【 使用环境 】生产环境
【 使用版本 】oceanbase-3.1.5-CE
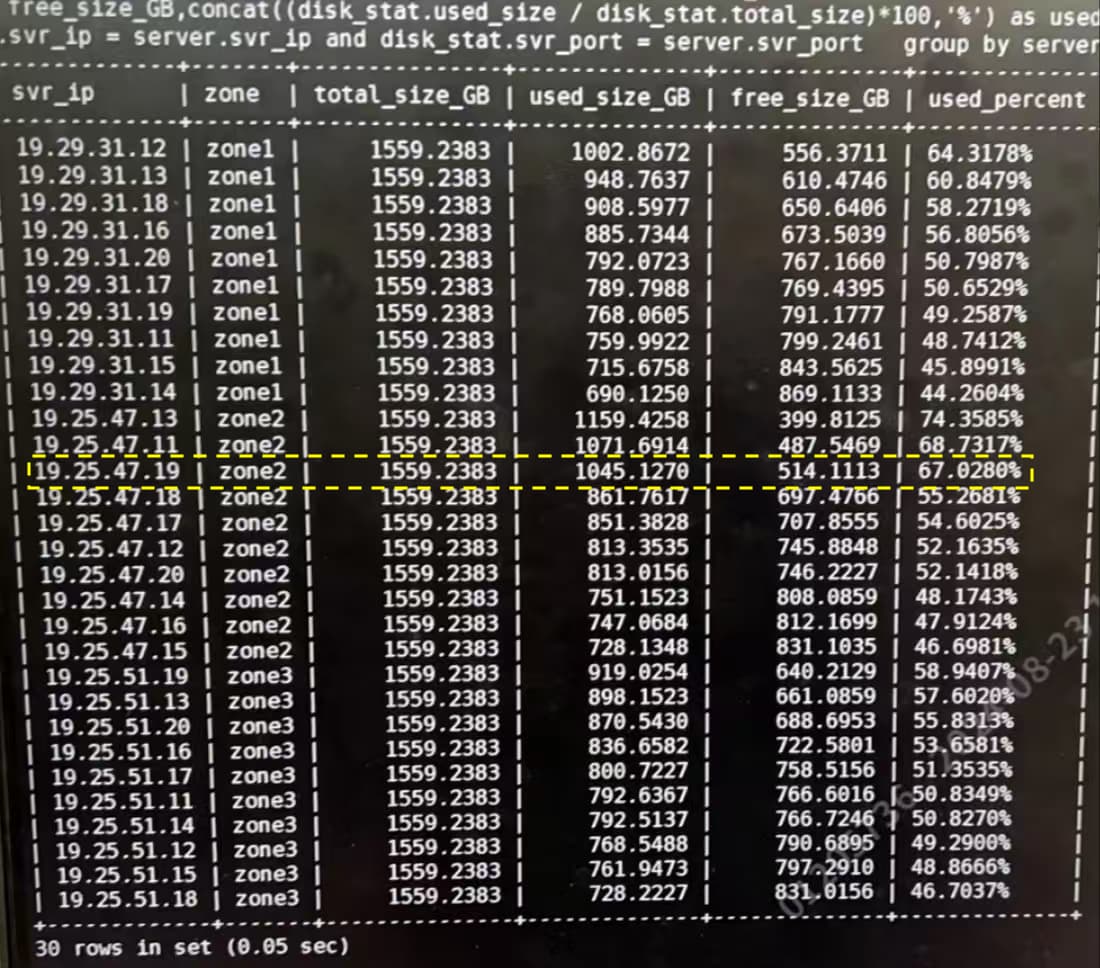
【问题描述】2024年8月23日 00:35收到自动告警,存在运行在容器中的observer节点(ip:19.25.47.19)磁盘使用率突然暴增至97%,持续一段时间(00:47)后自动回落
【相关日志】从对应时间的observer日志中,粘贴了部分相关日志,请社区的专家帮忙看看解答解答
[2024-08-23 00:35:58.637655] WARN [STORAGE] process (ob_partition_migrator.cpp:12317) [512][460][YB4213192F13-000618EE1AAC902C] [lt=14] [dc=0] failed to acquire sstbale(ret=0, dest_table_key={table_type:7, pkey:{tid:1100611139457202, partition_id:10, part_cnt:0}, table_id:1100611139457204, trans_version_range:{multi_version_start:1724341214314056, base_version:1724256624514108, snapshot_version:1724343000935082}, log_ts_range:{start_log_ts:1724256624514108, end_log_ts:1724343000935082, max_log_ts:1724343000935082}, version:"0-0-0"})
[2024-08-23 00:35:58.716302] WARN [STORAGE] acquire_sstable (ob_partition_migrator.cpp:12385) [505][446][YB4213192F13-000618EE1AAC902C] [lt=5] [dc=0] failed to acquire sstable(ret=-4018, dest_table_key={table_type:7, pkey:{tid:1100611139457202, partition_id:10, part_cnt:0}, table_id:1100611139457204, trans_version_range:{multi_version_start:1724343000935082, base_version:1724343000935082, snapshot_version:1724343031743112}, log_ts_range:{start_log_ts:1724343000935082, end_log_ts:1724343031743112, max_log_ts:1724343031743112}, version:"0-0-0"})
[2024-08-23 00:35:58.716343] WARN [STORAGE] process (ob_partition_migrator.cpp:12317) [505][446][YB4213192F13-000618EE1AAC902C] [lt=36] [dc=0] failed to acquire sstbale(ret=0, dest_table_key={table_type:7, pkey:{tid:1100611139457202, partition_id:10, part_cnt:0}, table_id:1100611139457204, trans_version_range:{multi_version_start:1724343000935082, base_version:1724343000935082, snapshot_version:1724343031743112}, log_ts_range:{start_log_ts:1724343000935082, end_log_ts:1724343031743112, max_log_ts:1724343031743112}, version:"0-0-0"})
[2024-08-23 00:35:58.773059] ERROR [STORAGE] check_disk_full (ob_store_file.cpp:860) [749][930][Y0-0000000000000000] [lt=10] [dc=0] disk is almost full(ret=-4184, required_size=0, required_count=0, free_count=86998, used_percent=90, calc_free_block_cnt=86998, calc_total_block_cnt=798330) BACKTRACE:0x9c5ff5e 0x9a33051 0x232dc60 0x232d87b 0x232d4c4 0x4882d2b 0x8a38b5f 0x8a08f5b 0x7f2c780 0x9be8cb7 0x34c5ccf 0x2d684b2 0x99e74e5 0x99e5ed2 0x99e298f
