大家使用mysql租户的隔离级别是用"可重复读"还是"读提交"呢?推荐用什么
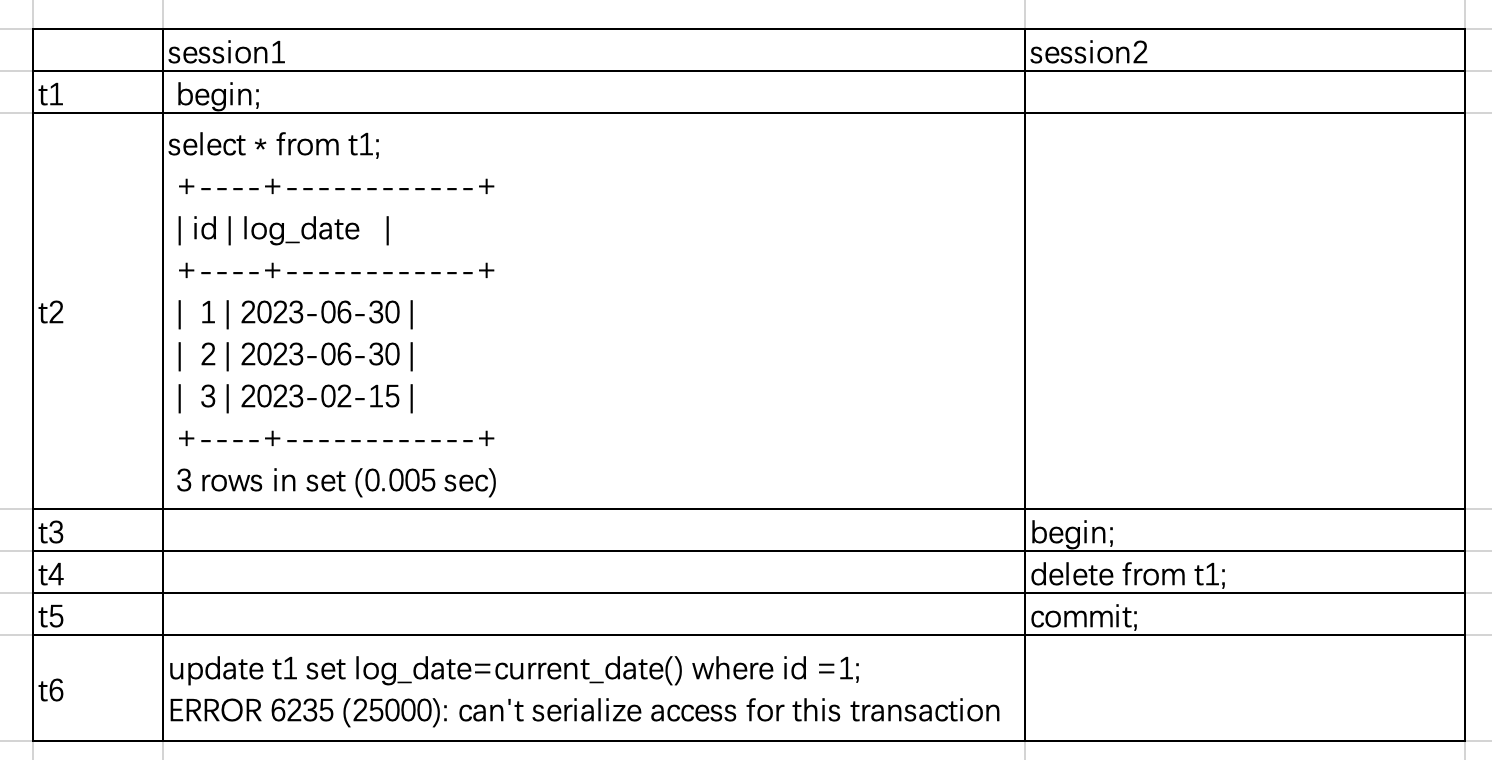
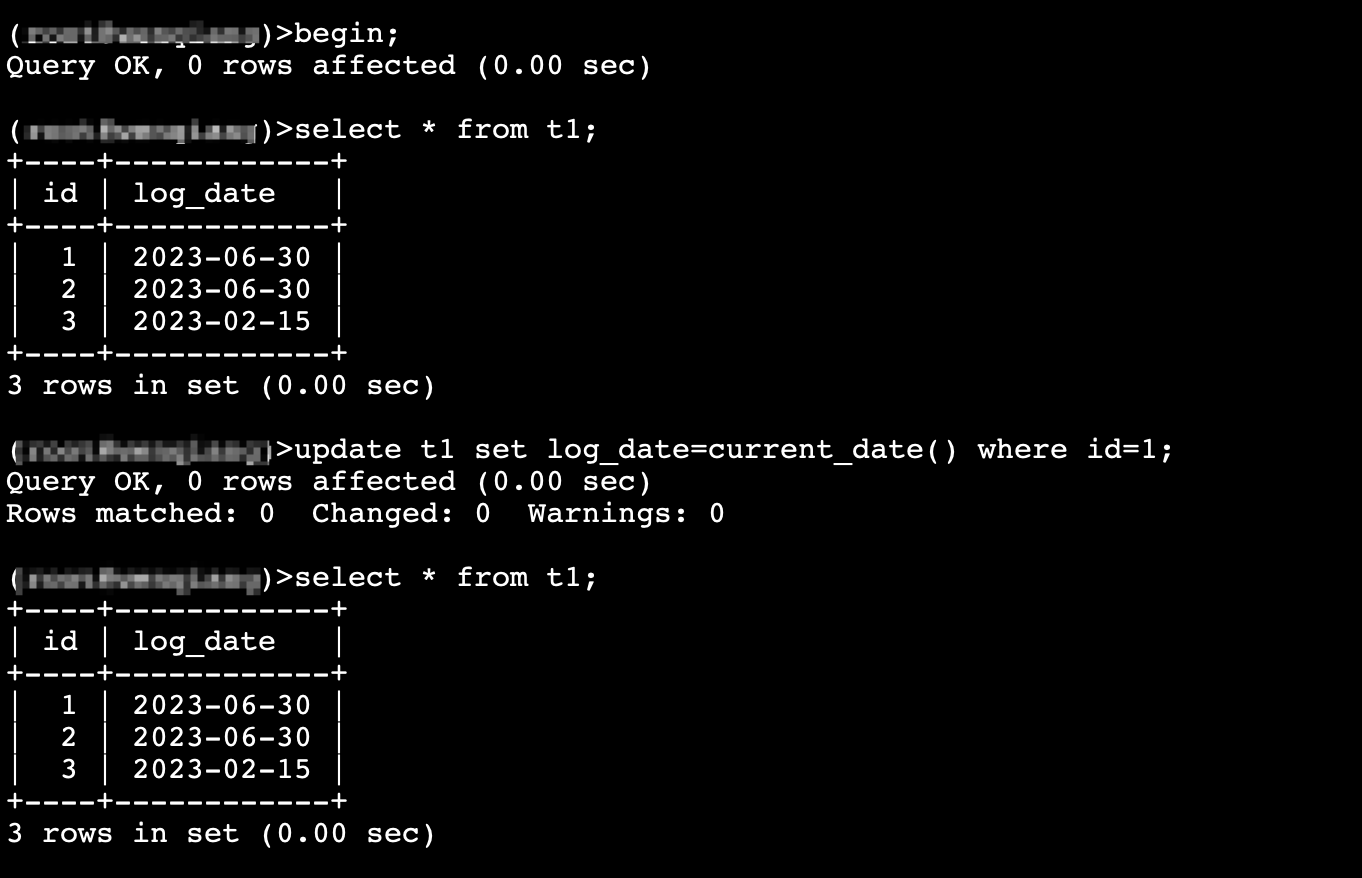
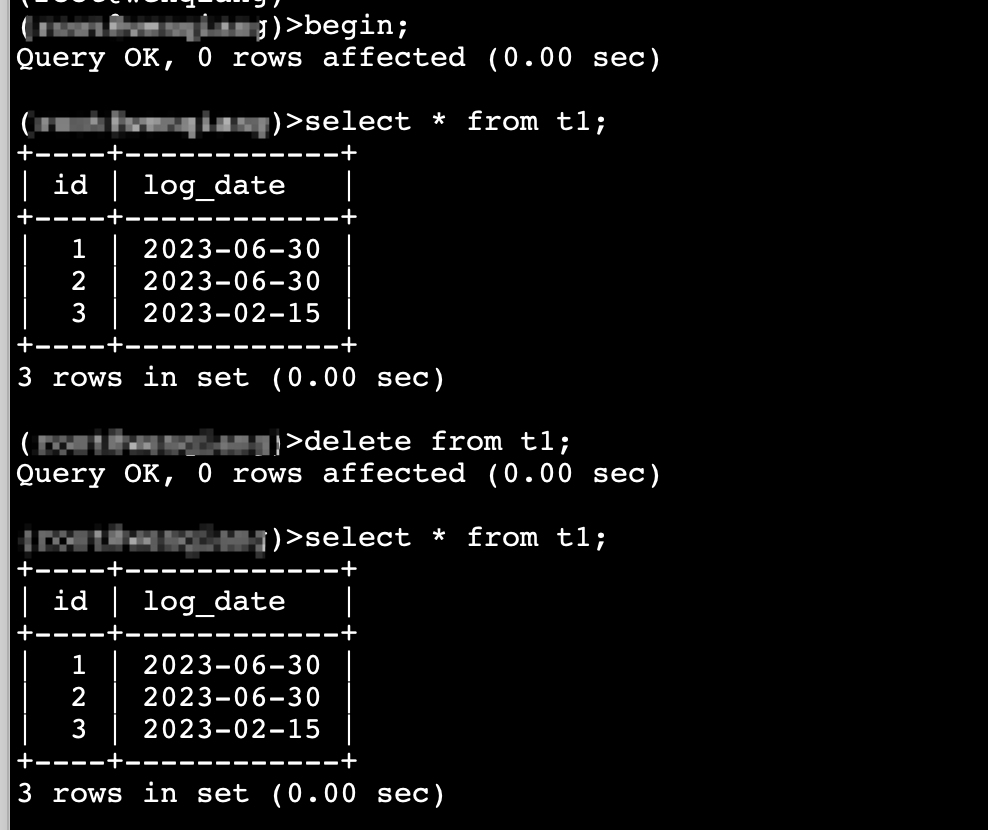
看官方文档是读提交read-commited, 但是有很多存量tidb的业务想迁移到tidb,在测试阶段发现在ob mysql租户的可重复读隔离级别下,跟tidb不同,ob mysql租户偶尔会 SQL 报错 Can’t serialize access for this transaction
请问大家推荐用什么隔离级别呢?对于tidb到ob的迁移这种情况大家是如何解决的呢?
测试案例:
ob mysql租户
create table t1(id int not null primary key, log_date date);
insert into t1 values(1, ‘2023-06-30’), (2, ‘2023-06-30’), (3, ‘2023-02-15’);
set transaction_isolation=‘repeatable-read’;
