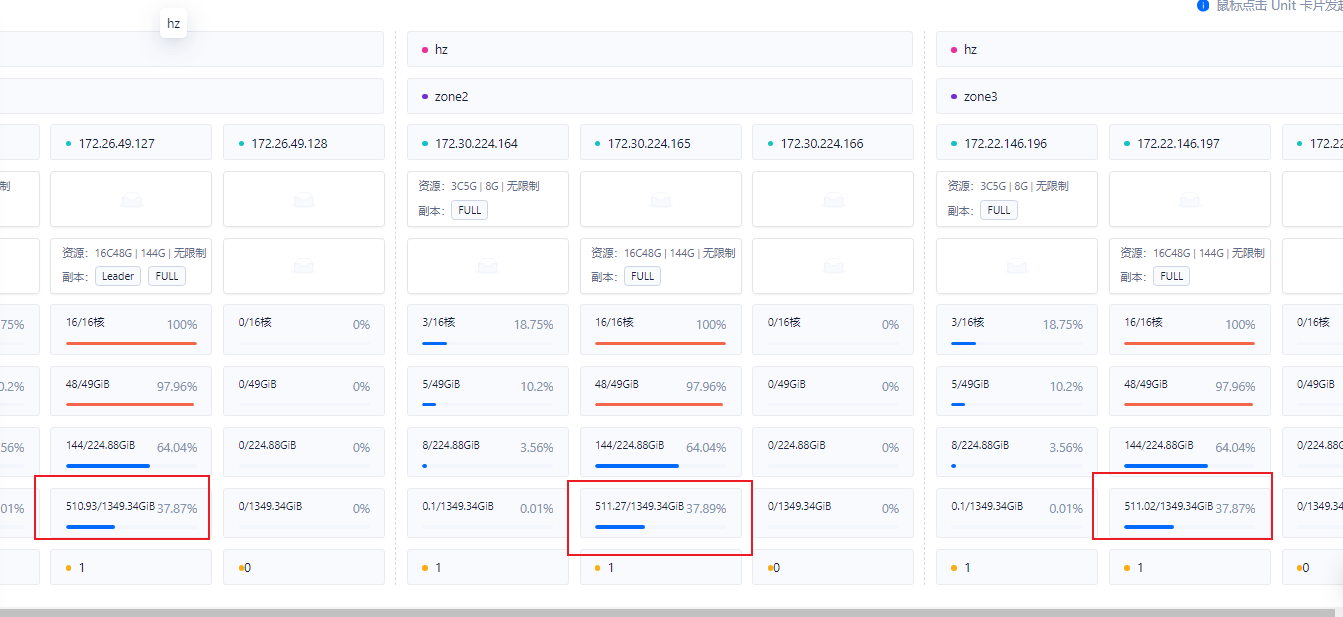
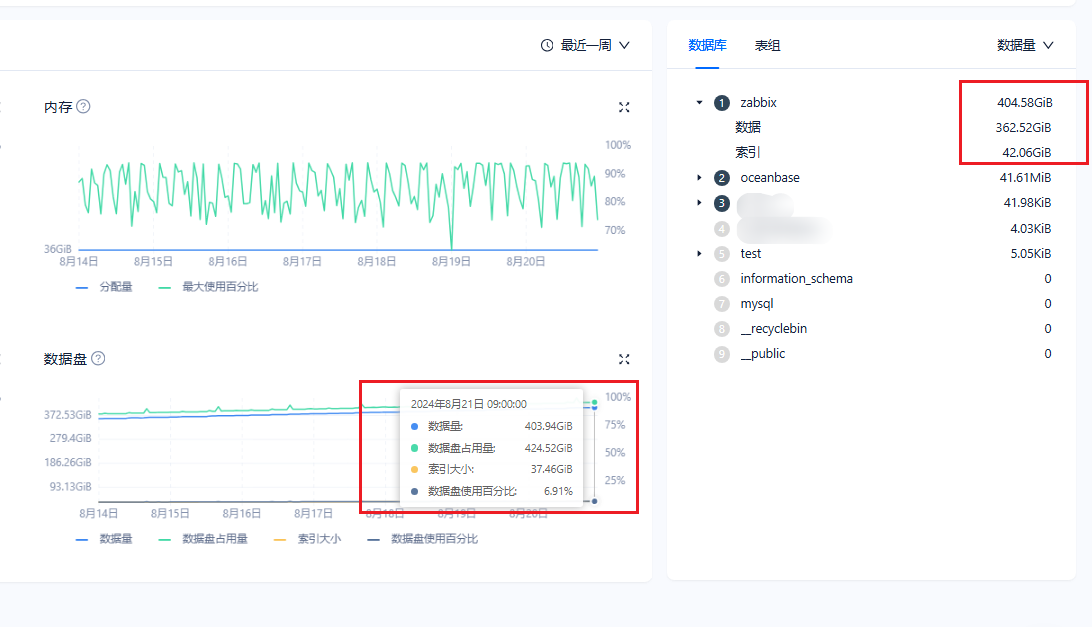
OB 的 文件系统上占用的空间 就是 sstable 目录和 clog 目录的大小,这个大家都熟悉了。
OB 的内部实际使用空间 就更有点绕了。这是 LSM Tree 原理决定的。导入大表数据时,内存转储生成很多中间版本的 sstable,实际使用空间会增长。此外,大表的 offline ddl 时也会生成临时数据,如果落盘了,实际使用空间会增长。当OB 合并之后中间版本数据都没了,实际使用空间又会下降。offline ddl 结束了,临时使用空间也释放了,实际使用空间也会下降。
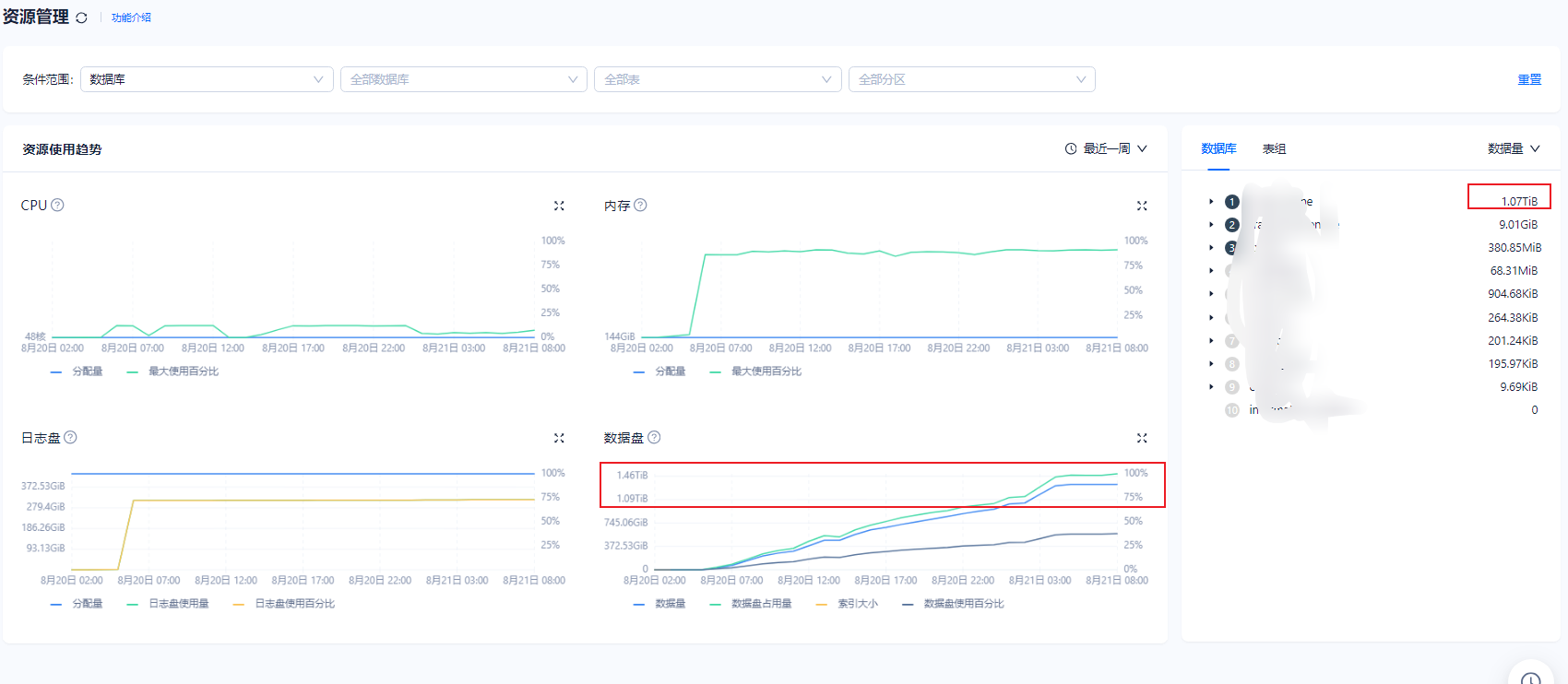
推测这个数据取自下面这个 SQL。
select svr_ip, round(total_size/1024/1024/1024) total_size_gb ,round(used_size/1024/1024/1024) used_size_gb , round(free_size/1024/1024/1024) free_size_gb ,round(allocated_size/1024/1024/1024) alloc_size_gb
from oceanbase.__all_virtual_disk_stat;
