rocH
2024 年8 月 13 日 20:09
#1
【 使用环境 】生产环境
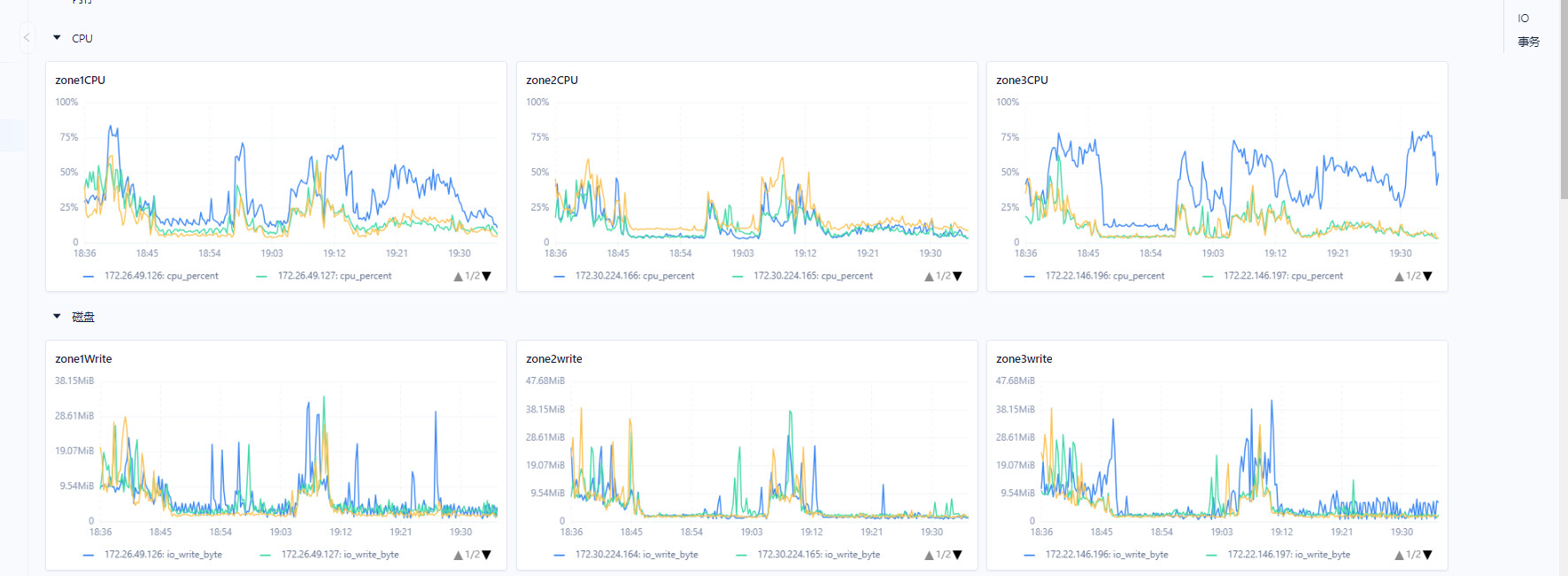
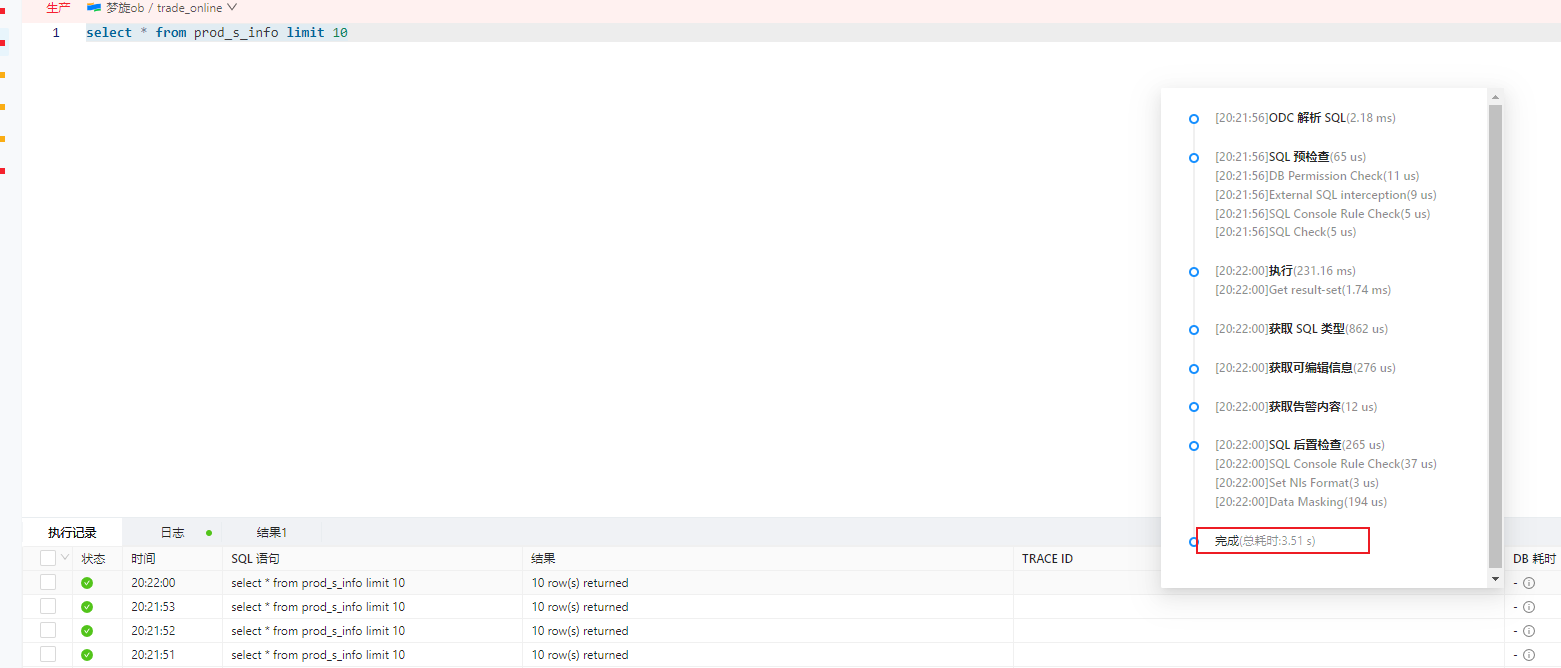
手动执行sql偶尔会被阻塞几十秒。如下图
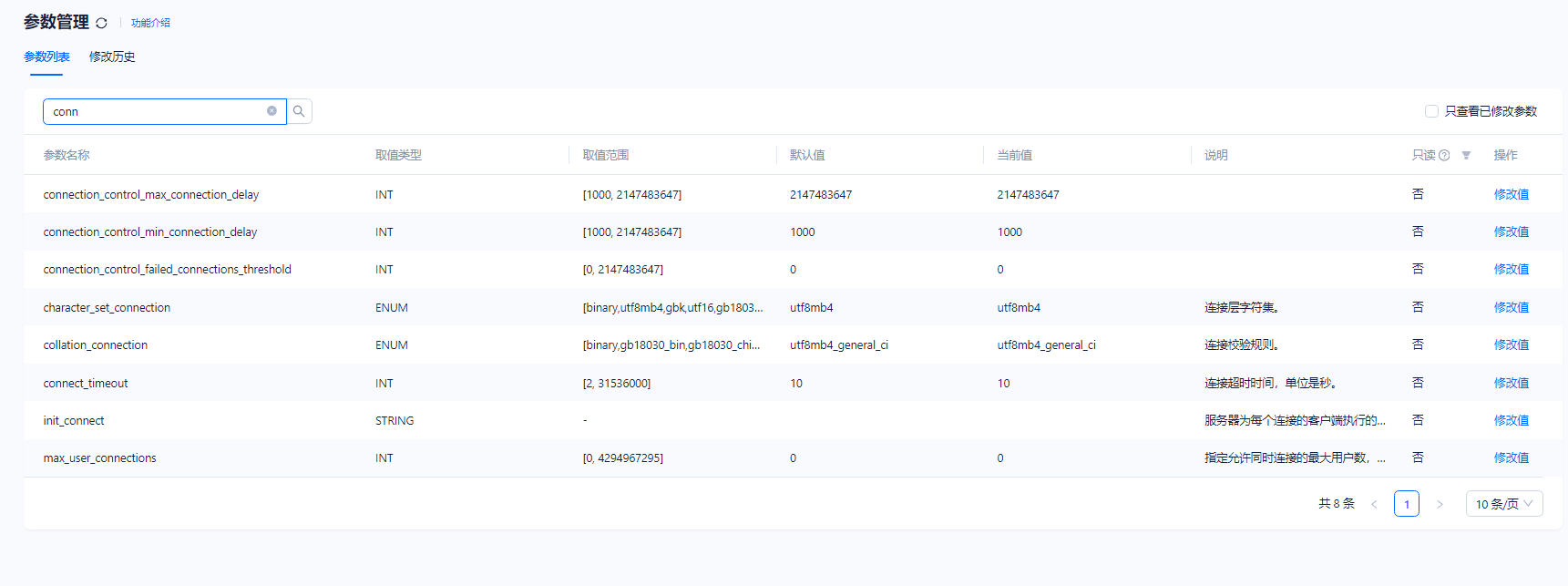
租户关于连接的参数设置如下
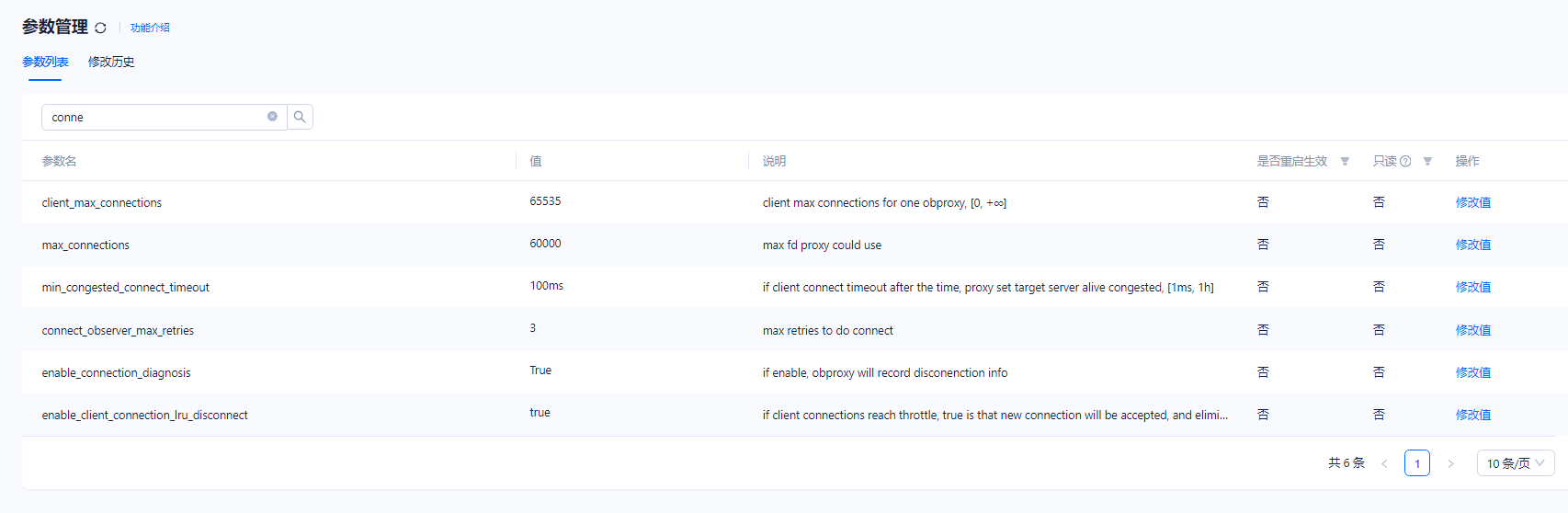
obproxy关于连接的参数设置如下
rocH
2024 年8 月 13 日 21:00
#3
diag巡检结果巡检结果.txt (81.0 KB)
