rocH
2024 年8 月 28 日 16:05
#1
【 使用环境 】生产环境
为了用上从副本的机器性能,obproxy,设置了优先读从副本,参数如下
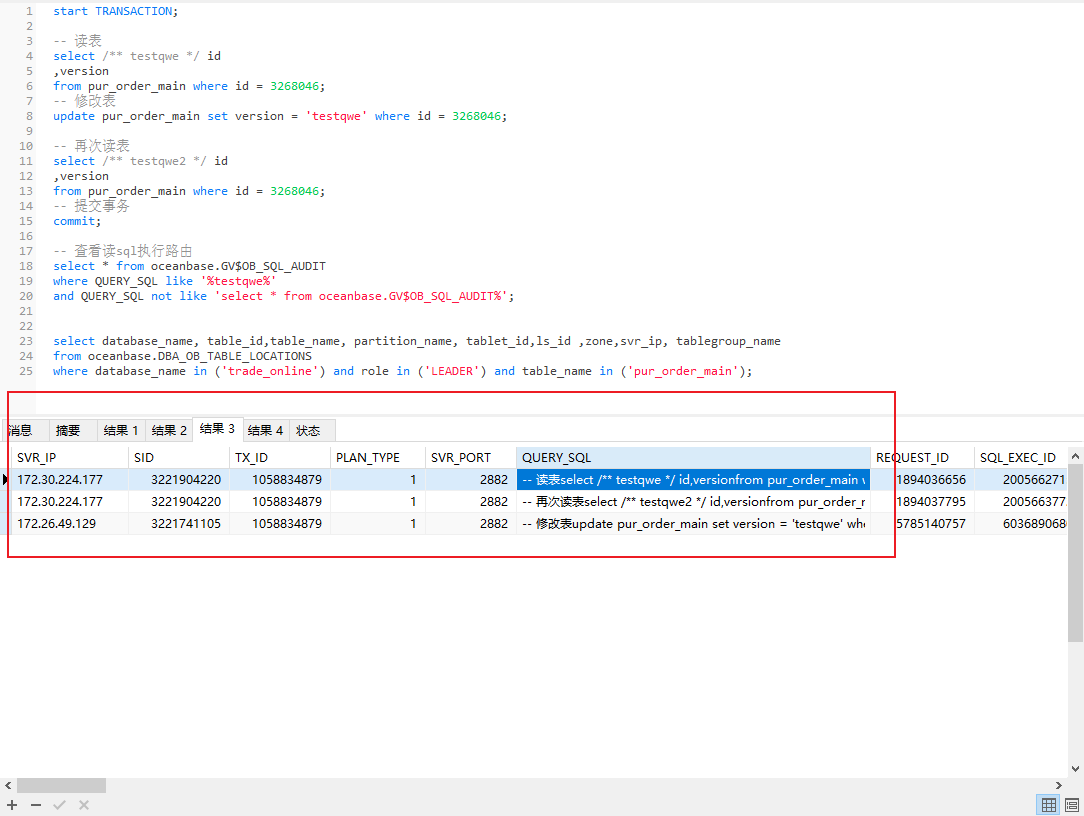
事务数据一致性测试:
– 读表
– 再次读表
– 提交事务
– 查看读sql执行路由GV$OB_SQL_AUDITGV$OB_SQL_AUDIT%’
发现2次读,都是路由到了从副本进行读。开启事务无法保证数据一致性。
rocH
2024 年8 月 28 日 16:14
#5
这个需要每个sql都 设置吗。
辞霜
2024 年8 月 28 日 16:23
#6
4 个赞
rocH
2024 年8 月 29 日 15:55
#8
所有表放到一个表组里面,只是我们第一期的迁移做法。
但是我看了下,如果设置了primary_zone=‘zone1’. 后续要迁移表的主副本到其他zone。没有什么好的解决方案。
所以就通过表组来控制, 先将所有表放到一个表组里面,来避免跨机查询的问题。
1 个赞
恩,用意我理解了。
还需要个关键信息,这个事务里的表的实际主副本位置。你发下下面这个 SQL 结果(换成你的库/schema名和表名)
select database_name, table_id,table_name, partition_name, tablet_id,ls_id ,zone,svr_ip, tablegroup_name
from DBA_OB_TABLE_LOCATIONS
where database_name in ('TPCC') and role in ('LEADER') and table_name in ('BMSQL_ITEM','BMSQL_WAREHOUSE');
如果是 mysql 租户,DBA_OB_TABLE_LOCATIONS 就是 oceanbase.DBA_OB_TABLE_LOCATIONS ;如果是 oracle 租户,DBA_OB_TABLE_LOCATIONS 就是 sys.DBA_OB_TABLE_LOCATIONS 。
2 个赞
rocH
2024 年8 月 30 日 14:48
#11
obpilot:
select database_name, table_id,table_name, partition_name, tablet_id,ls_id ,zone,svr_ip, tablegroup_name
from DBA_OB_TABLE_LOCATIONS
where database_name in ('TPCC') and role in ('LEADER') and table_name in ('BMSQL_ITEM','BMSQL_WAREHOUSE');
之前忽略了一个问题,prod_s_info表是个复制表。测试可能不正确。
1 个赞
rocH
2024 年8 月 30 日 17:36
#12
emm。还是发生了一致性问题。
目前生产上已经出现了这种数据不一致导致的问题了···
1 个赞
rocH
2024 年8 月 30 日 19:34
#14
for(int i = 0; i < 1000 ;i++){
执行过程中,由于查询的是从副本数据,不能保证事务一开始读到的是最新数据。