这个表应该不是实时统计的,已经很接近了。
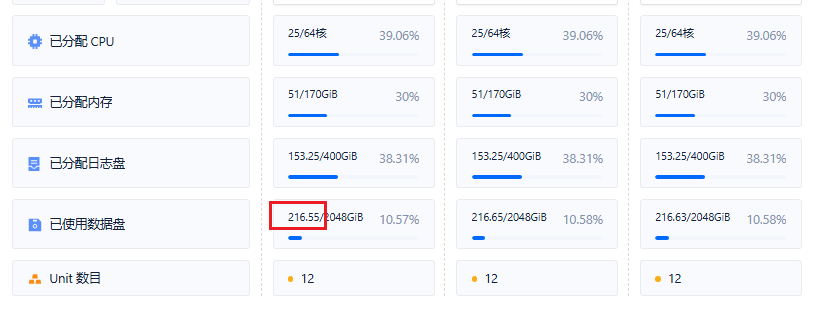
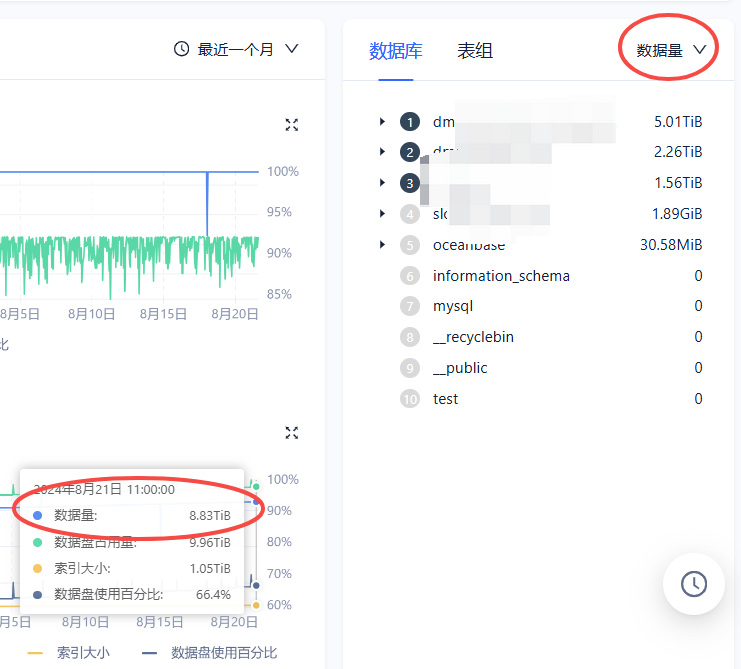
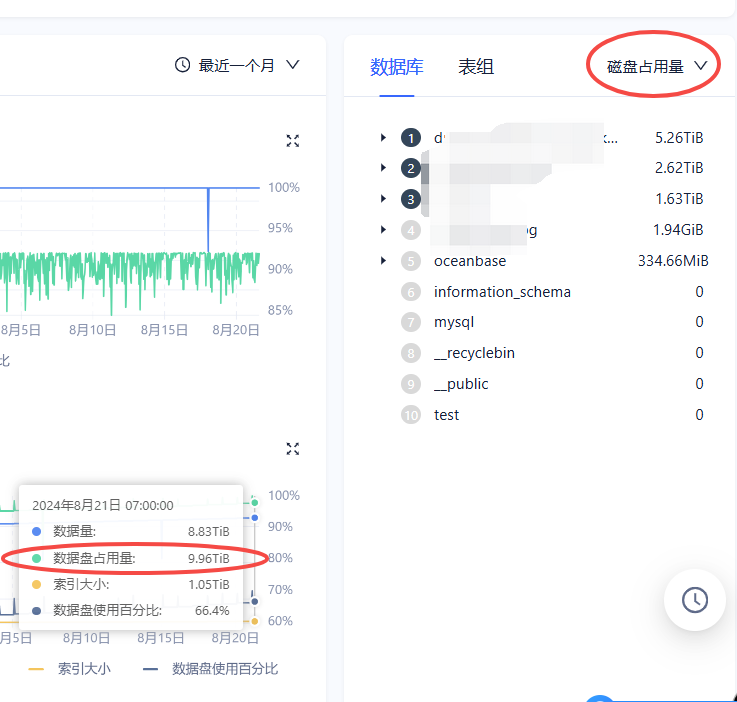
另外在租户的资源管理页面里数据库的大小统计结果
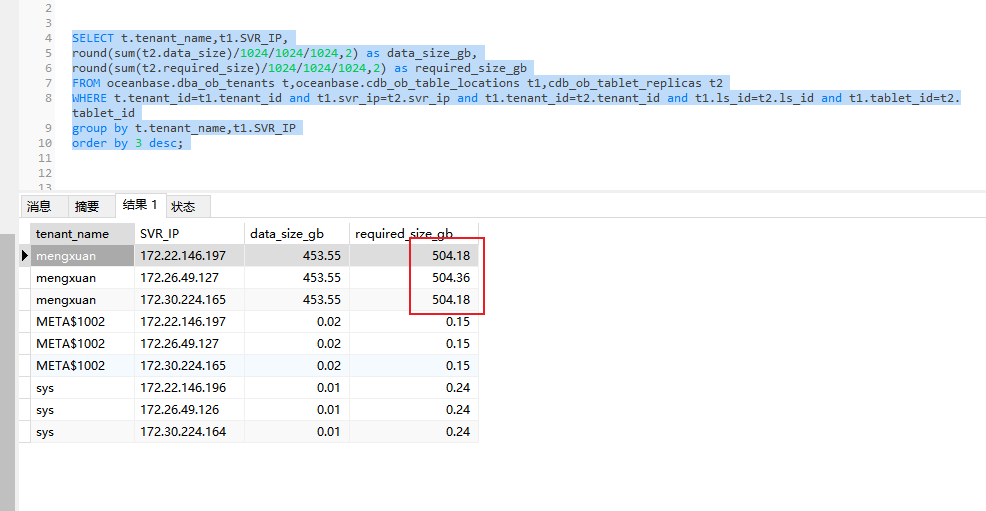
推测是取自下面 SQL 中表。
SELECT r.svr_ip, round(sum(r.data_size)/1024/1024/1024,2) data_size_gb , round(sum(r.required_size)/1024/1024/1024,2 ) required_size_gb
from oceanbase.DBA_OB_TENANTS t join oceanbase.CDB_OB_TABLE_LOCATIONS l on (t.tenant_id=l.tenant_id)
join oceanbase.cdb_ob_tablet_replicas r on (l.tenant_id=r.tenant_id and l.tablet_id=r.tablet_id and l.svr_ip=r.svr_ip)
where 1=1
and t.tenant_name='ten007'