咖啡哥
2024 年8 月 14 日 08:20
#4
负载不均衡
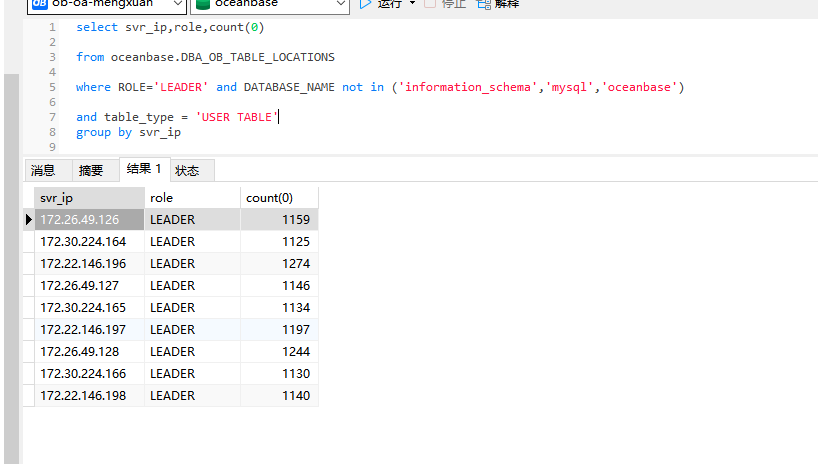
select DATABASE_NAME,table_name,svr_ip,role,count(0) from oceanbase.DBA_OB_TABLE_LOCATIONS where ROLE='LEADER' and DATABASE_NAME not in ('information_schema','mysql','oceanbase') group by DATABASE_NAME,table_name,svr_ip,role order by 1,2,3;
