

【 使用环境 】测试环境
【 OB or 其他组件 】OB
【 使用版本 】3.2.4
官方文档中对于 buffer 表的定义有一个描述:“有大量的索引列更新”
于是有一个问题:为什么对非索引列的大量更新不会产生buffer 表问题?
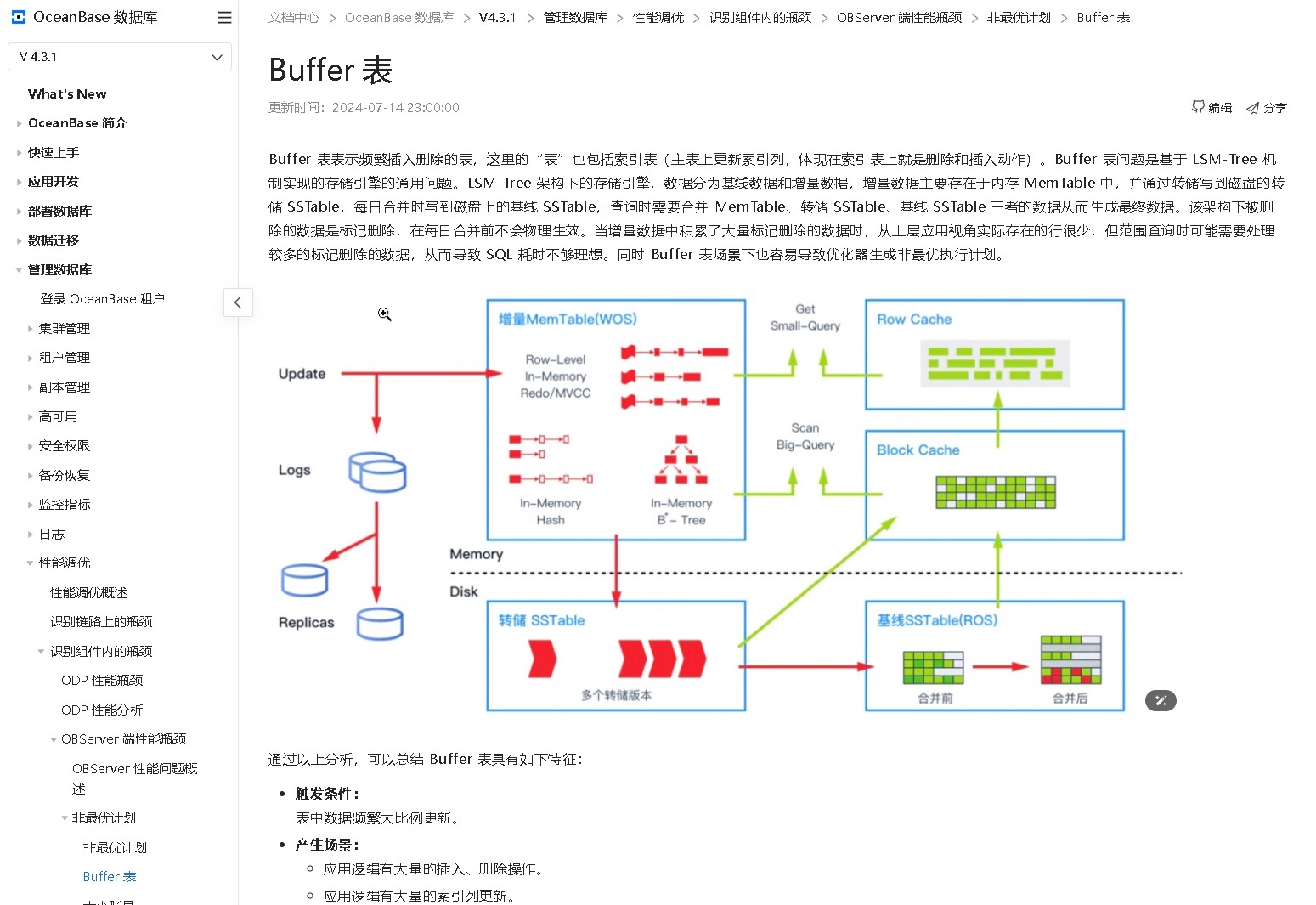
以下是基于对 lsm-tree 的 key-value 存储格式进行的推理:
-
更新索引列,索引列的值会变,lsm-tree 是 key-value 存储,对于索引,它的 key 类似于:tableid_{索引列的值}_{主键列的值},key 变了,lsm-tree 中会有一个新的记录。大批量反复更新,会导致lsm-tree中新增很多记录;
-
更新非索引列,实际是对主表数据进行更新,主表的 key 类似于:tableid_{主键列的值},由于主键列的值没有更新,key 就不会更新,lsm-tree 中不会产生新的记录。大批量反复更新,不会导致 lsm-tree中新增记录。
这个解释有个问题,对照 rocksdb 的解释,lsm-tree 里存储的 key 实际上还有个 version 部分(实际就是事务的提交版本号),类似于 tableid{主键列的值}_version,对于更新非索引列的场景,key 其实也会更新,表现在 _version 的变化。
这样推理下来,需要深究 OB 中如何存储多版本数据,设计了一个测试:
-
表本来有 13000 行数据,每次 update 主键值相同的 3000 行数据,更新非索引字段
-
update 3000 行,全表扫描:16000 行(MEMSTORE_READ_ROW_COUNT:3000,SSSTORE_READ_ROW_COUNT:13000)
-
转储一次(mini merge),全表扫描:16000 行
-
update 3000 行,全表扫描:19000 行(MEMSTORE_READ_ROW_COUNT:3000,SSSTORE_READ_ROW_COUNT:16000)
-
转储一次(mini merge),全表扫描:19000 行。说明 2 个 mini sstable 中各有 3000 行记录,加上 major sstable 中的 13000 行,加起来要扫 19000 行
-
update 3000 行,全表扫描:22000 行(MEMSTORE_READ_ROW_COUNT:3000,SSSTORE_READ_ROW_COUNT:19000)
-
再转储一次,触发 mini minor merge,全表扫描:16000 行。说明 mini sstable 进行 compaction 时,对于同一行数据只会保留一个记录,所以扫描行数= (major sstable里的 13000 行)+(mini sstable 里的 3000 行) 。这里一个记录不是指一个版本,如果只保留最新一个版本,如果有事务要读取在 undo_retention 时间内的旧版本,会报错,但可以在实验开始前设置隔离级别为 serializable 并启动一个事务,读取表的数据,在第7步再次读取不会报错,证明旧版本数据没有被清理。这里似乎可以证明 sstable 中数据行的多版本还是以 MvccRow 链表保存的。
根据实验结果,是否能够说明 OB 的存储实现里,sstable 存储多版本的格式中,key 部分是 table_id_{主键列的值},没有 _version 部分,而是和 memstable 中一样用了 MvccRow 链表?
那么,对于大量 delete + insert 场景,如果表有显示主键,每次insert 的行主键不变(比如每次都是 insert into t1 select * from t2),由于 rowkey 不变,也不会产生buffer表问题。
所以这个帖子最终想请教两个结论:
- OB 中 sstable 数据行的多版本存储形式是 table_id_{主键列的值}_version,对同一“行”数据,如果有多个版本,就会存有多“行”;还是和 memstable 中一样用了 MvccRow 链表,对于同一“行”数据,如果有多个版本,只存一“行”链表?
- buffer 表的形成条件比较多,对于大量 delete + insert 场景,最典型的是使用全局临时表,因为一般不会有显示主键;对于普通表,如果有显示主键,场景是 insert into t1 select * from t2,把 t1 表当临时表来用,其实不会有 buffer 表问题?