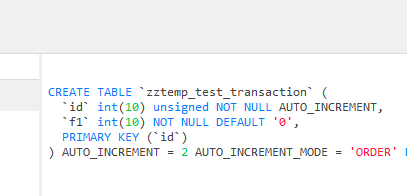
测试代码如下:
表结构
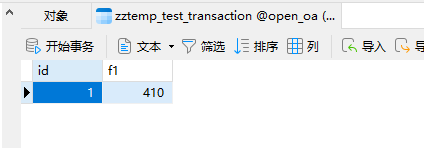
循环1000遍。
最终f1 = 410.
因此读写分离模式下, 即使开始事务,最终也无法保证数据一致性。
计划从应用层面上解决这个问题;
你这是错误的用法。OB 事务的读一致性取决于 事务中的第一条语句 。
如果第一条是 INSERT/UPDATE/DELETE,或者 SELECT FOR UPDATE,那本次事务就是强一致性的。SELECT,就取决于该语句的 弱一致性读 设置。因为你全局 设置了 弱一致性读,那么第一条语句也就是 弱一致性读 的。
此外,即使OB保证了事务内的强一致性,你这种用法仍然是错的。事务提交之后 ,又需要 SELECT 查询某些数据。如果查询的数据对前面更新的数据有业务依赖,即使没有开启事务,也是不应该 走弱一致性读的。
比较合理的读写分离设计目标是这样的:
如果开启了事务,就要确保强一致性。
如果当前线程之前已经开启过事务,那么该线程(及其 异步子线程)接下来的所有数据库查询,都应该优先保证强一致性(除非明确可以弱一致性)【线程复用时,记得 ThreadLocal 状态重置】。
有些对一致性要求较高的场景(比如 交易前的用户资金检查),即使没开启过事务,这次查询也应该优先保证强一致性。
对一些数据一致性要求不高的统计查询(这些也最容易产生慢查询,耗费资源),就可以强制开启弱一致性读(哪怕该线程之前已经执行过事务)。
我们建议的实现思路是:不要 全局开启弱一致性读。而是在程序中定义两个数据源,再自己实现 Spring 提供的动态数据源接口org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource,检测到 @Transactional 注解 或 之前已经开启事务,或 满足其他自定义条件 就访问 主库 数据源,否则访问 从库 数据源。
从库 可以配置一个只读账号,然后在 JDBC URL 参数里面加上 &sessionVariables=ob_read_consistency=WEAK 即可,亲测可用。
3 个赞
13 楼的回答已经指出一些问题,我再补充一下这段代码在高并发下的问题。
当在ob里开启了全局弱一致性读时,由于这个select 是在 update 之前,select 可以独立路由。还用了弱一致性读,同样也不会被update 阻塞,也不会阻塞update。有同样的问题。这里也确实如上面所说不适合读写分离。
如果事务中update 后面还有一次那个 select 才提交事务,那么这个 select 在这里依然是弱一致性读。这个在业务上也是有问题的。在事务里,一般要求的是写后要求立即能读,即强一致性读。
odp 4.2.2 参数 enable_transaction_internal_routing 默认是 true,事务中 sql都独立路由。只要将 租户 primary_zone设置为 random,适当结合表分组控制一些表的主副本集中一起 ,全部的数据主副本还是分散在多个节点,那么业务读写基本也是分散,也能实现多个节点同时提供读写服务,或者说实现了完全的分布式。那么在这种情形下,“读写分离”必要性就不是 那么大了。
