1)我们的历史数据都是需要保存的,都是客户的明细,不可以删除
2)truncate的是业务当天的数据,之前的都是不可以删除的
3)按照我们现在的业务逻辑,分区数量只会越来越多
4)单表删除的很慢,按照之前测试的场景,delete数据会超时,所以才采取了当前的方案
疑问:
1)如果分区数量越来越大,是不是会越来越慢
1)我们的历史数据都是需要保存的,都是客户的明细,不可以删除
2)truncate的是业务当天的数据,之前的都是不可以删除的
3)按照我们现在的业务逻辑,分区数量只会越来越多
4)单表删除的很慢,按照之前测试的场景,delete数据会超时,所以才采取了当前的方案
疑问:
1)如果分区数量越来越大,是不是会越来越慢
将尝试帖子的解决方式“通过调小以下参数来控制 schema 历史信息的回收”。观测是否有效果
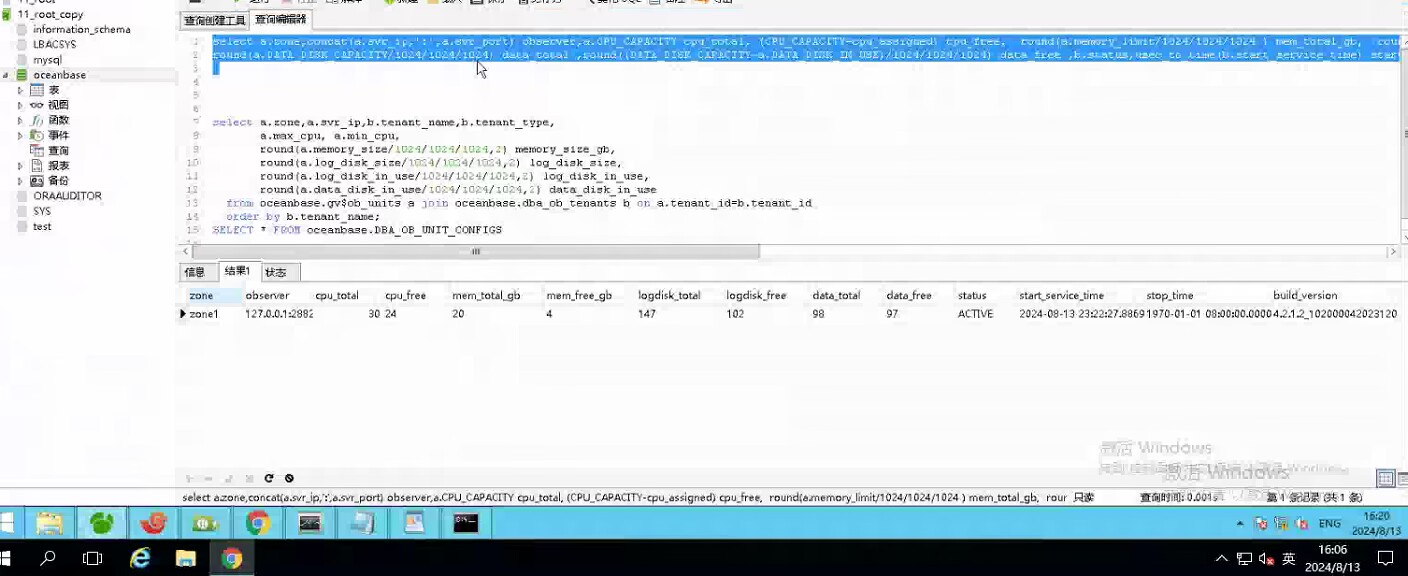
sys租户3个C
dstarv10租户26个C,平常客户用dstarv10多一些。
按照您说的意思,是不是sys的C少导致的?但是dstarv10是客户主要用的。这样的情况下您这边建议怎么分配C
2)"CREATE TENANT IF NOT EXISTS dstar PRIMARY_ZONE=‘zone1’,RESOURCE_POOL_LIST=(‘user_pool’) SET OB_TCP_INVITED_NODES=’%’,LOWER_CASE_TABLE_NAMES = 0;
老师我们创建分区的语句如上,您帮忙看下有没有问题
老师,有以下几点向您补充说明
1)我们的分区设计逻辑是按照日期创建的分区,一天一个分区
2)我们的分区会越来越多,因为客户的历史数据是不能删除的
3)我刚才尝试drop分区之后,再add回来,发现add不回来报错
add语句:ALTER TABLE THisPosition ADD PARTITION D20231011 VALUES LESS THAN (“2023-10-11”);
drop语句执行成功,分区D20231011原来是已经创建好的,他的后边原来就是D20231012
drop语句:ALTER TABLE THisPosition DROPPARTITION D20231011
好的老师,下午客户运维才上班,下午提供给您。
我看你的另一个帖子说的 是有一个全局索引和两个本地索引
1、分区表包含全局索引,那么删除分区后,OceanBase 数据库的 MySQL 模式下会自动重建该全局索引。即使你删除了一个没有数据的分区,如果整个表数据量很大,重建全局索引是非常耗时的,整个 DDL 的耗时可能会超过预期,甚至超时。
2、你可以尝试一下 调整这两个参数
https://www.oceanbase.com/knowledge-base/oceanbase-database-1000000000514283?back=kb
3、你可以用obdiag 收集执行的信息 贴一下 分析分析
obdiag gather scene run --scene=observer.perf_sql --env “{db_connect=’-hxx -Pxx -uxx -pxx -Dxx’, trace_id=‘xx’}”
obdiag文档
https://www.oceanbase.com/docs/common-obdiag-cn-1000000001102504
老师,我在数据库里查schema_history_expire_time和schema_history_recycle_interval,这两个变量,查不到都
这两个参数都是集群级配置项 查询的方式show parameters like ‘schema_history_expire_time’;
