ootoo
#1
【 使用环境 】测试环境
【 OB or 其他组件 】ocp
【 使用版本 】4.3.0-20240617185317
【问题描述】OCP告警中心历史中存在许多inode使用率高的条目,但是到达5分钟消除周期就结束告警了,并且查看所有机器的file_inode_usage值都是0,切换各种时间范围都查看了,然后上对应机器上查看inode使用率,基本上都很低,是否存在监控和告警数据不准的可能?
【复现路径】无
【附件及日志】
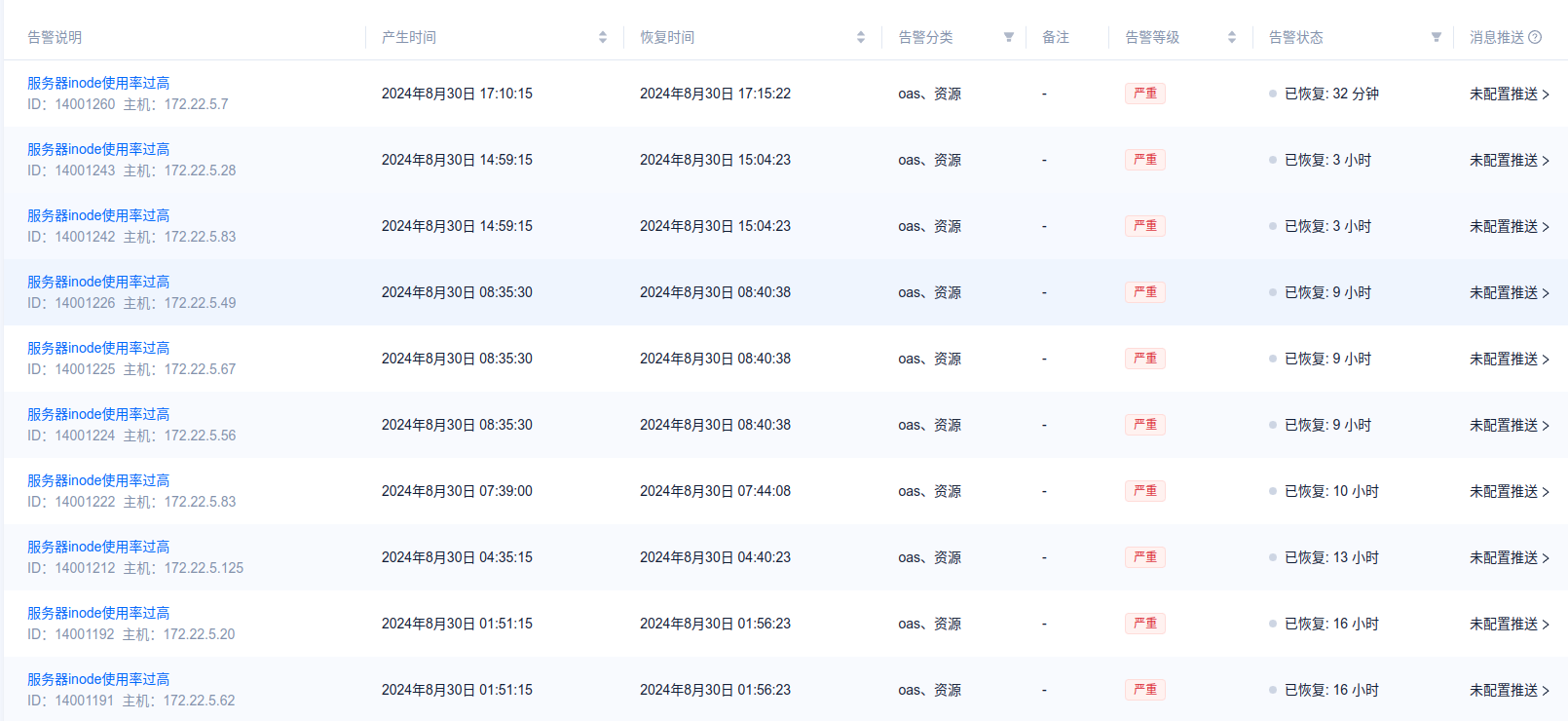
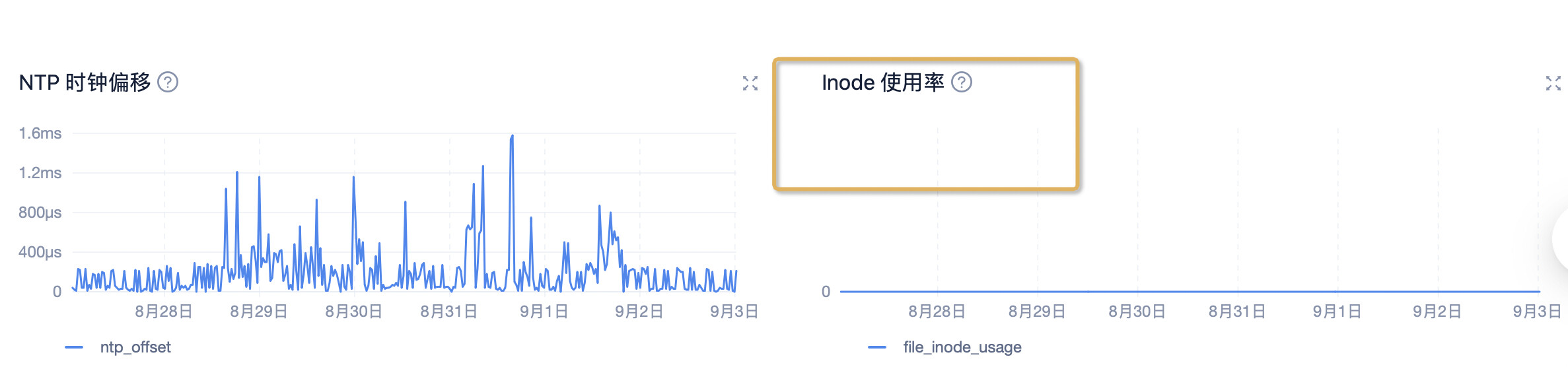
出现很多inode告警
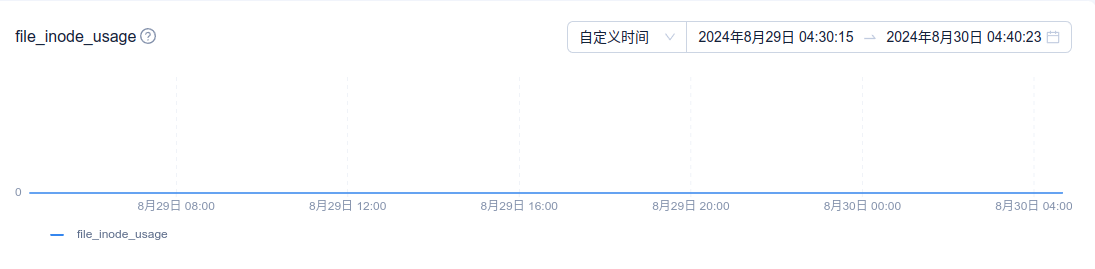
在OCP中查看对应的数值,都是0
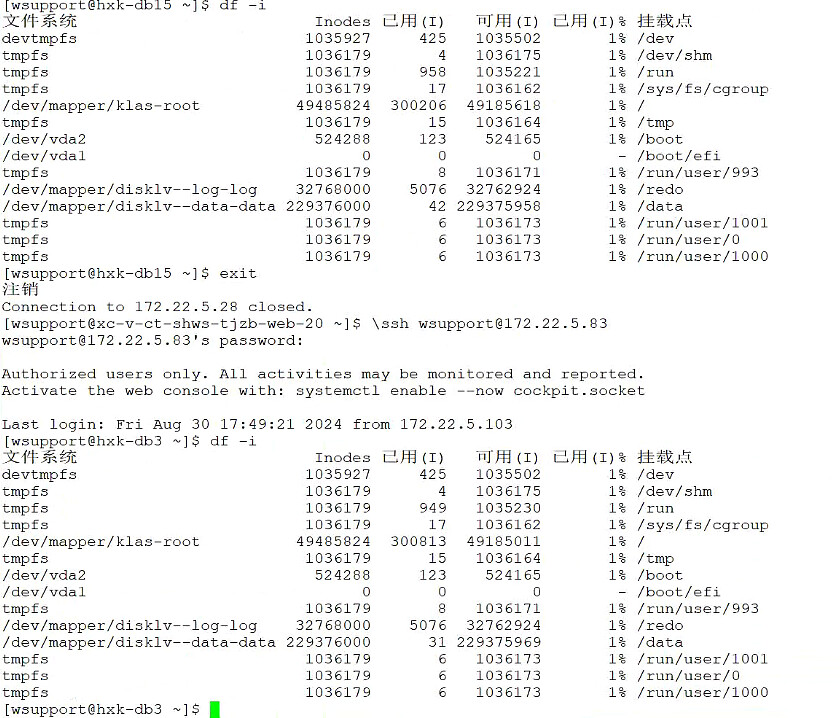
上各个机器查看,使用率基本上很低
