ALTER SYSTEM
RECOVER TABLE infodb.tbl1,infodb.tbl2
TO TENANT oracle001
FROM 'file:///data/nfs/backup/data,file:///data/nfs/backup/archive'
UNTIL TIME='2023-09-30 00:00:00'
WITH 'pool_list=restore_pool'
REMAP TABLE infodb.tbl1:newtbl
REMAP TABLEGROUP tg1:newtg1
REMAP TABLESPACE ts1:newts1;
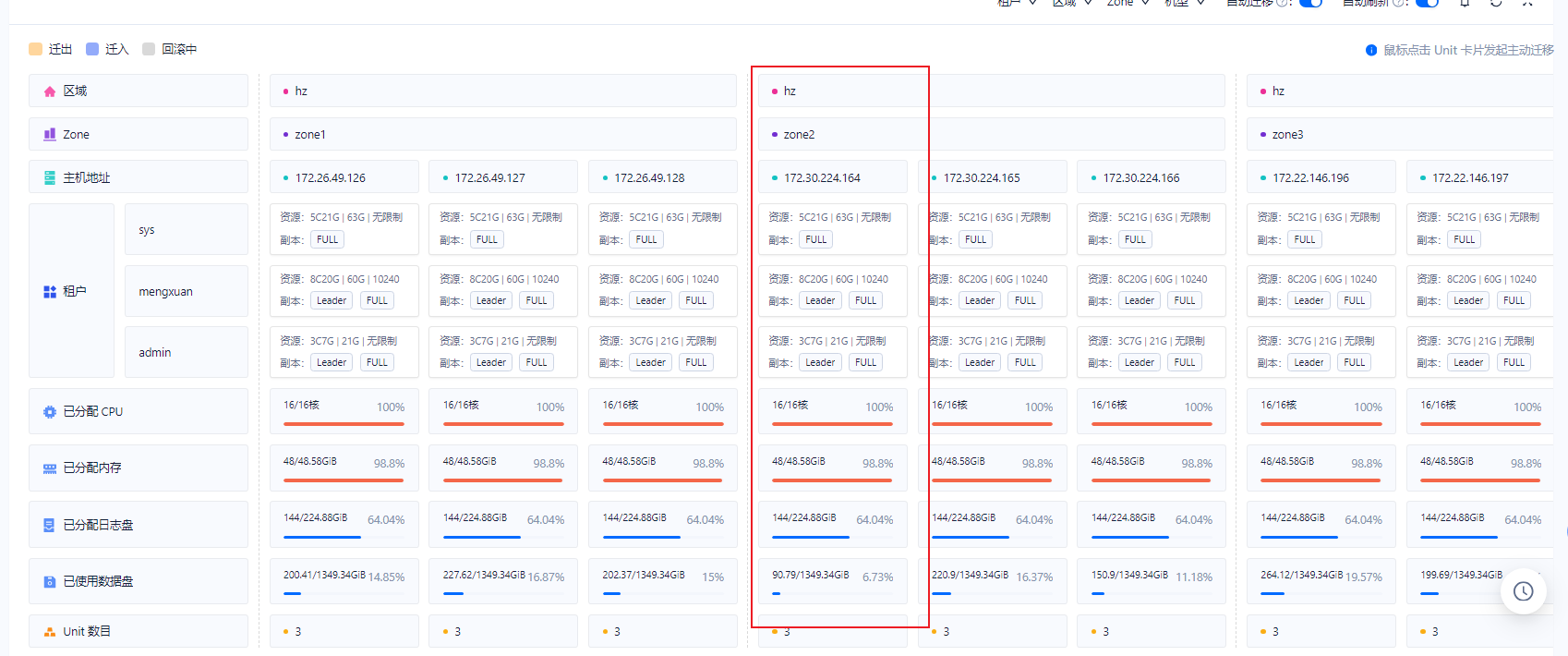
recover和restore有什么不一样吗
我执行的这个命令。直接从oss备份数据恢复租户
ALTER SYSTEM RESTORE dest_tenant_name FROM uri WITH ‘restore_option’ [WITH KEY FROM ‘backup_key_path’ ENCRYPTED BY ‘password’] [DESCRIPTION description];
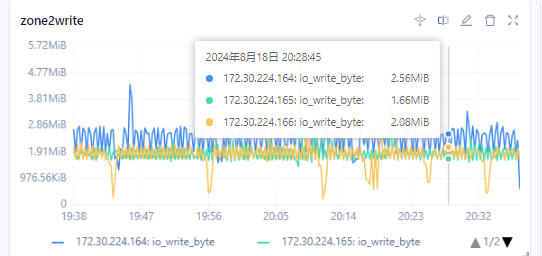
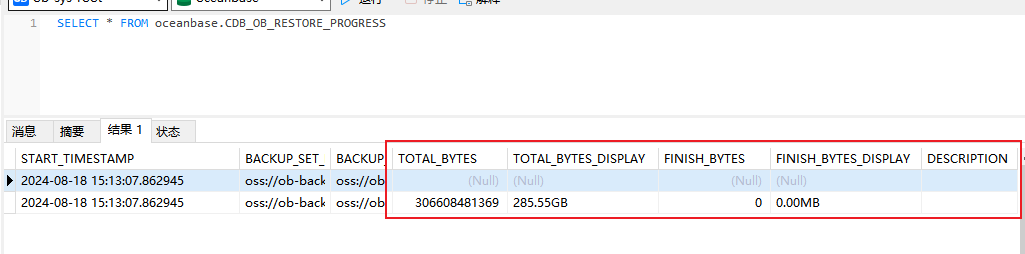
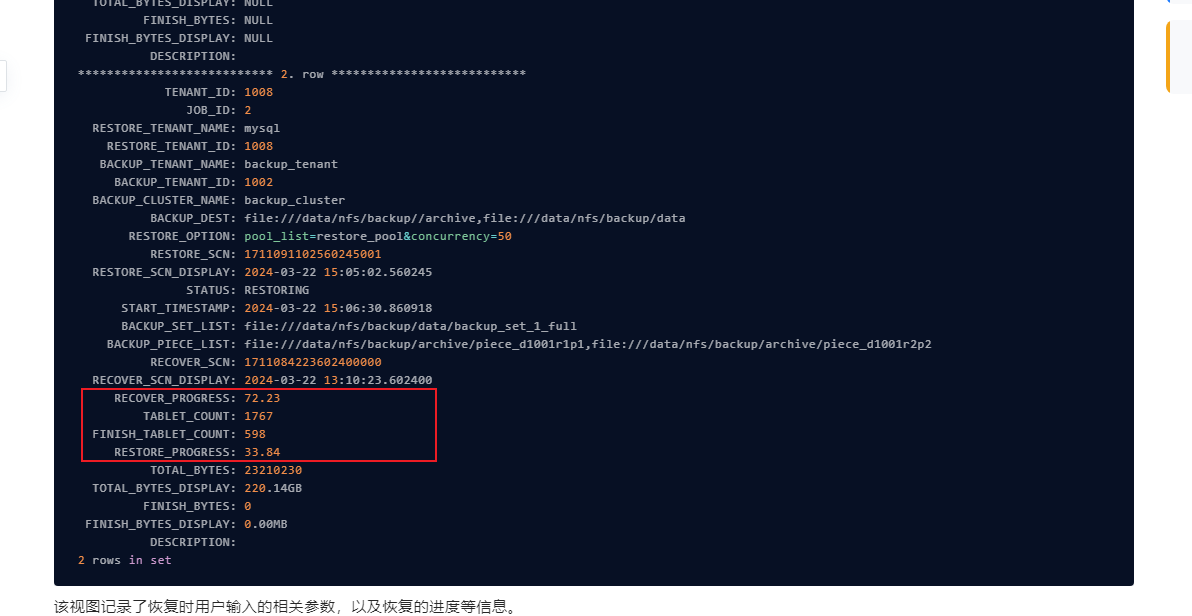
2024-08-18 15:13:07.862945重新执行了一遍恢复
命令如下:
ALTER SYSTEM RESTORE mysql FROM ‘oss://oceanbase-test-bucket/backup/data/?host=.aliyun-inc.com&access_id=&access_key=,oss://oceanbase-test-bucket/backup/archive/?host=.aliyun-inc.com&access_id=&access_key=’ UNTIL TIME=‘2024-08-16 00:30:00’ WITH ‘pool_list=restore_pool’