【 使用环境 】生产环境
【 OB or 其他组件 】oceanbase、obproxy
【 使用版本 】oceanbase: 4.2.2.0-CE; obproxy: 4.2.1.0-11
【问题描述】
oceanbase集群为3-3-3架构。obProxy单独部署的。
使用生产的查询sql进行压测。
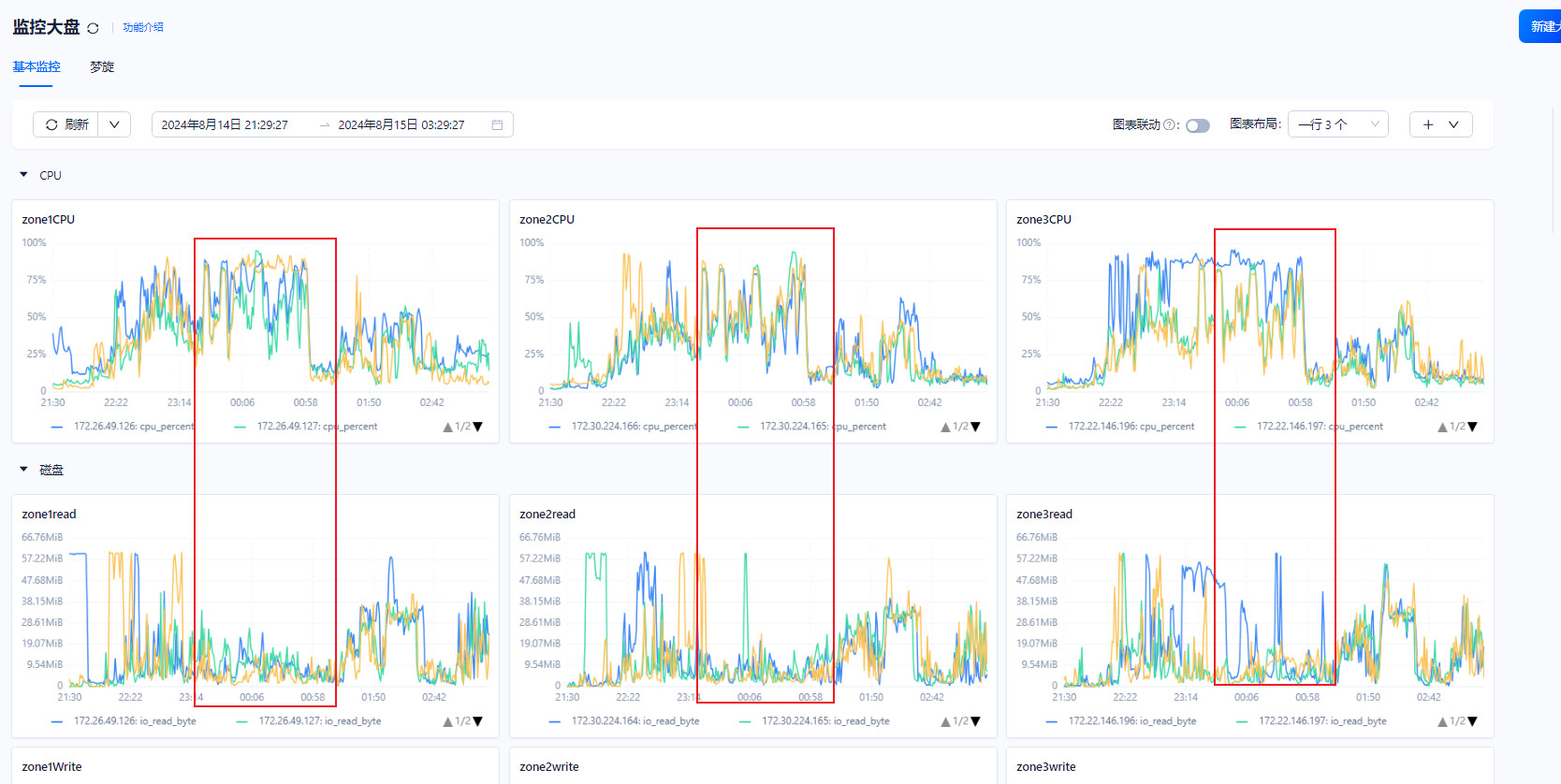