查看inode的检测周期是10秒,感觉不太可能10秒内从1%到达80%,然后5分钟的消除周期恢复为1%
3 个赞
皇甫侯
#5
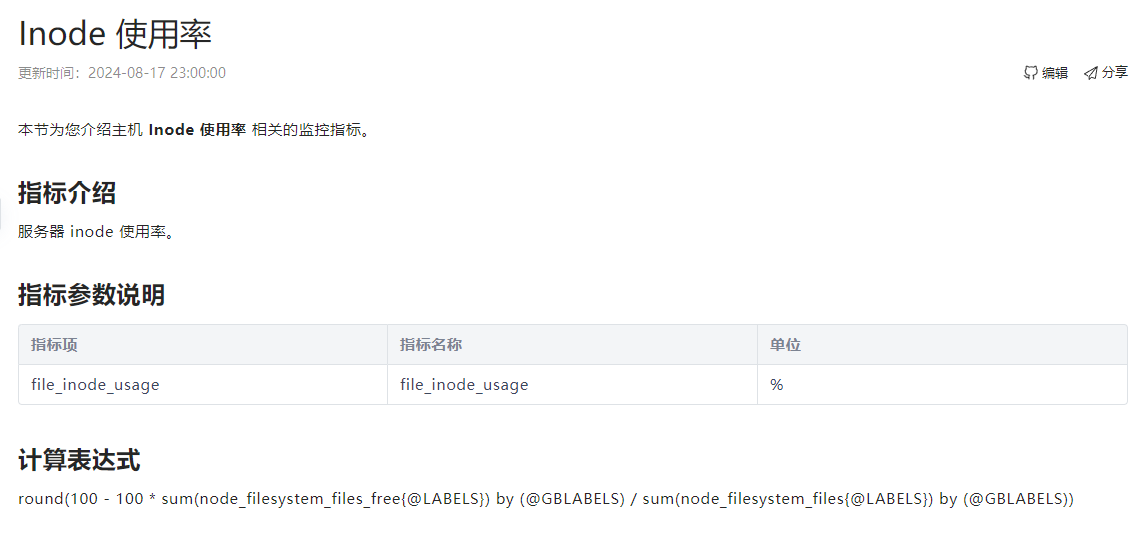
看了下计算公式其实也不难,看样子估计是采集的问题。。
5 个赞
ootoo
#6
您好,版本是 4.3.0-20240617185317

2 个赞
旭辉
#7
麻烦截图看下出现这个告警时 ocp_meta租户的负载情况
2 个赞
ootoo
#8
