

【 使用环境 】测试环境
【 OB or 其他组件 】
【 使用版本 】4.2
【问题描述】清晰明确描述问题
【复现路径】问题出现前后相关操作
【附件及日志】
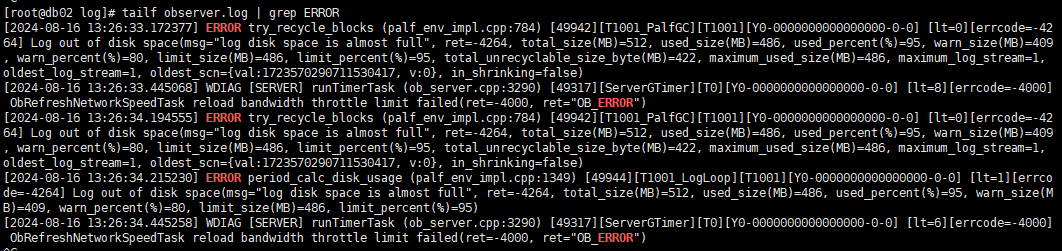
日志文件满,启动报错
ERROR issue_dba_error (ob_log.cpp:1891) [21855][T1002_MDS_MINI_][T1002][YB427F000001-00061FC2CCC932B3-0-0] [lt=0][errcode=-4388] Unexpected internal error happen, please checkout the internal errcode(errcode=-4184, file=“ob_block_manager.cpp”, line_no=304, info=“Failed to alloc block from io device”)
[2024-08-16 09:57:11.272515] WDIAG [SERVER] runTimerTask (ob_server.cpp:3290) [20974][ServerGTimer][T0][Y0-0000000000000000-0-0] [lt=8][errcode=-4000] ObRefreshNetworkSpeedTask reload bandwidth throttle limit failed(ret=-4000, ret=“OB_ERROR”)
[2024-08-16 09:57:11.696318] ERROR try_recycle_blocks (palf_env_impl.cpp:784) [21604][T1001_PalfGC][T1001][Y0-0000000000000000-0-0] [lt=0][errcode=-4264] Log out of disk space(msg=“log disk space is almost full”, ret=-4264, total_size(MB)=512, used_size(MB)=486, used_percent(%)=95, warn_size(MB)=409, warn_percent(%)=80, limit_size(MB)=486, limit_percent(%)=95, total_unrecyclable_size_byte(MB)=422, maximum_used_size(MB)=486, maximum_log_stream=1, oldest_log_stream=1, oldest_scn={val:1723570290711530417, v:0}, in_shrinking=false)
[2024-08-16 09:57:11.732554] ERROR period_calc_disk_usage (palf_env_impl.cpp:1349) [21606][T1001_LogLoop][T1001][Y0-0000000000000000-0-0] [lt=0][errcode=-4264] Log out of disk space(msg=“log disk space is almost full”, ret=-4264, total_size(MB)=512, used_size(MB)=486, used_percent(%)=95, warn_size(MB)=409, warn_percent(%)=80, limit_size(MB)=486, limit_percent(%)=95)
clog盘满了,扩容下
磁盘空间正常的,还剩余400g左右,另外total_size(MB)=512,日志里边这个总大小怎么才512m呢,我用obd cluster config,查看参数如下:
obagent:
servers:
- 127.0.0.1
global:
home_path: /root/obagent
ob_monitor_status: active
depends: - oceanbase-ce
grafana:
servers: - 127.0.0.1
global:
home_path: /root/grafana
login_password: IY8K0RfDGp
depends: - prometheus
oceanbase-ce:
servers: - 127.0.0.1
global:
home_path: /root/oceanbase-ce
cluster_id: 1712653284
enable_syslog_recycle: true
enable_syslog_wf: false
max_syslog_file_count: 4
memory_limit: 6144M
production_mode: false
__min_full_resource_pool_memory: 1073741824
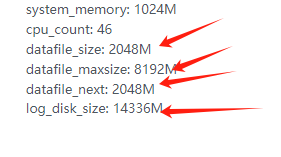
system_memory: 1024M
cpu_count: 46
datafile_size: 2048M
datafile_maxsize: 8192M
datafile_next: 2048M
log_disk_size: 14336M
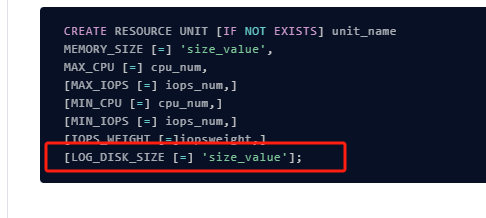
看下这个值多大? 截图发下
select * from oceanbase.__all_unit_config;
现在数据库都起不了呢,无法查询呢,头疼