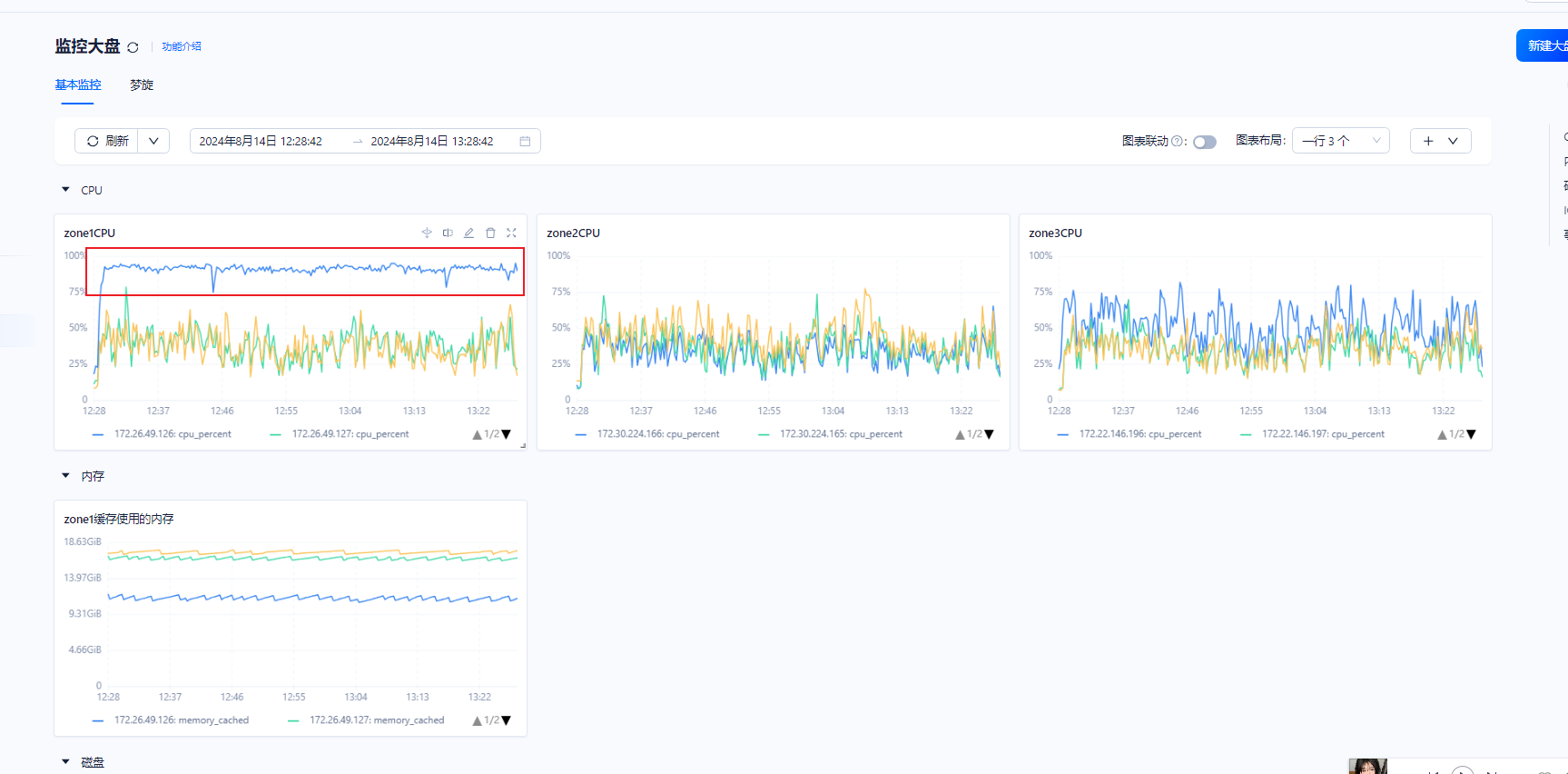
发现集群中只有其中一台cpu是上75%的。其他机器性能都发挥不出来。
而且执行sql的qps上不去。
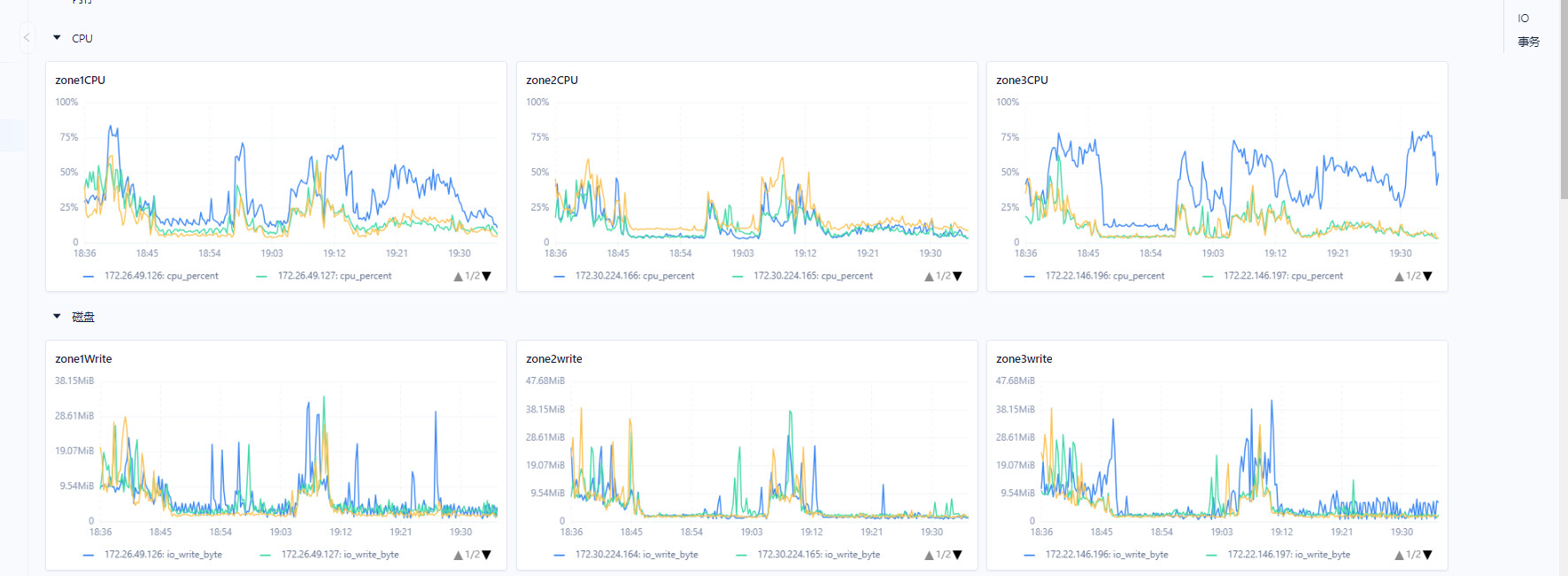
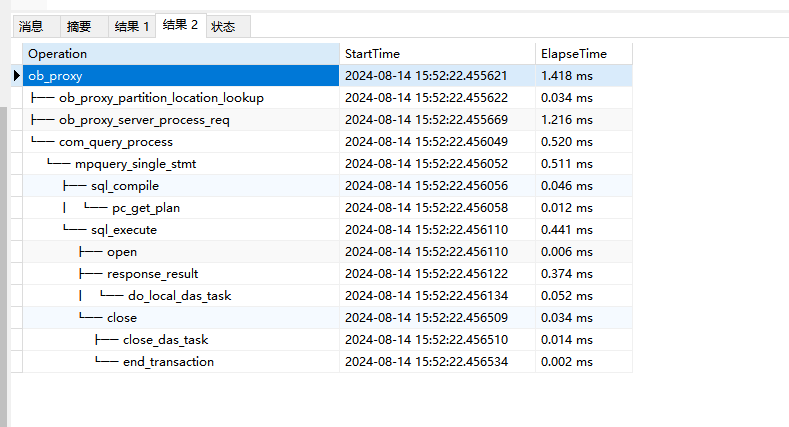