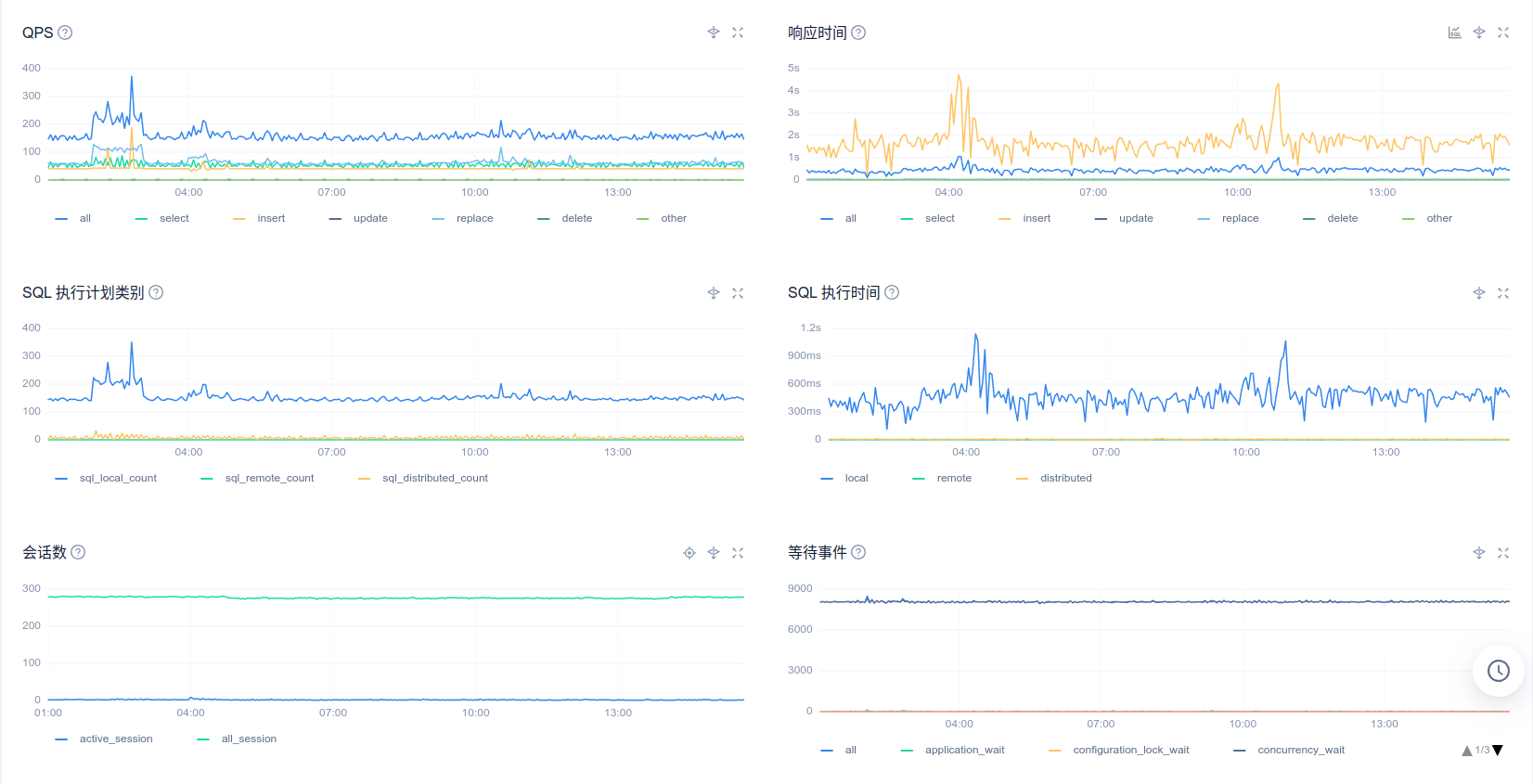
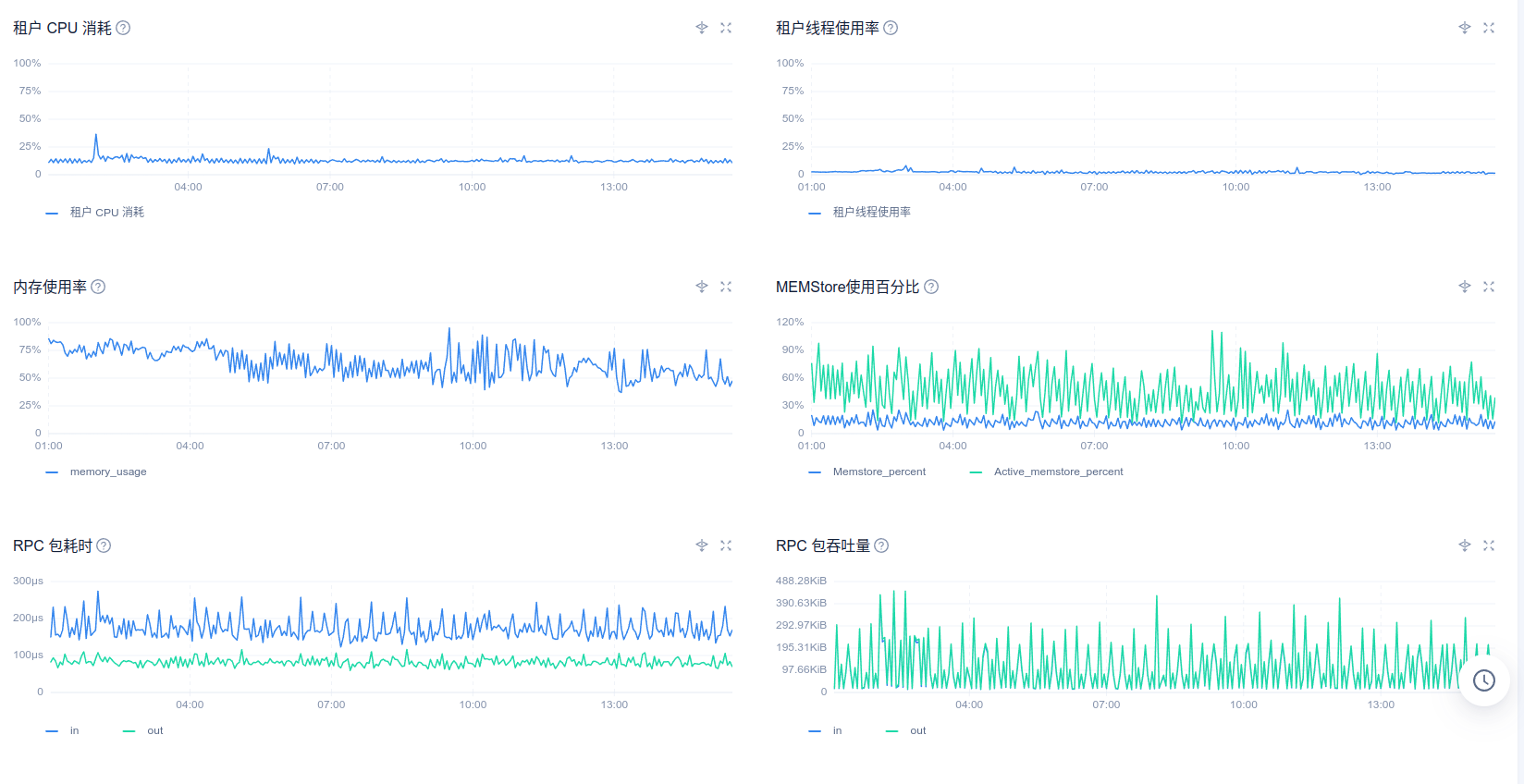
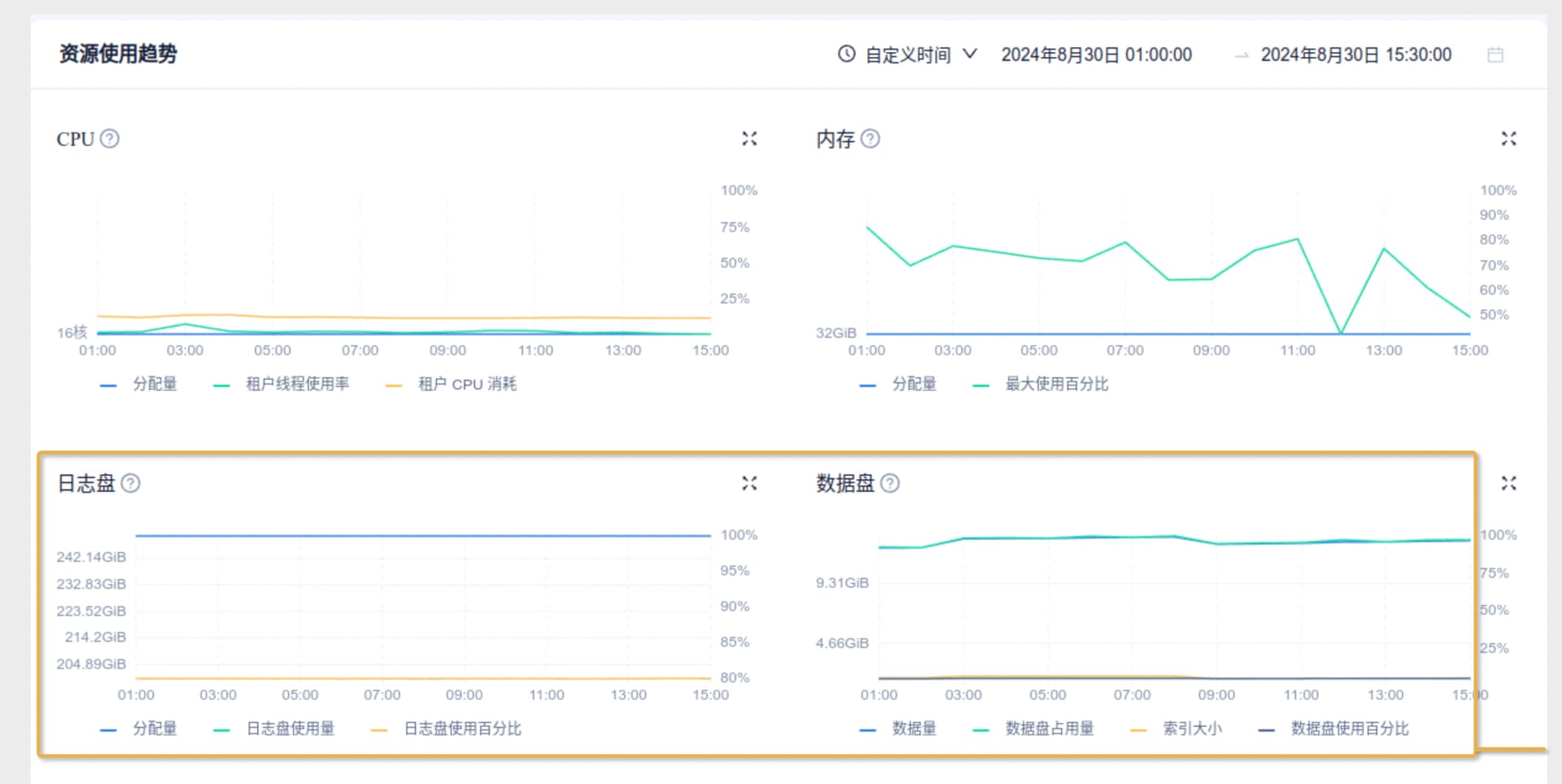
您好,以下是8月30号ocp_meta租户的性能情况
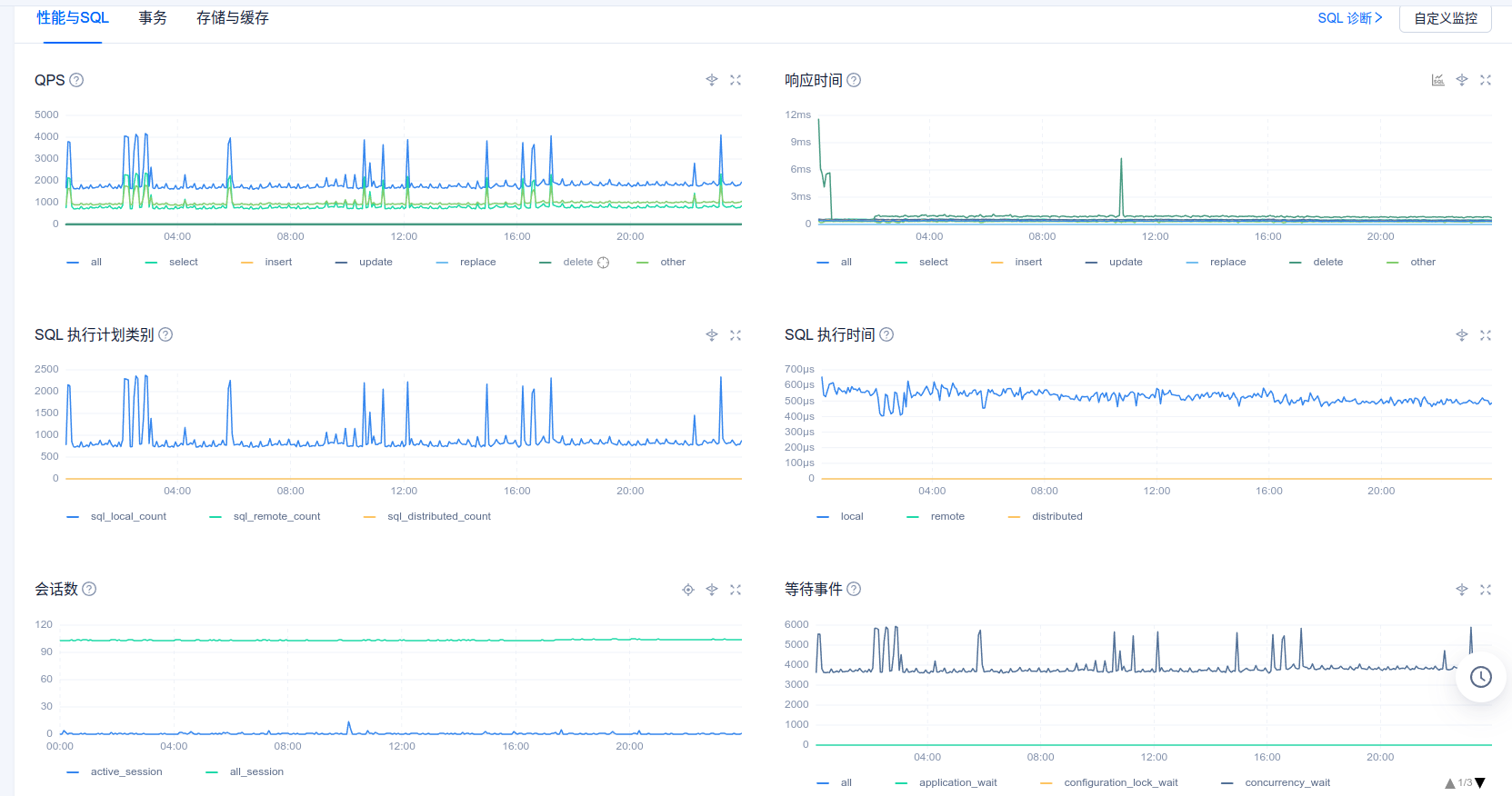
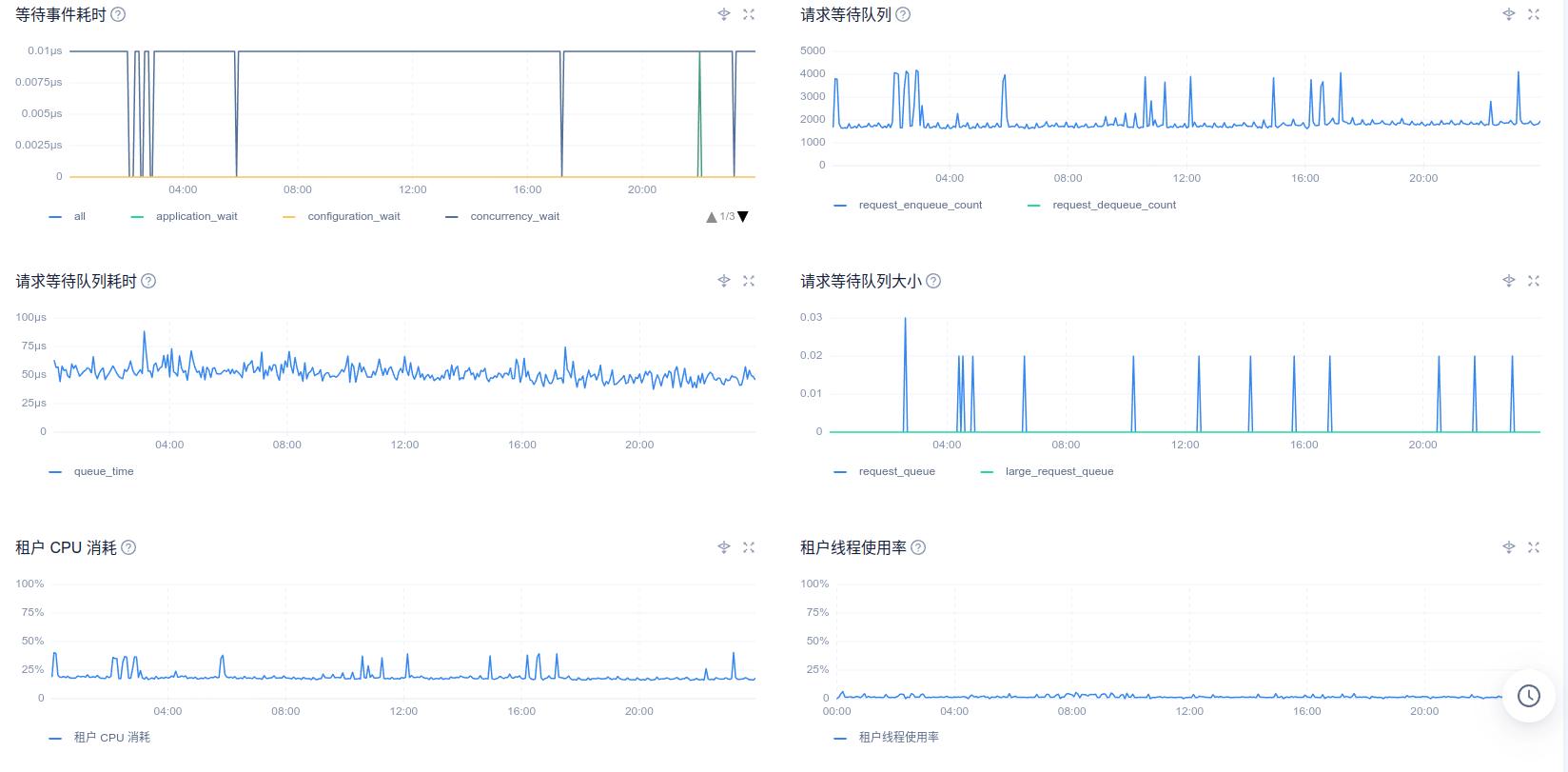
