select table_name,partition_name,subpartition_name,ls_id,zone from oceanbase.DBA_OB_TABLE_LOCATIONS where table_name in(’’) and role=‘LEADER’;
查看下是否leader都在ZONE1上。
SELECT zone, table_name
FROM
oceanbase.DBA_OB_TABLE_LOCATIONS
WHERE
database_name = 'db_name'
AND role = 'LEADER'
AND zone = 'zone1'
AND table_type='USER TABLE'
GROUP BY zone, table_name
ORDER BY zone
我前几天创建3个表组后,当时查看 3个表组的 表 都是在不同的 Zone,负载表现也比较均衡正常。
今天 Zone 1 资源占用超过其他两个 Zone 3倍以上,触发了负载告警,我再去看的时候,这3个表组的数据表主副本 就全部在 Zone 1 了。
-- 按 zone 分组所有表的 LEADER 分布
SELECT zone, database_name, table_name, tablegroup_name
FROM
oceanbase.DBA_OB_TABLE_LOCATIONS
WHERE
database_name IN ( 'db_dev', 'db_test' )
AND role = 'LEADER'
AND table_type='USER TABLE'
AND tablegroup_name IS NOT NULL
GROUP BY database_name, zone, table_name
ORDER BY database_name, zone, tablegroup_name
看着不太对劲,g3_dev表组呢
查看下zone分布及优先级
SELECT * FROM oceanbase.DBA_OB_ZONES;
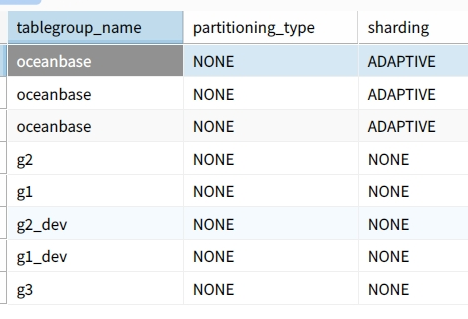
查看下表组个数
SELECT * FROM oceanbase.CDB_OB_TABLEGROUPS;
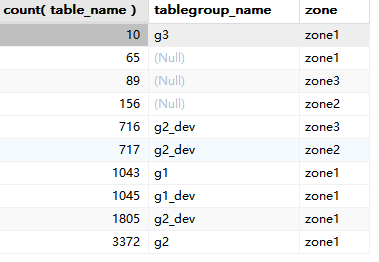
查看下leader分布
select count(table_name), TABLEGROUP_NAME ,zone from DBA_OB_TABLE_LOCATIONS where database_name IN ( ‘db_dev’, ‘db_test’ )
AND role = ‘LEADER’
AND table_type=‘USER TABLE’
group by TABLEGROUP_NAME,zone
order by 1;