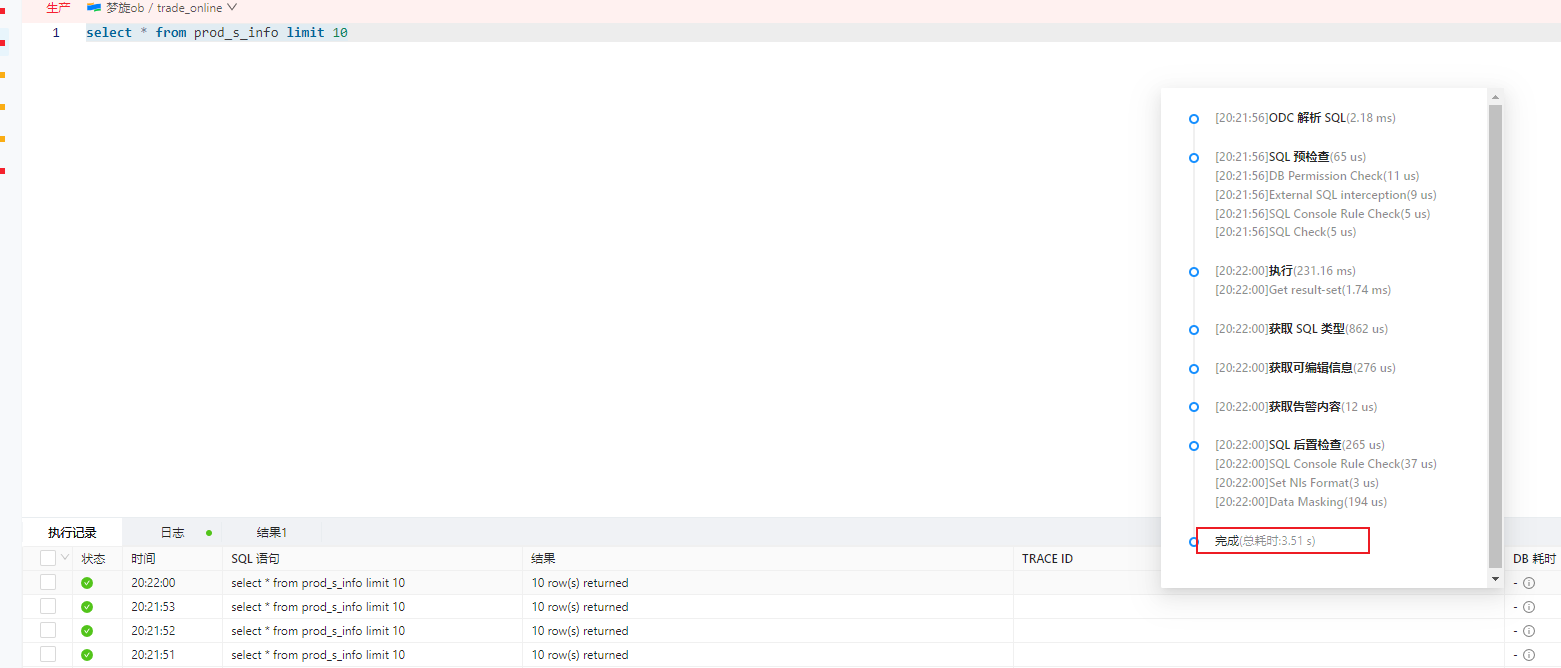
手动执行sql偶尔会被阻塞几十秒。如下图
简单的select * from prod_s_info limit 10. 正常是0.5s左右就出结果的。
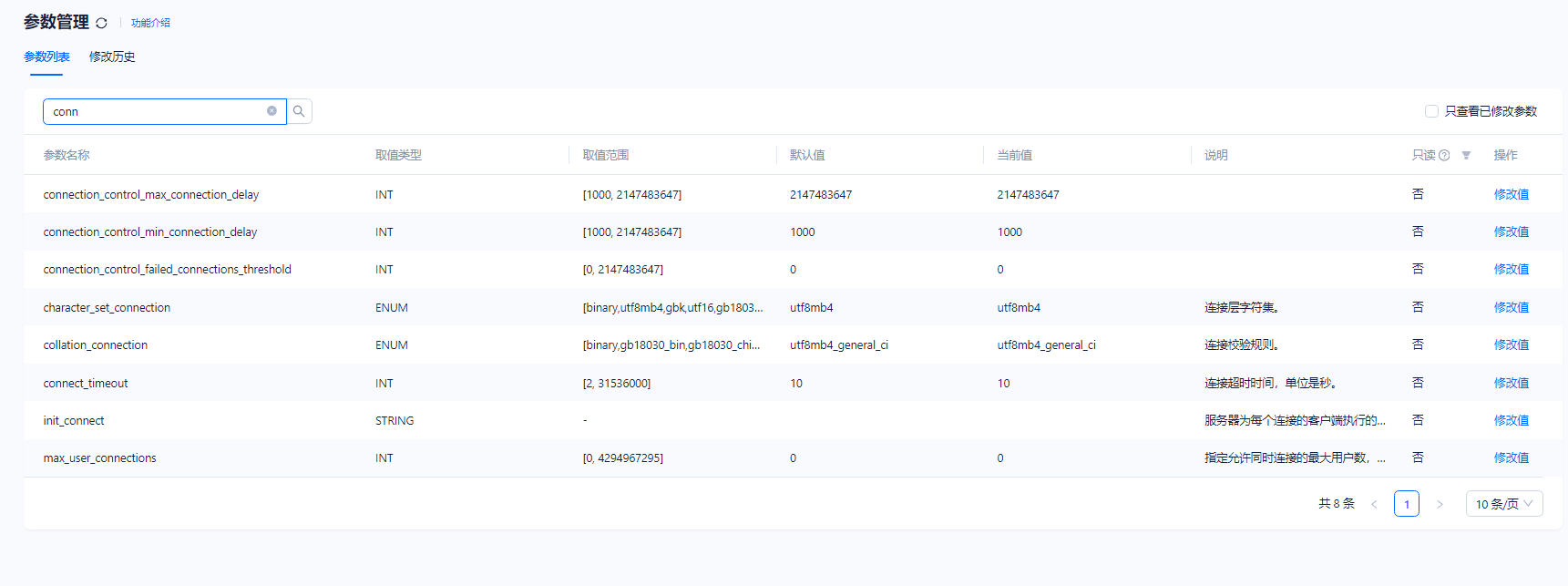
租户关于连接的参数设置如下
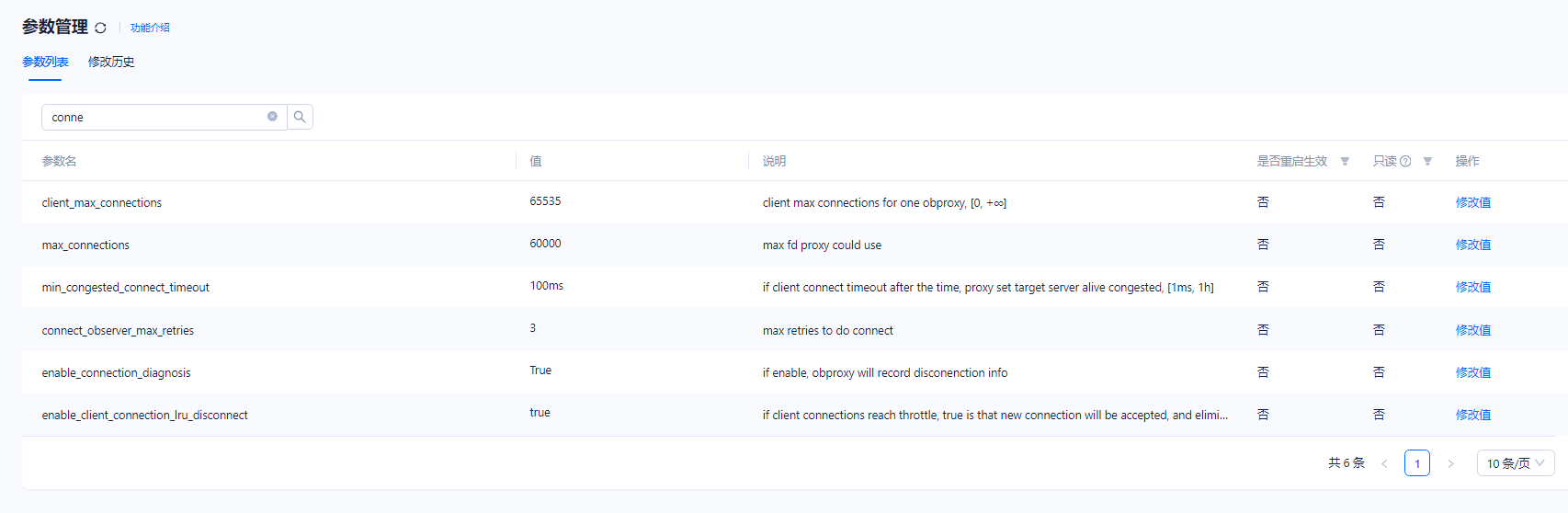