-- and l.role in ('LEADER')
group by r.svr_ip with ROLLUP
order by r.svr_ip ;
其中表 CDB_OB_TABLE_LOCATIONS 的字段 table_type 会标明这个 分区是 表还是索引。
这个表估计也是合并后才更新的,不一定包含中间版本的 sstable 。如果要统计当前最真实的数据容量,还是下面这个 SQL。
WITH table_locs AS (
SELECT
t.tenant_id,
t.database_name,
t.table_id,
t.table_name,
t.table_type tablet_type,
t.tablet_id,
REPLACE(concat(t.table_name,':',t.partition_name,':',t.subpartition_name),':NULL','') tablet_name,
t.tablegroup_name,
t.ls_id,
t.ZONE,
t.ROLE,
t.svr_ip
FROM
oceanbase.CDB_OB_TABLE_LOCATIONS t
WHERE
t.data_table_id IS NULL
UNION
SELECT
i.tenant_id,
i.database_name,
i.table_id,
t.table_name,
i.table_type tablet_type,
i.tablet_id,
REPLACE(
REPLACE(concat(i.table_name,':',i.partition_name,':',i.subpartition_name) ,concat('__idx_', i.data_table_id, '_'),'')
,':NULL',''
) tablet_name,
i.tablegroup_name,
i.ls_id,
i.ZONE,
i.ROLE,
i.svr_ip
FROM
oceanbase.CDB_OB_TABLE_LOCATIONS i
INNER JOIN oceanbase.__all_virtual_table t ON
( i.tenant_id = t.tenant_id
AND i.data_table_id = t.table_id )
WHERE i.data_table_id IS NOT NULL
)
SELECT
t.svr_ip,
-- group_concat(s.table_type,',') tablet_types,
round(sum(s.size)/1024/1024/1024,2) size_gb
FROM
table_locs t JOIN oceanbase.GV$OB_SSTABLES s