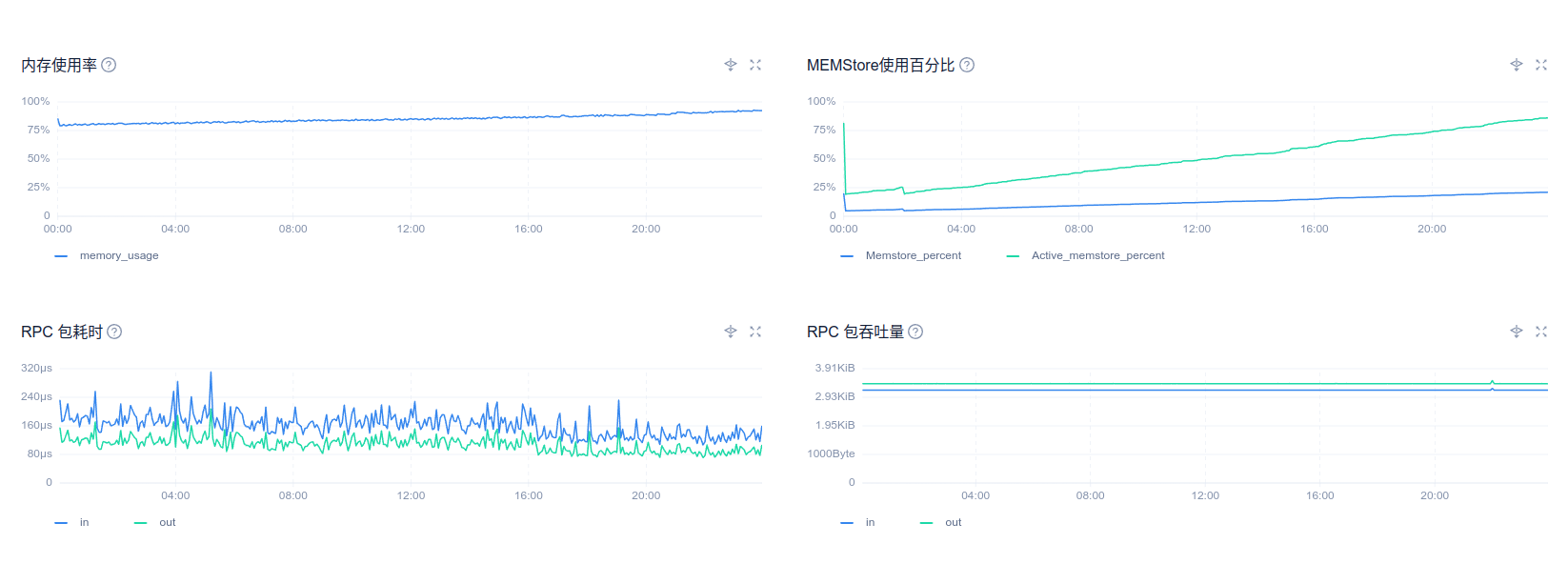
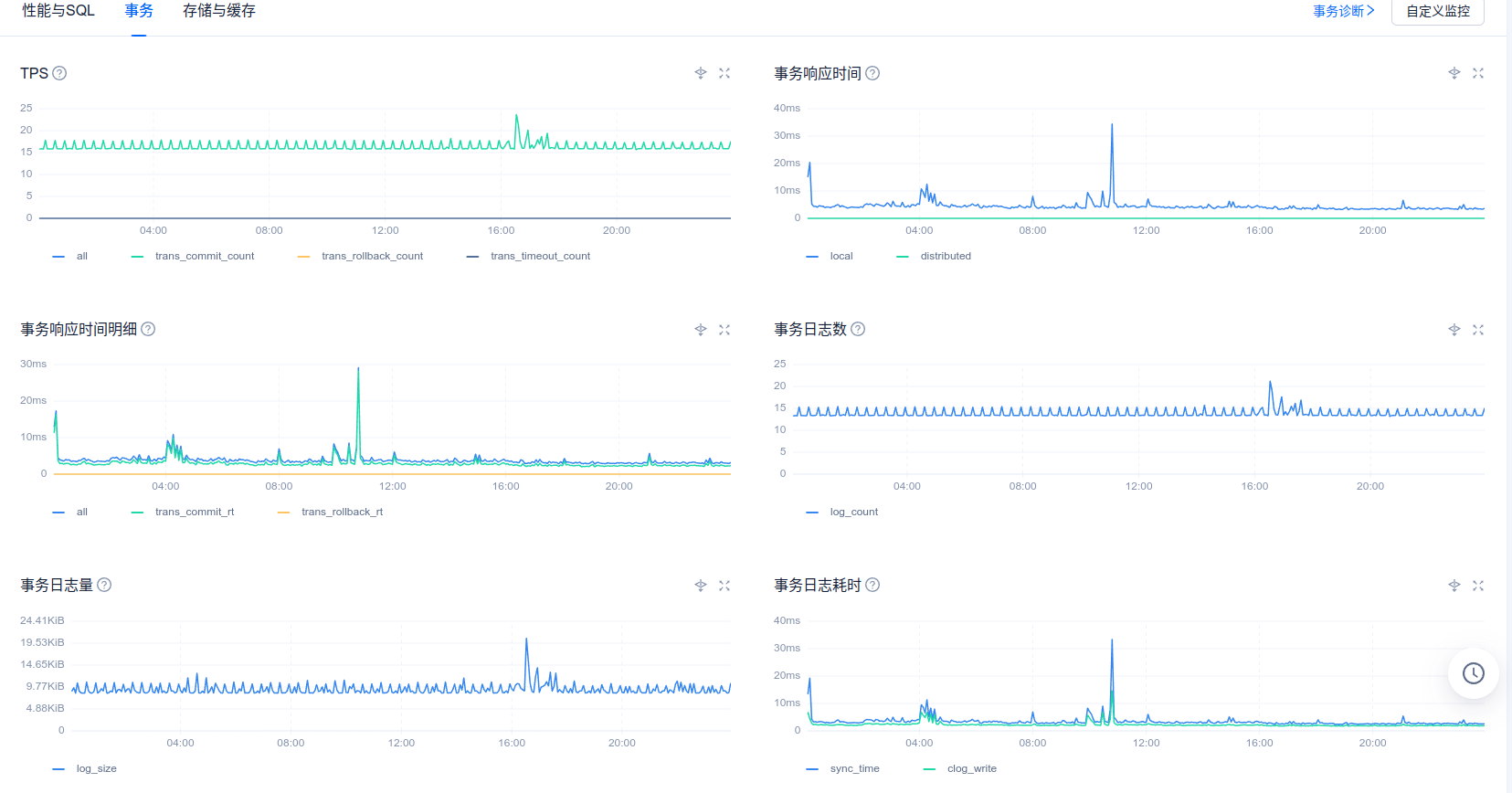
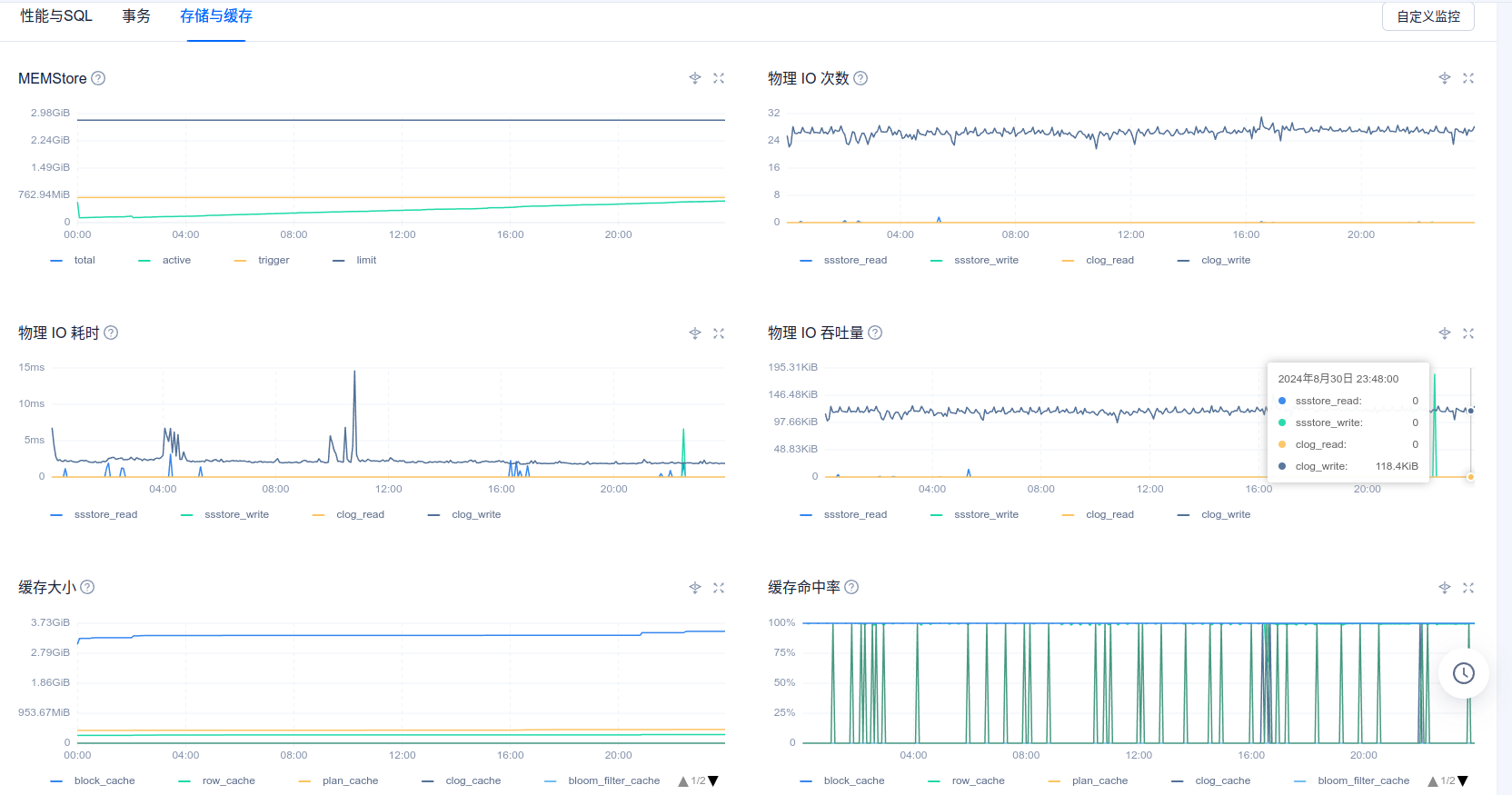
性能毛刺部分感觉不是跟出问题的时候完全匹配,另外这个inode数值是显示的0吗,我们另一个测试ocp显示主机的inode也是0
2 个赞
旭辉
#9
1.是否存在监控和告警数据不准的可能?