obproxy关于连接的参数设置如下
首次diag巡检结果
巡检结果.txt (81.0 KB)
1、调整后,重新压测。 然后压测期间巡检结果如下
obdiag_check_report_observer_2024-08-14-13-25-36.log (53.4 KB)
2、【sql_error_4013】增大了work_percent. 已经没有这个报错了
3、压测场景:从rds上现在了5分钟全量sql。然后开启了3000个线程循环执行这些sql。

4、上午分析了下慢sql。发现主要是有关联查询,有索引却不使用索引。重新收集了统计信息后,才走索引。然后这个sql走索引后,zone3的最高cpu达到75%的降下来了。
然后发现其他的慢sql了。如下图。现在开始zone1的cpu飙升到95%。
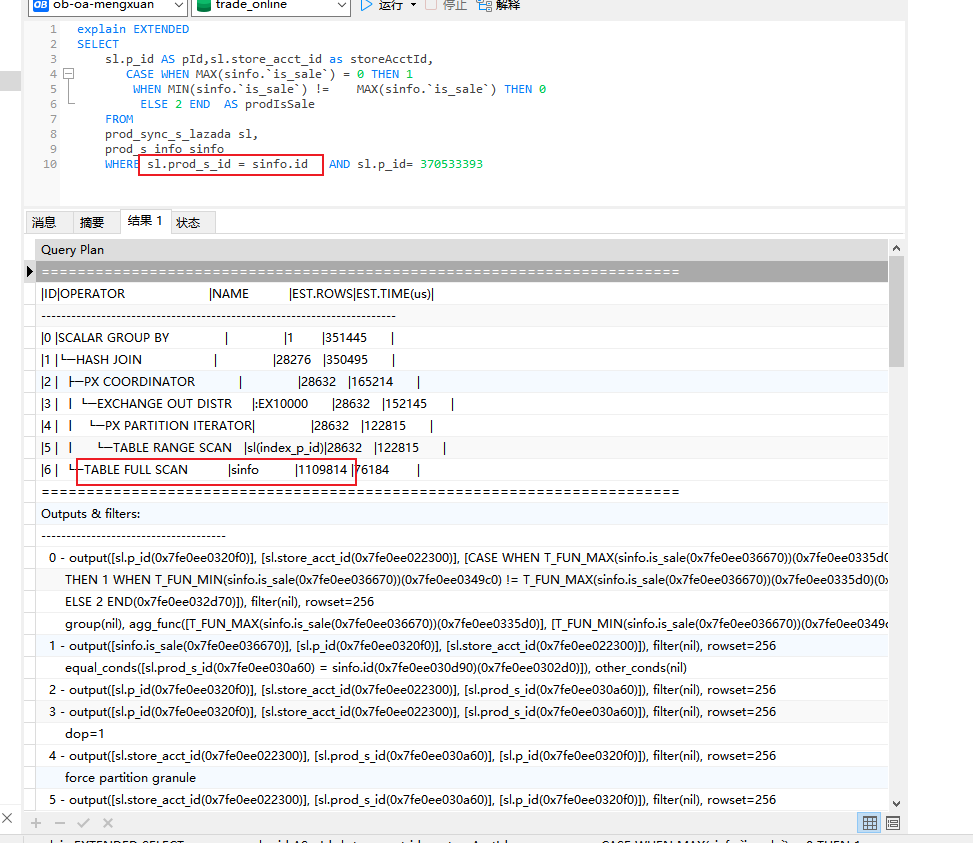
然后看了下消耗cpu最大的一个sql。执行计划如下
完整explain.txt (4.9 KB)
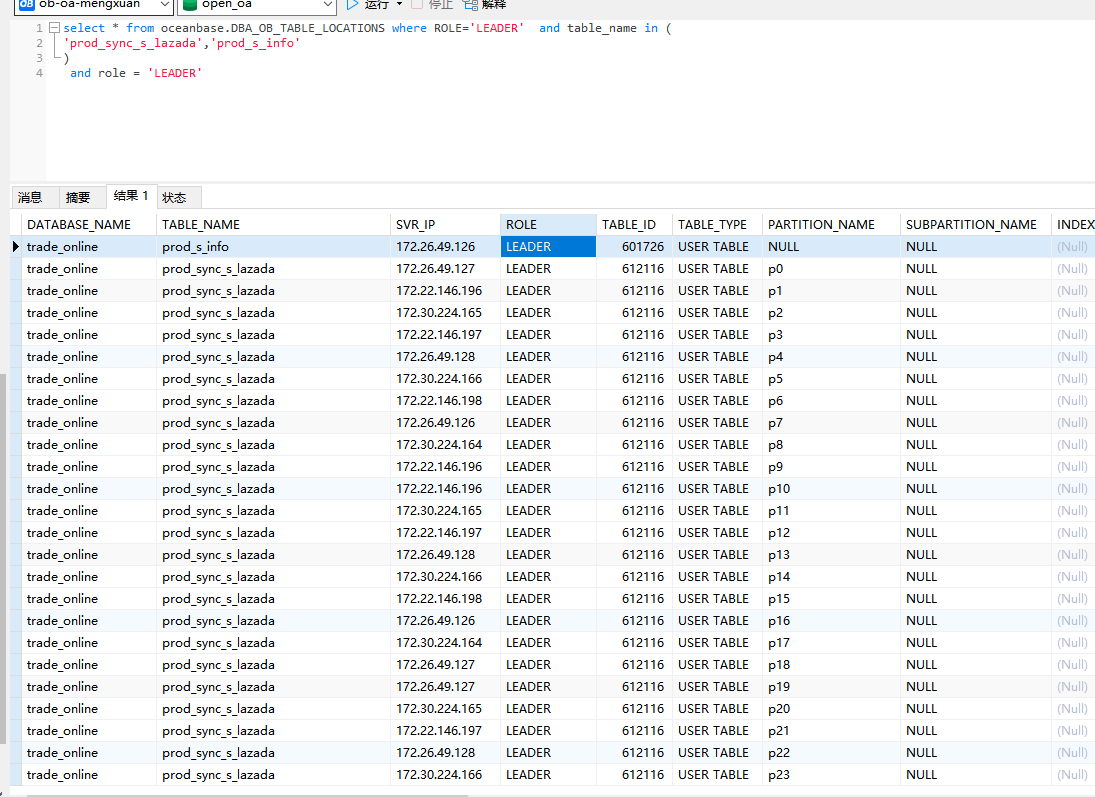
其中表prod_sync_s_lazada是个分区表
表prod_s_info是个复制表。