旭辉
2024 年8 月 14 日 11:01
#6
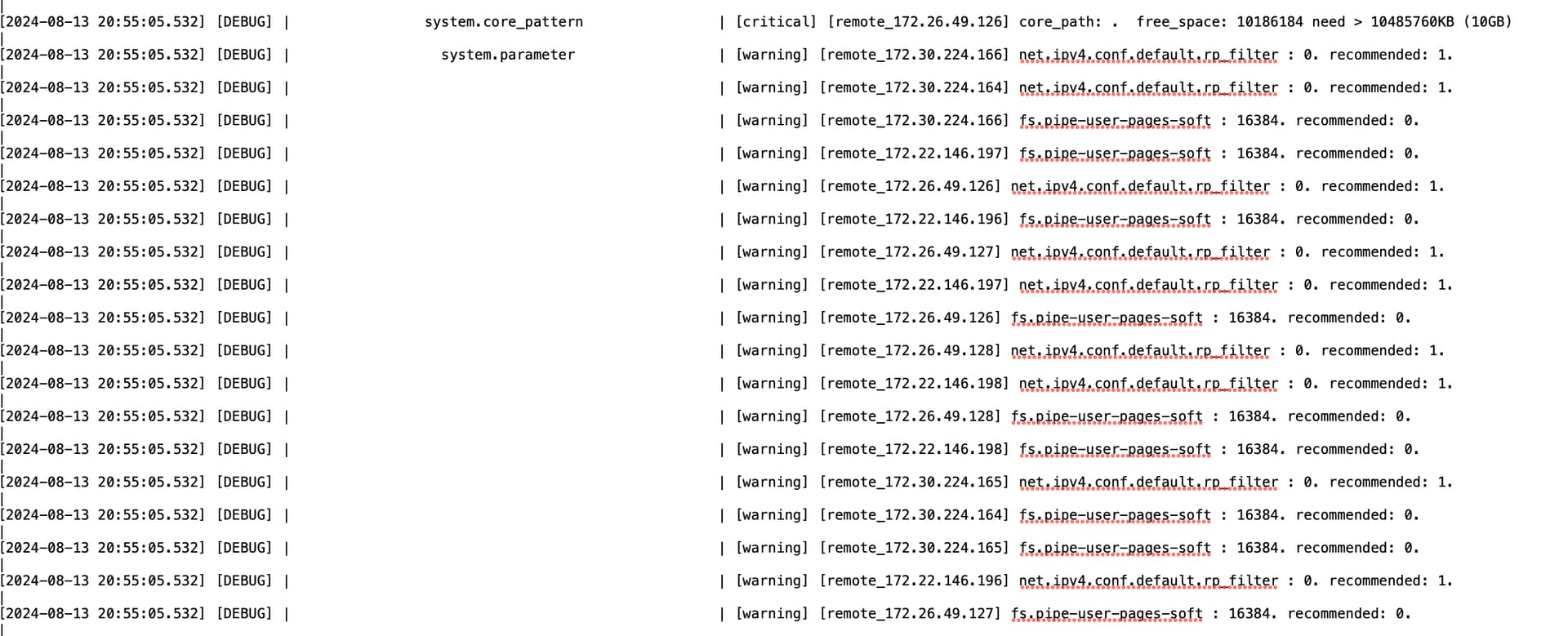
1.作为生产环境,建议先根据巡检结果建议将[warning],[critical]项调整下
2.[warning] [cluster:obcluster] number of sql_error_4013 is 99619 有4013错误,麻烦发下observer.log
75% cpu使用率不高,且leader分布基本均衡,麻烦详细描述下你的压测场景
4.sql执行偶尔慢,需要分析下当时这个SQL的具体执行计划,可以使用obdiag 搜集下SQL Plan MonitorOceanBase 