2.inode使用率一直显示为0 --看起来是inode使用率低的时候使用率被ocp计算为0了
这两个问题我联系ocp老师看下
2 个赞
旭辉
#11
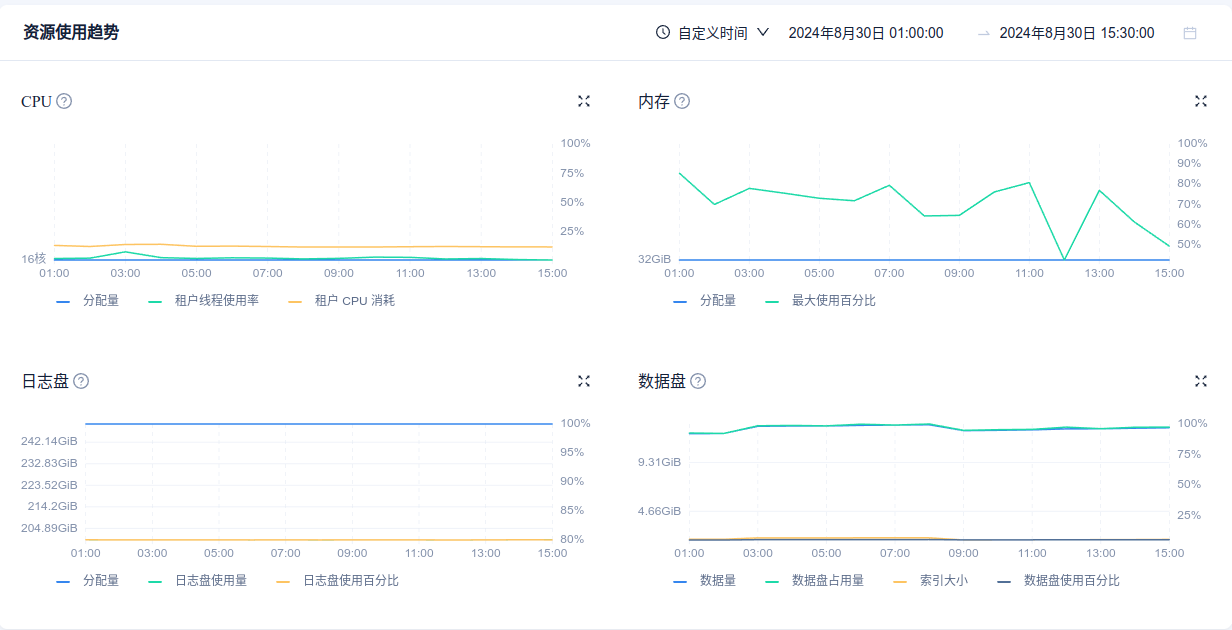
麻烦再看下告警时 ocp_monitor租户的资源水位情况,截图发下
2 个赞
旭辉
#13
磁盘使用率几乎100%,可能会影响ocp_monitor租户数据库运行,扩容后再观察下是否有此现象
2 个赞
ootoo
#14
好的,我们先扩展下日志配额,日志目前是分配的250G,然后按上图是使用了80%,并且一直在这个水位,感觉是被限制了。
数据盘分配了几十G的,并且做了自动扩展,看图使用百分比还应该不高
2 个赞
碰到了同样的问题,ocp同时报出两个集群的inode使用率高,登录上去查看均很低。数据盘和日志盘使用率最高不到80%
1 个赞
不处理,一会儿就报恢复。这个是bug吧,有办法处理吗
1 个赞
旭辉
#20
可以先屏蔽掉,如果ocp_monitor租户的资源情况没有问题,麻烦发下告警时的 monagent.log(告警节点的),ocp-server.log
1 个赞
用promethus关联ocp,在promethus用round(100 - 100 * sum(node_filesystem_files_free{@LABELS}) by (@GBLABELS) / sum(node_filesystem_files{@LABELS}) by (@GBLABELS))查询
报警的主机inode使用率也都远在80以下