ob跟mysql/tidb在可重复读隔离级别的异同点已经清楚了, 我想问的是在tidb是可重复读隔离级别,迁移到oceanbase,大家用什么隔离级别或者官方推荐使用什么隔离级别?如果使用oceanbase的可重复读隔离级别,如果出现can’t serialize access for this transaction,大家又是如何处理的呢?
ob的mysql租户在出来的时候只是兼容mysql的sql语法,事务隔离级别特性和原理却是像oracle靠齐的,一开始用了mvcc读(不是用oracle的undo,lsmtree特有机制导致undo并不是那么有必要)。所以早期mysql租户只有rc和serializable两个隔离级别。实在没有什么理由要RR。只是ob发展到3.x后耐不住大量mysql用户的兼容性要求,ob也实现了RR。可是 ob又没有间隙锁那种拙劣的设计,RR也就没有办法做到跟mysql一样。ORACLE 也没有RR,oracle认为如果业务有那种不可重复读和幻读的要求,那可以用 serializable。我估计OB 也是这么认为的。不过 OB 还是努力去实现一个 RR,根据RR的定义,上面那个例子,当update变成一致性读的时候,OB做了跟mysql不一样的选择,OB认为既然你事务隔离级别声明为RR了,那么数据发生变化后你再更新就不不满足这个RR的定义了,直接判你“违例”了(ORA-08177: can’t serialize access for this transaction)。OB的 serializable隔离级别里也很容易看到这个错误。
8.也许有人会说 OB 不是声称兼容mysql 吗?这里不兼容让业务怎么办。我觉得业务还是要想想mysql里你是否一定要用RR?有没有想过在RC下业务也能跑通。很多企业的核心业务跑在ORACLE上,都用的是 RC。所以 mysql迁移到 tidb 的时候有一次机会重新选择事务隔离级别,tidb迁移到 ob的时候又有一次选择的机会。是选择无脑兼容,还是重新选择?
反正要求ob的mysql事务隔离级别RR跟mysql的RR保持完全一致是绝对不可能的。mysql里用间隙锁来实现了RR消除幻读读带来的锁泛滥问题 这个特性 OB 是没法复制的。
9.从mysql入行看oracle 或看 ob,跟从oracle入行看mysql 或看 ob,有些问题的看法上会有区别。ob社区版能力只是 ob 全部能力的一半。ob社区版跟企业版底层代码还是同一份,兼容mysql只是尽可能语法兼容,在特性上 ob都是向 oracle靠拢的。如果oracle的做法更好,肯定不会选mysql的方案。 (这些都是个人观点)