社区 7s9uvi _gaMTIwMjU5NTAzNC4xNzE0OTc1MTY1 _ga_T35KTM57DZ*MTcyMzU5OTMzNC4xMzEuMS4xNzIzNjA0NDUwLjQ2LjAuMA…
旭辉
2024 年8 月 14 日 11:05
#7
另外生产环境紧急问题可以提官方悬赏帖,处理效率更高
1 个赞
rocH
2024 年8 月 14 日 13:33
#8
1、调整后,重新压测。 然后压测期间巡检结果如下obdiag_check_report_observer_2024-08-14-13-25-36.log (53.4 KB)
2、【sql_error_4013】增大了work_percent. 已经没有这个报错了
3、压测场景:从rds上现在了5分钟全量sql。然后开启了3000个线程循环执行这些sql。
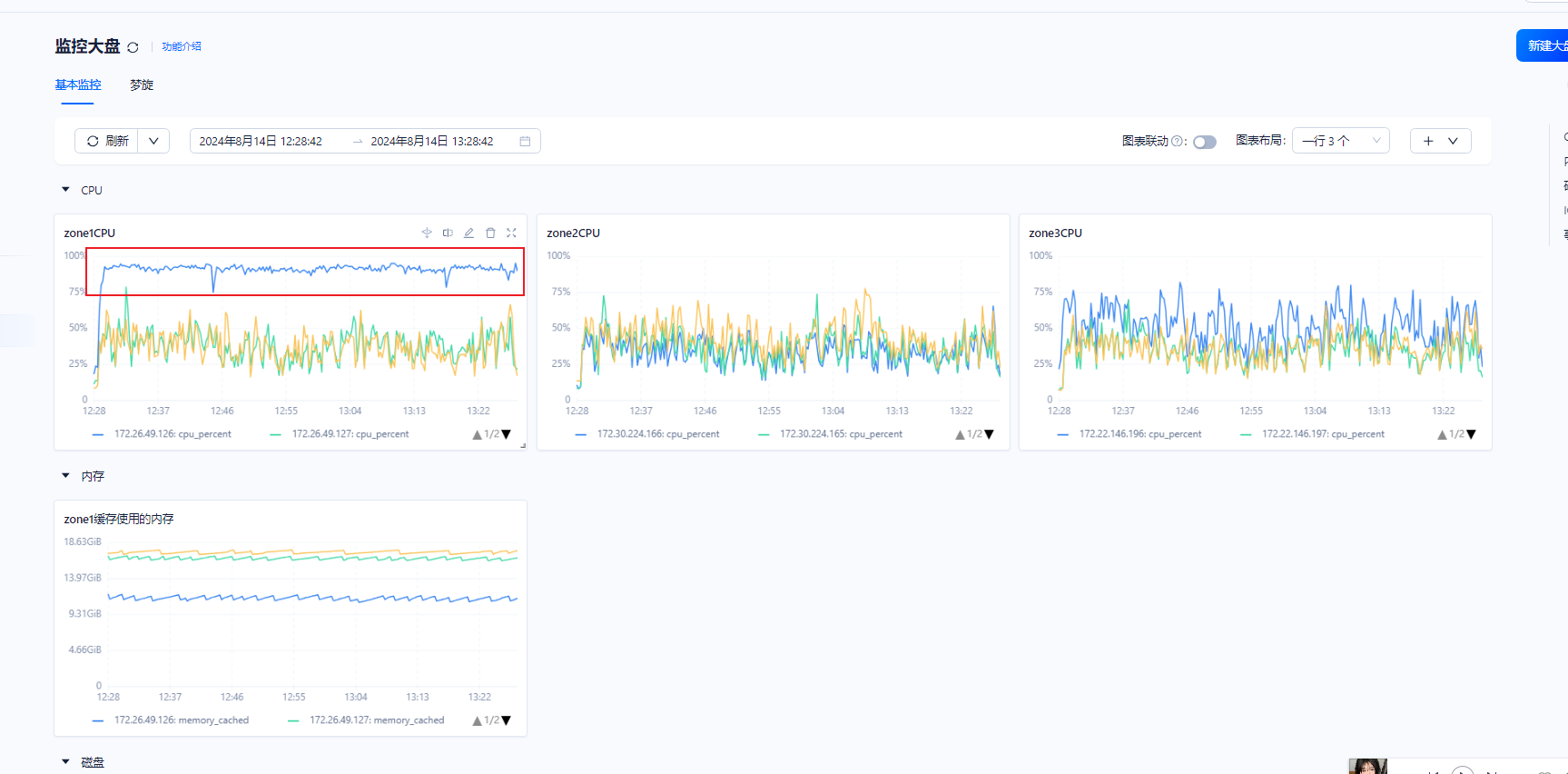
4、上午分析了下慢sql。发现主要是有关联查询,有索引却不使用索引。重新收集了统计信息后,才走索引。然后这个sql走索引后,zone3的最高cpu达到75%的降下来了。
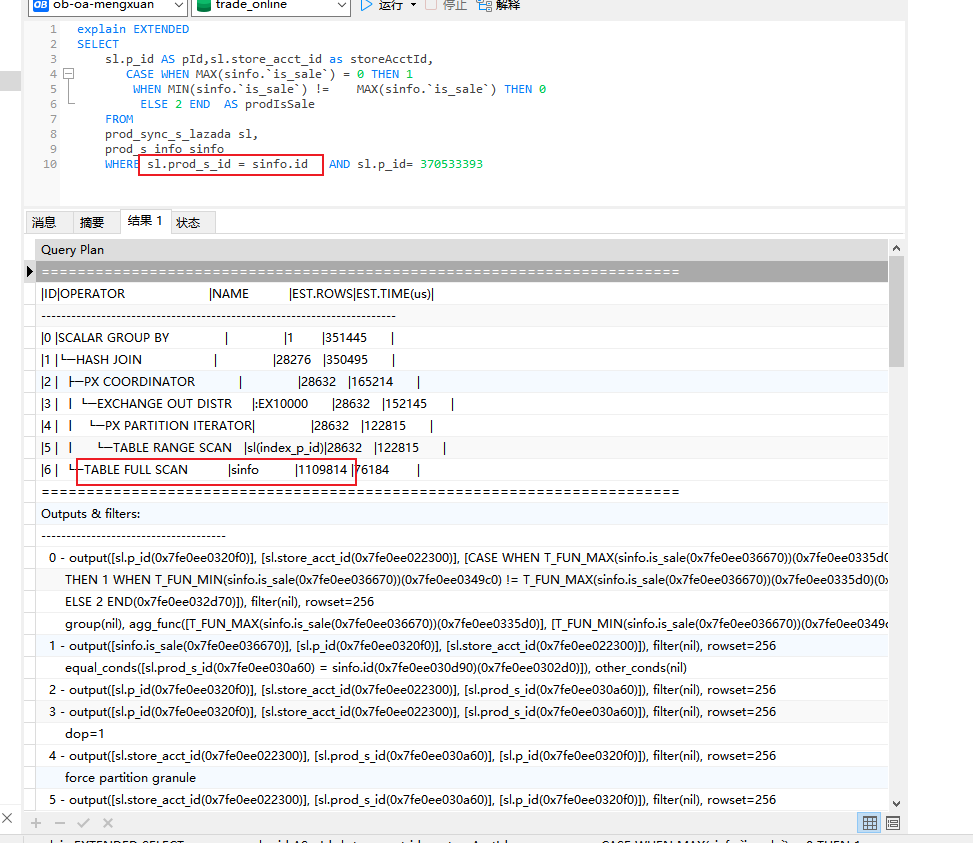
然后看了下消耗cpu最大的一个sql。执行计划如下
完整explain.txt (4.9 KB)
其中表prod_sync_s_lazada是个分区表
表prod_s_info是个复制表。
