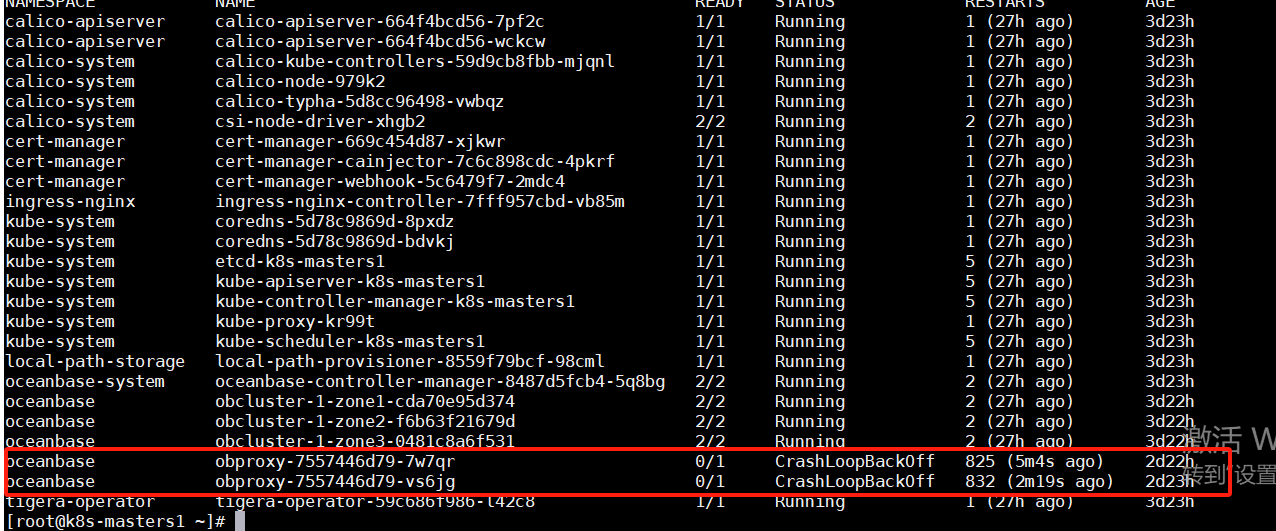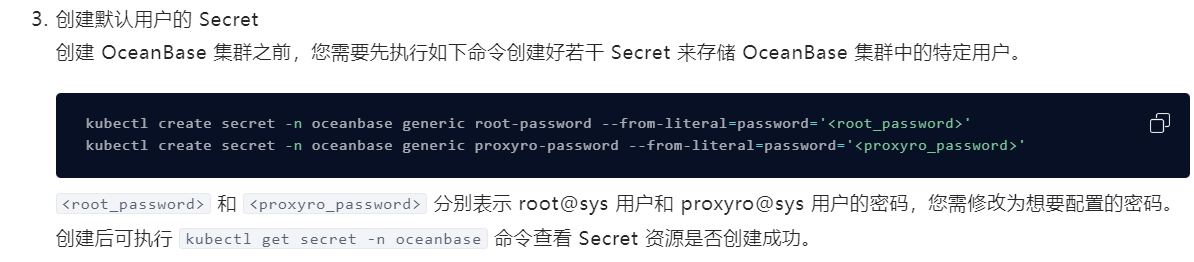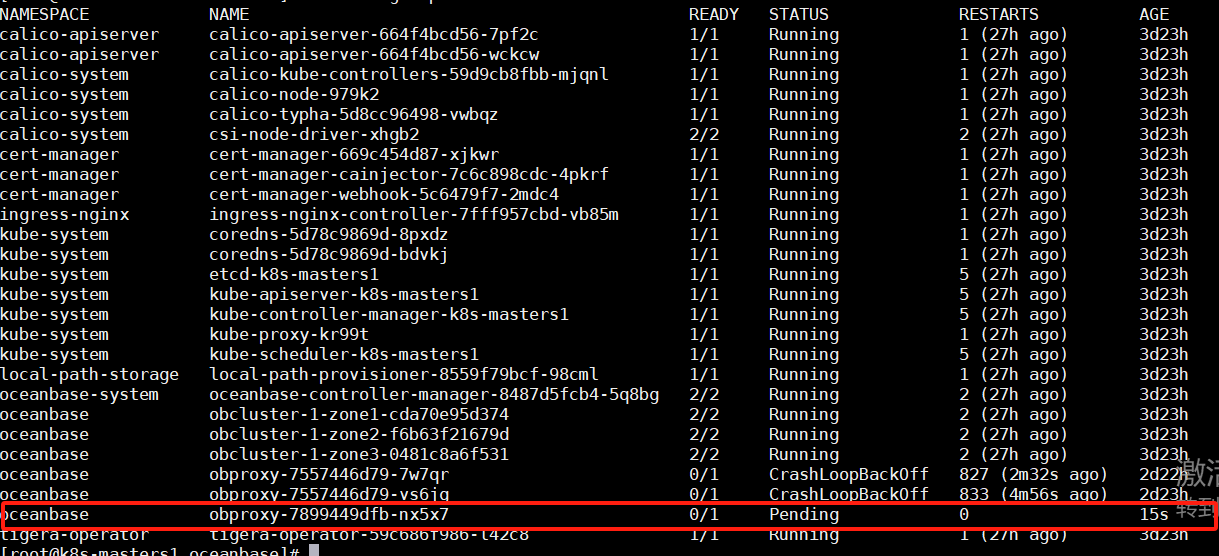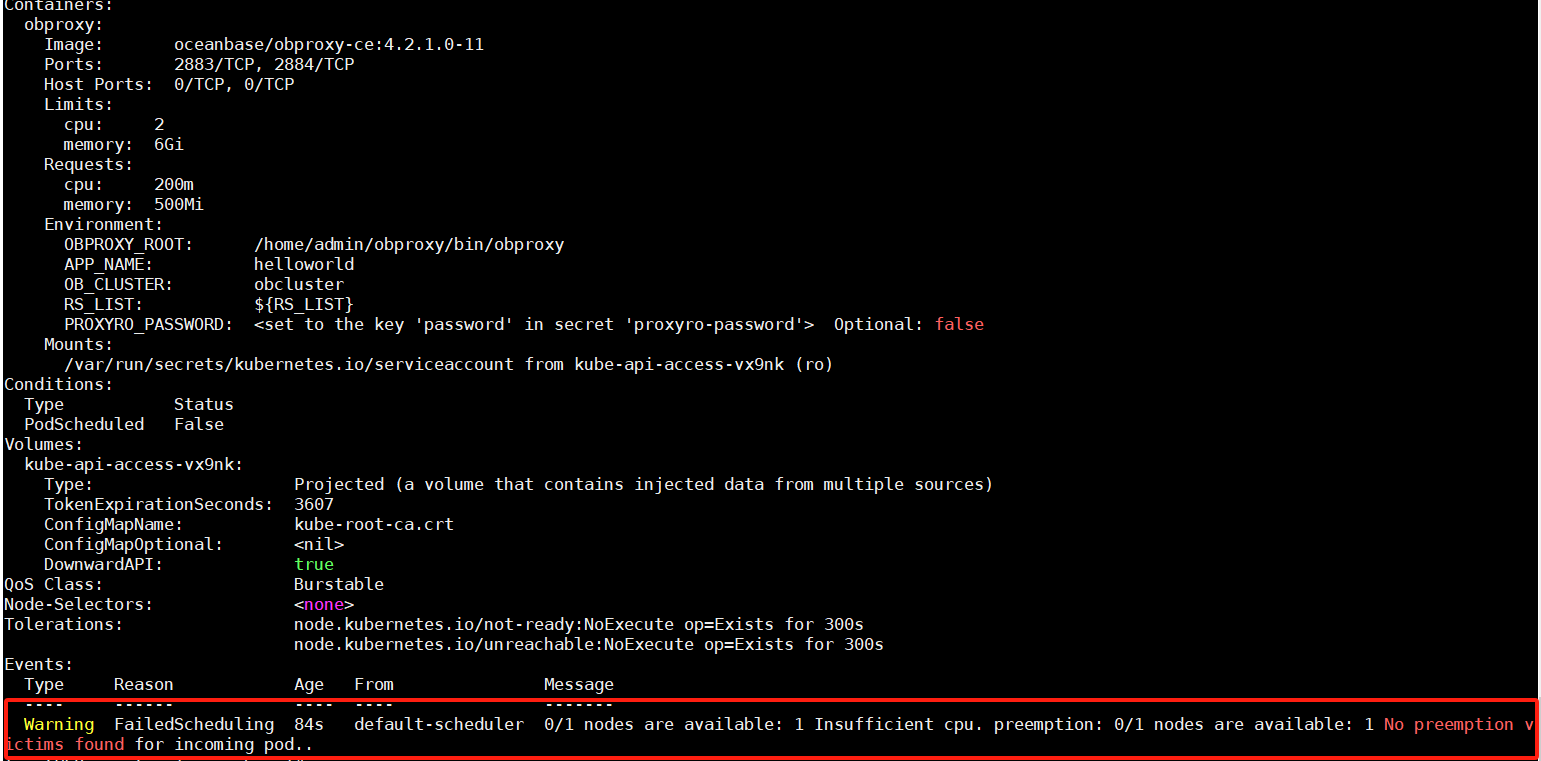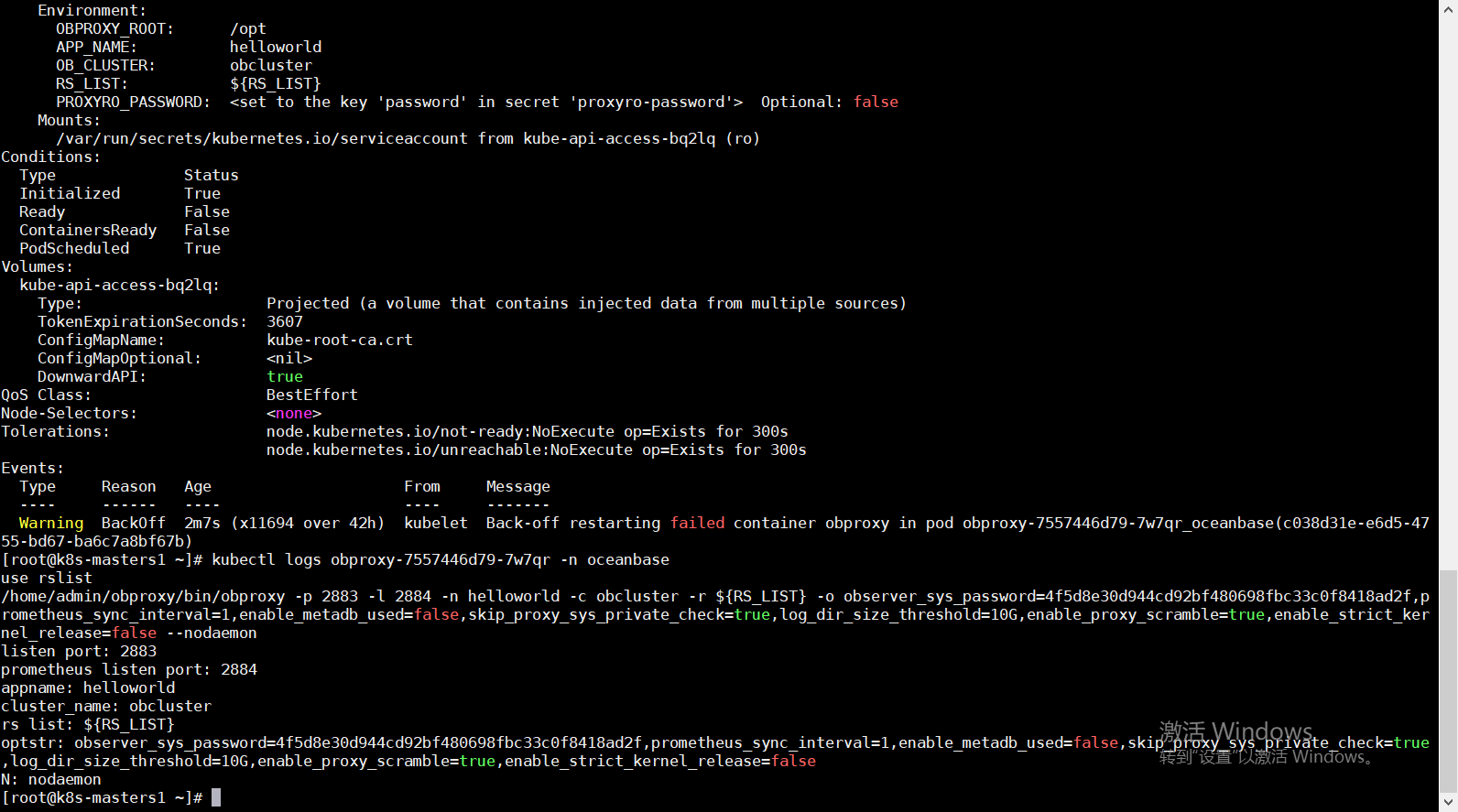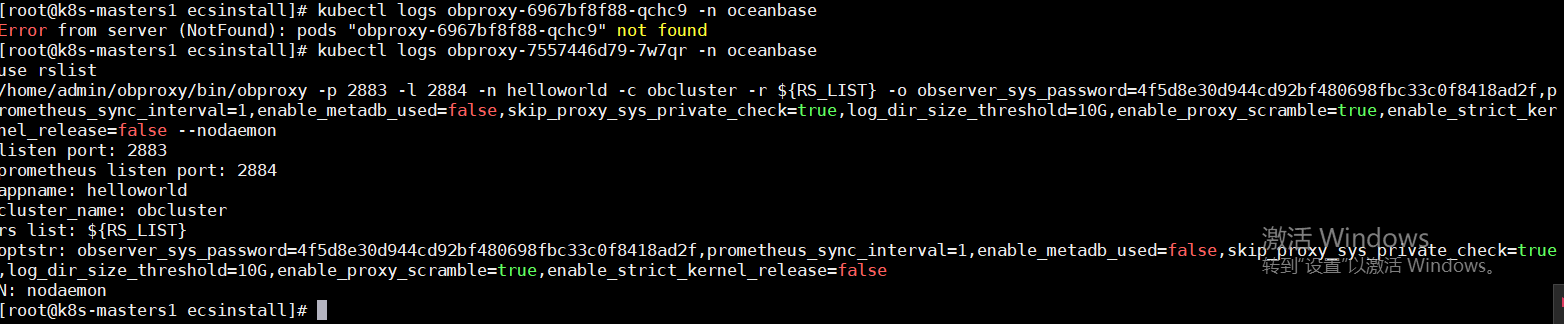
前面的部署都是完全按照官网的部署,没有改动
部署代码如下
apiVersion: v1
kind: Service
metadata:
name: svc-obproxy
namespace: oceanbase
spec:
type: ClusterIP
selector:
app: obproxy
ports:
- name: “sql”
port: 2883
targetPort: 2883
- name: “prometheus”
port: 2884
targetPort: 2884
apiVersion: apps/v1
kind: Deployment
metadata:
name: obproxy
namespace: oceanbase
spec:
selector:
matchLabels:
app: obproxy
replicas: 2
template:
metadata:
labels:
app: obproxy
spec:
containers:
- name: obproxy
image: oceanbase/obproxy-ce:4.2.1.0-11
ports:
- containerPort: 2883
name: “sql”
- containerPort: 2884
name: “prometheus”
env:
- name : OBPROXY_ROOT
value: /home/admin/obproxy/bin/obproxy
- name: APP_NAME
value: helloworld
- name: OB_CLUSTER
value: obcluster
- name: RS_LIST
value: ${RS_LIST}
- name: PROXYRO_PASSWORD
valueFrom:
secretKeyRef:
name: proxyro-password
key: password
# resources:
#limits:
# memory: 6Gi
#cpu: “2”
#requests:
#memory: 500Mi
#cpu: 200m