然后发现使用主键关联prod_s_info表,也不使用主键索引。直接扫全表了
obdiag查询到的执行计划如下
obdiag_gather_pack_20240814135454.zip (218.2 KB)
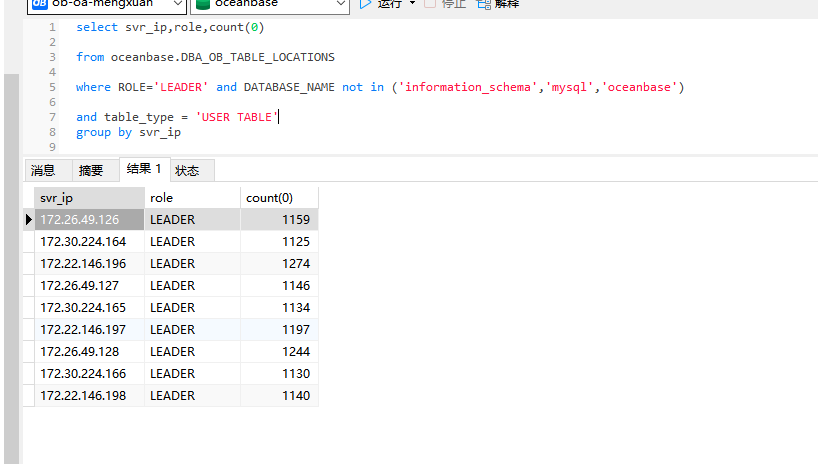
比较大的问题就是,只要有1台机器的cpu爆表了。 leader在其他主机的查询也都慢下来了
整体的性能都下降了