然后发现使用主键关联prod_s_info表,也不使用主键索引。直接扫全表了
obdiag查询到的执行计划如下
obdiag_gather_pack_20240814135454.zip (218.2 KB)
rocH
2024 年8 月 14 日 13:41
#9
好的。下次我用这个渠道
rocH
2024 年8 月 14 日 13:42
#10
比较大的问题就是,只要有1台机器的cpu爆表了。 leader在其他主机的查询也都慢下来了
旭辉
2024 年8 月 14 日 15:51
#12
---- 比较大的问题就是,只要有1台机器的cpu爆表了。 leader在其他主机的查询也都慢下来了
确实会产生这样的问题,可参考如下步骤处理:收到CPU使用率高的告警,SQL响应延迟突然变高,监控中CPU使用率飙升
第一步:通过 top 命令,确认是observer进程导致的CPU使用率升高,如果不是observer进程导致,尽快排查其他进程导致CPU升高原因;
第二步:通过 top -H 命令,检查导致CPU使用率过高的observer线程,如果是TNT_L0_xx线程,则在CPU高场景下收集3次obstack,然后可以寻求官方协助,如问答区提问。如果不是这类线程导致,则进行第三步;
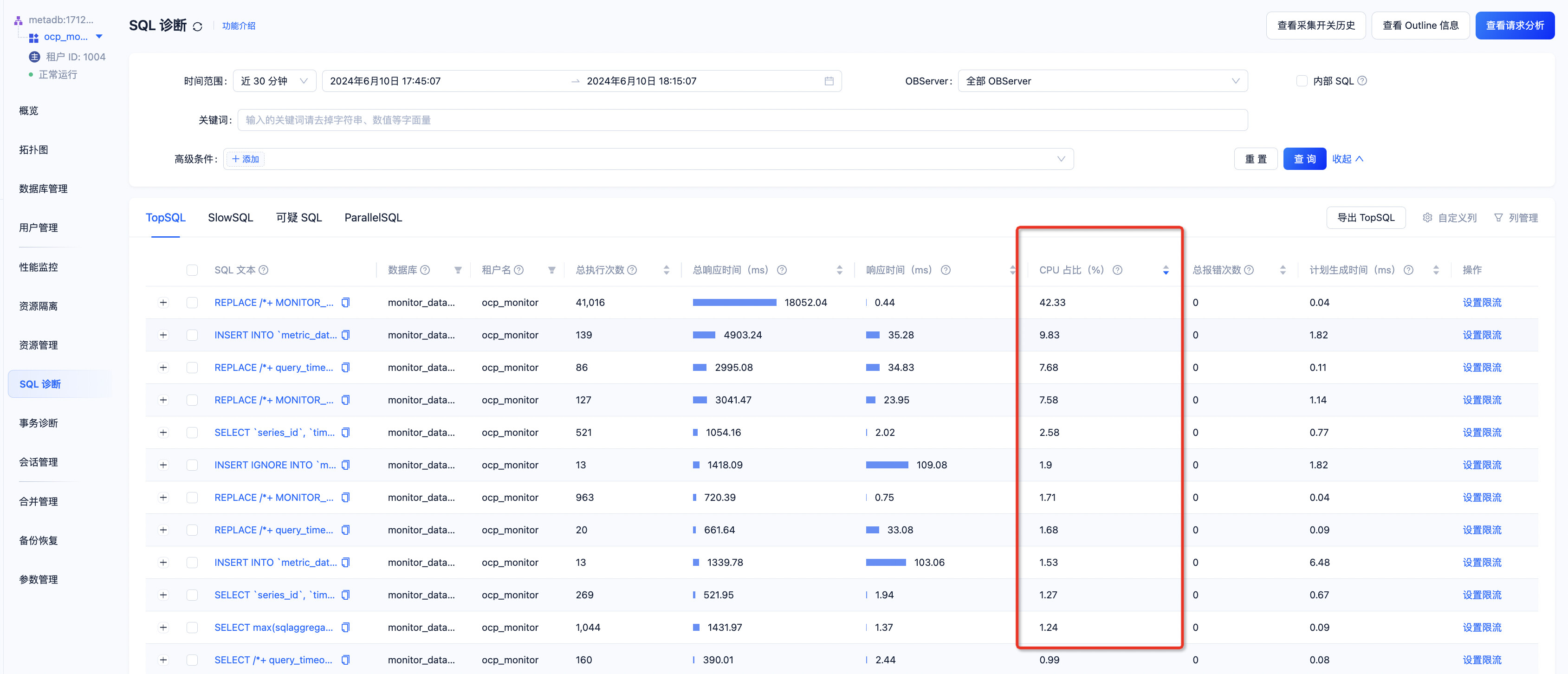
第三步:如果不是以上问题,则大概率是top/slow sql导致,进入到OCP中的SQL诊断里,可根据SQL的CPU占比进行排序,快速找到CPU使用率过高的SQL
然后对SQL进行排查:
检查点一:是否在短时间内生成大量执行计划,即短时间内大量的不同SQL请求、或者相同SQL加了不同的 hint 导致每次SQL执行都要重新生成执行计划;
检查点二:CPU占比高的SQL执行计划是否合理,同场景二中的处理方式,可对SQL执行计划进行绑定;
检查点三:是否存在计算量大的SQL,如存在此类SQL,可对SQL执行限流操作,或进行资源组的隔离。
可以参考下 这篇文章
https://open.oceanbase.com/blog/13250502949
这个帖子的具体慢SQL优化问题在官方悬赏帖回复