[2024-08-23 00:35:58.803671] WARN [STORAGE] generate_weak_read_timestamp (ob_partition_loop_worker.cpp:240) [1456][2321][Y0-0000000000000000] [lt=16] [dc=0] slave read timestamp too old(pkey_={tid:1100611139456442, partition_id:10, part_cnt:0}, delta_ts=8027887, readable_info={min_log_service_ts_:1724344550775772, min_trans_service_ts_:9223372036854775807, min_replay_engine_ts_:1724344550775772, generated_ts_:1724344558803657, max_readable_ts_:1724344550775771})
[2024-08-23 00:35:58.965531] WARN [STORAGE.TRANS] reset (ob_trans_define.cpp:1088) [1303][2036][YB4213192F13-000618EE4CDDC3D8] [lt=5] [dc=0] reset trans desc without release part ctx(*this={tenant_id:1001, trans_id:{hash:12963745167277084159, inc:2321310660, addr:"19.25.47.19:2882", t:1724344557836966}, snapshot_version:-1, trans_snapshot_version:-1, trans_param:[access_mode=1, type=3, isolation=1, magic=17361641481138401520, autocommit=0, consistency_type=0(CURRENT_READ), read_snapshot_type=2(PARTICIPANT_SNAPSHOT), cluster_version=12884967429, is_inner_trans=0], participants:[{tid:1100611139457399, partition_id:20, part_cnt:0}], stmt_participants:[], sql_no:4294967297, max_sql_no:4294967297, stmt_min_sql_no:4294967297, cur_stmt_desc:[stmt_tenant_id=1001, phy_plan_type=1, stmt_type=2, consistency_level=0, execution_id=7273548214, sql_id=652FFB38F44CFBA, trace_id=YB4213192F13-000618EE4CDDC3D7, is_inner_sql=0, app_trace_id_str=, cur_stmt_specified_snapshot_version=-1, cur_query_start_time=1724344557837348, is_sfu=0, is_contain_inner_table=0, trx_lock_timeout=-1], need_rollback:false, trans_expired_time:1724346357836859, cur_stmt_expired_time:1724387757767348, trans_type:0, is_all_select_stmt:false, stmt_participants_pla:{partitions:[{tid:1100611139457399, partition_id:20, part_cnt:0}], leaders:["19.25.47.19:2882"], type_array:[0]}, participants_pla:{partitions:[], leaders:[], type_array:[]}, is_sp_trans_exiting:false, trans_end:true, snapshot_gene_type:2, local_consistency_type:0, snapshot_gene_type_str:"NOTHING", local_consistency_type_str:"CURRENT_READ", session_id:3224875443, proxy_session_id:1377258430684109150, app_trace_id_confirmed:true, can_elr:false, is_dup_table_trans:false, is_local_trans:true, trans_need_wait_wrap:{receive_gts_ts:{mts:0}, need_wait_interval_us:0}, is_fast_select:false, trace_info:{app_trace_info:"", app_trace_id:""}, standalone_stmt_desc:{trans_id:{hash:0, inc:0, addr:"0.0.0.0", t:0}, tenant_id:0, stmt_expired_time:-1, trx_lock_timeout:-1, consistency_type:-1, read_snapshot_type:-1, snapshot_version:-1, is_local_single_partition:false, is_standalone_stmt_end:true, first_pkey:{tid:18446744073709551615, partition_id:-1, part_idx:268435455, subpart_idx:268435455}}, need_check_at_end_participant:false, is_nested_stmt:false, stmt_min_sql_no:4294967297, xid:{gtrid_str:"", bqual_str:"", format_id:1, gtrid_str_.ptr():"data_size:0, data:", bqual_str_.ptr():"data_size:0, data:"}, gc_participants:[]}, part_ctx_=0x7fbfa91a3910, lbt="0x9c5ff5e 0x8d9f163 0x8f9a7ff 0x7f982e7 0x5da5ca9 0x5da57f4 0x5da5580 0x42bc865 0x5887fd0 0x5d4d547 0x5d4e610 0x5d4e23e 0x96770c6 0x96a93f2 0x96a60d7 0x9d8e09c 0x948b31f 0x946a441 0x9489f7f 0x9468226 0x9468807 0x2d684b2 0x99e74e5 0x99e5ed2 0x99e298f")
---------
[2024-08-23 00:36:00.877907] WARN [STORAGE.REDO] append_log_head (ob_storage_log_struct.cpp:183) [494][424][YB4213192F13-000618EE1AAC902A] [lt=5] [dc=0] The buffer is not enough, (ret=-4024, capacity_=507904, pos_=506828, len=1428)
[2024-08-23 00:36:00.877926] WARN [STORAGE.REDO] append_log (ob_storage_log_struct.cpp:436) [494][424][YB4213192F13-000618EE1AAC902A] [lt=17] [dc=0] append log to buffer failed.(ret=-4024, trans_id=5864291, log_count_=356, subcmd=4294967329)
[2024-08-23 00:36:00.880336] WARN [STORAGE.REDO] append_log_head (ob_storage_log_struct.cpp:183) [494][424][YB4213192F13-000618EE1AAC902A] [lt=4] [dc=0] The buffer is not enough, (ret=-4024, capacity_=507904, pos_=506940, len=1428)
[2024-08-23 00:36:00.880347] WARN [STORAGE.REDO] append_log (ob_storage_log_struct.cpp:436) [494][424][YB4213192F13-000618EE1AAC902A] [lt=10] [dc=0] append log to buffer failed.(ret=-4024, trans_id=5864291, log_count_=711, subcmd=4294967329)
------------------------------
[2024-08-23 00:48:02.244632] WARN [SHARE] remove (ob_partition_table_proxy.cpp:2125) [1310][2050][YB42131D1F14-000618F1E79E463C] [lt=5] [dc=0] expected deleted single row(affected_rows=0, sql=DELETE FROM __all_tenant_meta_table WHERE tenant_id = 1001 AND table_id = 1100611139457312 AND partition_id = 22 AND svr_ip = '19.25.47.19' AND svr_port = 2882)
从合并记录看,23日的合并起始时间为00:10, 结束时间为00:21,合并状态正常
目前看,所有节点的状态均为active,异常发生的节点磁盘使用率已经恢复到67%左右,与其他节点相差不大。