明白你意思了,我应该是租户的设置少了,达到限制了,我能否先手工删除日志文件,让服务线启动
先将这个调大些,调整到50G,先启动起来,在查看log_disk_size
obd cluster edit-config 集群名称

扩大再次尝试试下
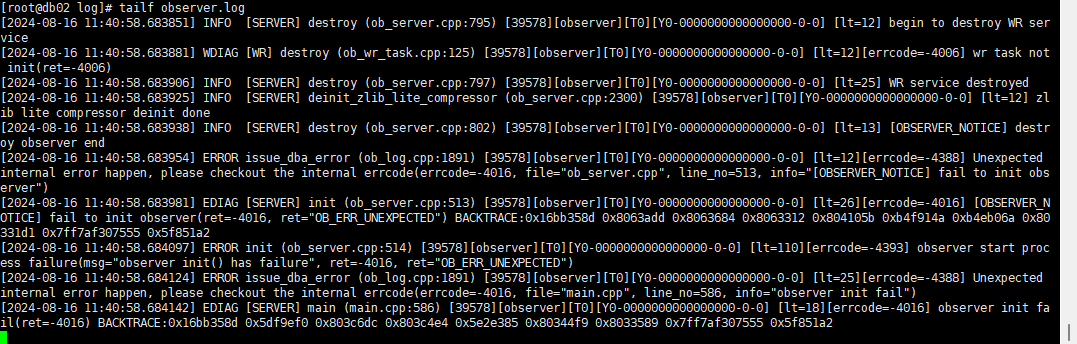
不能手动清理clog,手动删除clog后集群就彻底无法启动了
df -h 看下磁盘空间
尝试带参启动下
./bin/observer -o “log_disk_size=50G,log_disk_utilization_threshold=95,log_disk_utilization_limit_threshold=98”
注意:如果报错libmariadb.so.3: cannot open shared object file
修复方式:
#将 OceanBase 数据库的 LIB 加到环境变量 LD_LIBRARY_PATH 中,按实际路径替换下面路径即可。
echo ‘export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/oceanbase-ce/lib/’ >> ~/.bash_profile
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/oceanbase-ce/lib/
这个问题有进展了吗
遇到同样问题,
[2026-01-21 13:29:18.380144] ERROR try_recycle_blocks (palf_env_impl.cpp:784) [929196][T1_PalfGC][T1][Y0-0000000000000000-0-0] [lt=39][errcode=-4264] Log out of disk space(msg=“log disk space is almost full”, ret=-4264, total_size(MB)=2048, used_size(MB)=2007, used_percent(%)=98, warn_size(MB)=1638, warn_percent(%)=80, limit_size(MB)=1945, limit_percent(%)=95, total_unrecyclable_size_byte(MB)=1942, maximum_used_size(MB)=2007, maximum_log_stream=1, oldest_log_stream=1, oldest_scn={val:1755276431024245001, v:0}, in_shrinking=false)
[2026-01-21 13:29:19.042108] ERROR period_calc_disk_usage (palf_env_impl.cpp:1349) [929198][T1_LogLoop][T1][Y0-0000000000000000-0-0] [lt=28][errcode=-4264] Log out of disk space(msg=“log disk space is almost full”, ret=-4264, total_size(MB)=2048, used_size(MB)=2007, used_percent(%)=98, warn_size(MB)=1638, warn_percent(%)=80, limit_size(MB)=1945, limit_percent(%)=95)
执行了这个没反应
./bin/observer -o “log_disk_size=128G,log_disk_utilization_threshold=95,log_disk_utilization_limit_threshold=98”
./bin/observer -o log_disk_size=128G,log_disk_utilization_threshold=95,log_disk_utilization_limit_threshold=98
optstr: log_disk_size=128G,log_disk_utilization_threshold=95,log_disk_utilization_limit_threshold=98
[root@localhost oceanbase-ce]# ps -ef|grep observer
root 1626320 1625799 0 15:45 pts/0 00:00:00 grep --color=auto observer
df -Th
文件系统 类型 容量 已用 可用 已用% 挂载点
devtmpfs devtmpfs 32G 0 32G 0% /dev
tmpfs tmpfs 32G 0 32G 0% /dev/shm
tmpfs tmpfs 32G 3.2G 29G 11% /run
tmpfs tmpfs 32G 0 32G 0% /sys/fs/cgroup
/dev/vda3 xfs 70G 18G 53G 25% /
tmpfs tmpfs 32G 64K 32G 1% /tmp
/dev/vda5 xfs 898G 207G 692G 23% /home
/dev/vda1 xfs 1014M 240M 775M 24% /boot
tmpfs tmpfs 6.3G 0 6.3G 0% /run/user/0
麻烦重新发个帖子吧
没人回复啊
我看在回复了,和辞霜老师沟通了下,还需要再看下
帮忙看看可以吗