老师,参数查到了。
您这边建议设置为多大
老师,您说的第三条建议,其中有一个参数叫trace_id。查阅资料发现需要通过gv$sql_audit查询。
sql语句:select * from gv$sql_audit;报错表gv$sql_audit不存在。。。
一般情况下 系统设置的都是默认最佳值 你可以根据当前的情况 考量设置
这个时间是多版本记录回收任务的时间间隔 你自己设置看看 记住默认值
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000000220464
1、执行语句
ALTER TABLET HisPosition Truncate PARTITION D20240813;
2、查询trace_id
select last_trace_id();
3、执行obdiag收集信息
obdiag gather scene run --scene=observer.perf_sql --env “{db_connect=’-hxx -Pxx -uxx -pxx -Dxx’, trace_id=‘xx’}”
4、收集报告上传到帖子上
老师,我的操作是首先在一个obclient中输入命令
alter table THisPosition truncate partition D20240813;
然后又开了一个obclient,执行select last_trace_id();发现traceid会变化,就是不止一个tradeid,这样的话咋整
这种方式只能在一个窗口执行 truncate语句生产环境执行需谨慎
如果执行时间长 执行完 你查询诊断信息 获取trace_id 在用obdiag收集信息
select TRACE_ID from oceanbase.gv$ob_sql_audit where QUERY_SQL like ‘%alter table THisPosition truncate partition D20240813%’;
敏感信息 尽量脱敏发出来
obdiag收集出来信息了么?
老师,gather的结果发给您
obdiag_gather_pack_20240816164034.7z (1.9 MB)
执行gather后,有如下的提示信息
[ERROR] plan explain> explain extended alter table THisPosition TRUNCATE PARTITION D20240813
[ERROR] ProgrammingError(1064, “You have an error in your SQL syntax; check the manual that corresponds to your OceanBase version for the right syntax to use near ‘alter table THisPosition TRUNCATE PARTITION D20240813’ at line 1”)
table count ((‘THisPosition’, 4805057),)
data size ((‘127.0.0.1’, ‘LEADER’, 2090836),)
还有一个问题,为什么在obclient执行显示花费了 12min 26.136sec。为啥这个结果里头显示只花了276s
没事 不支持ddl的expaln 这个没事
我也问了相关的同学 结论:分区表包含全局索引,即使你删除了一个没有数据的分区,和数据量、schema等有关系,重建全局索引是非常耗时的,整个 DDL 的耗时可能会超过预期,甚至超时,不同的表的消耗的时间也是不一样 不建议有压力的时候清理数据