ON (t.tenant_id=s.tenant_id AND t.ls_id=s.ls_id AND t.svr_ip=s.svr_ip AND t.tablet_id=s.tablet_id)
WHERE 1=1
-- AND t.tenant_id = 1022
AND s.table_type NOT IN ('MEMTABLE')
-- AND t.ROLE IN ('LEADER')
GROUP BY
t.svr_ip
WITH ROLLUP
ORDER BY
t.svr_ip;
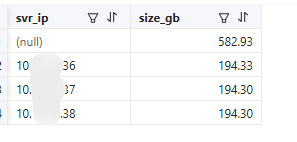
这个虽然是最真实的,但是如果仔细看又会发现这里统计出来的 194G 比前面 216G 还要小。我推测因为视图 gv$ob_sstables 它只是统计 它这个 sstable 的数据容量大小,并不是说 这个 sstable 数据结构占用的存储大小。 在这个例子里实际大小还是要以前面那个 216G 为准。但是,如果当前正在导入大批量的数据,这里的统计大小就比前面那个统计结果要大出很多,而实际的存储使用空间只会更大。
所以,一个 OB 集群平常看实际空间会有三个值,肯定不会完全一样,如果差别不是很大,说明业务写增量数据也算不上太大。如果是 ODS 业务,这个差异会有一些。
那运维要做的就是尽量确保剩余空间充足。要预留一定比例。具体多大比例取决于总的数据盘大小和当前实际数据大小规模。
否则,你会碰到 server out of disk 报错。