo信息
cat /proc/slabinfo
slabtop 查看TOP
slabtop --sort c --once | head -n12
/bin/slabtop --once
可以使用crash工具进行静态分析,也可以使用perf工具进行动态分析,排查造成slab内存泄露的原因。
排查内存泄漏太难了,太多信息看不懂。
我昨天将除了observer外的所有应用都重启了,当重启obproxy的时候slab的数值降了一点点,其他都没降,现在就除了observer和操作系统没有重启,推断不是observer就是os泄漏了。找机会重启试试。
obproxy一般情况下 不会消耗太多内存的 本身配置的时候 不会给太多内存的
你在查询一下 内存信息 看看是不是内存哪里有问题
–查询租户在物理机上的资源使用情况,执行语句如下。
SELECT now(),tenant_id, ip, round(active/1024/1024/1024,2) active_gb, round(total/1024/1024/1024,2) total_gb, round(freeze_trigger/1024/1024/1024,2) freeze_trg_gb, round(mem_limit/1024/1024/1024,2) mem_limit_gb, freeze_cnt , round((active/freeze_trigger),2) freeze_pct, round(total/mem_limit, 2) mem_usage FROM gv$memstore WHERE tenant_id =xxxx ORDER BY tenant_id, ip;
–通过 __all_virtual_memory_info 系统表查询 OceanBase 数据库各个 Mod 的内存消耗情况(MemStore 内存未超限),执行如下查询语句。
SELECT tenant_id,svr_ip,sum(hold) module_sum FROM __all_virtual_memory_info WHERE tenant_id>1000 AND hold<>0 AND mod_name NOT IN ( ‘OB_KVSTORE_CACHE’,‘OB_MEMSTORE’) GROUP BY tenant_id,svr_ip;
不错的问题
学到了,还真没用过这个命令
内容很好
感谢分享!
宝贵的经验分享,谢谢!
内容很好