读写分离使用场景一般是那些复杂查询比较集中的报表业务,专门为它配置一个 开启了 弱一致性读的 ODP ,并且专门给一个备副本或者只读副本用于集中式读。对于主要交易业务使用的ODP还是默认配置(不开弱一致性读)。
1 个赞
rocH
2024 年9 月 2 日 09:20
#18
是的。这里只是模拟历史代码的思路。
rocH
2024 年9 月 2 日 09:27
#19
这里只是模拟一下,历史代码中,循环执行事务的场景。
有并发的情况的更新,都是 select for update。 或者并发的数据行不相同。
1 个赞
除非你们的慢查询特别多,或者查询消耗特别多的资源,那么其实并不建议使用 单一主副本 + 读写分离。
主要考虑到以下几点:
OB 自带请求超时机制,超过 10s(默认阈值,可调整) 的查询就会被中止,不会超长时间的消耗资源(部分慢查询建议通过 SQL Hint 的方式自定义超时时间)。
OB 有慢查询抑制机制,当CPU资源不足,快查询和慢查询产生争用时,慢查询将让出调度优先权,可将慢查询的CPU占用限制在最多30%(默认阈值,可调整)以内。这在一定程度上能够抑制 慢查询 的资源占用,避免 正常的快查询 也被“株连九族”。
查 从库,会有 数据一致性 的延迟问题,有可能读到脏数据(数据库CPU、磁盘IO 负载高时,还是比较可能出现),除非你的业务能够容忍。
如果你有 30 个数据表,使用 OB 最常见的3副本集群,OB 大概率会将 每10表 主副本 放在 不同的 Zone。比如【表1~10】 的主副本在Zone 1,【表11~20】 的主副本在Zone 2,【表21~30】 的主副本在Zone 3。默认是 强一致性读,对应表的数据读写也都访问的是其 主副本 所在的 Zone。这样本身也是相对比较均衡的。它并不是像 MySQL 那样——所有数据表的 写入都是在一个主节点。有些大数据表可以采用分区表,OB会按照表分区数量进行负载均衡(比如创建16个分区,每个Zone会各分配5个左右)。
至于跨Zone的处理开销,这个实测其实影响不大,而且我们还可以创建表组,将需要关联查询、需要在一个事务中进行处理的多个数据表放入同一个表组中。
1 个赞
rocH
2024 年9 月 2 日 10:56
#21
是个老业务库了。所有模块都在一个库里面,从mysql迁移到oceanbase。总共1400+表。
一开始做的迁移规划,也是按照最标准的将主副本打散到3个zone上。
后续我们还会做第二期的表分区改造,一个个业务模块改造为分区表,并将表从这个大表组里面移除来。将主副本打散到3个zone里面。这样最终就能实现只需要一个obproxy: 读主副本。
你可以拆分成几个小的表组,某些表在业务上需要联表查询或进行事务处理,就放在一个表组。数量 来进行负载均衡的。
但按照表分区数量进行负载均衡不是一个好主意。因为某些表数据量特别大、读写特别多,使用的资源负载就会很多;有些表只是存几条配置数据,基本上没什么开销。
1 个赞
辞霜
2024 年9 月 6 日 15:10
#23
老师,您那边可以复现一下帮忙确认查询语句的sql_audit里的CONSISTENCY_LEVEL字段,如果确认是弱读,那就符合预期读到了一个旧版本数据。如果非弱读提供一下多次查询截图和完整步骤。包括完整的事务的observer.log日志