


1 个赞
查询下数据库的 datafile_size多大,如果执行失败看看ymal文件
2 个赞

ALTER SYSTEM SET datafile_size = ‘100G’; 是不是就能把原来63G扩展到100G,从而解决问题
1 个赞
1)设置trace信息
SET ob_enable_show_trace=‘ON’;
2)执行select sql
3)获取上个命令的trace
select last_trace_id();
4)获取trace对应的节点
select query_sql,svr_ip from gv$ob_sql_audit where trace_id=‘第三步获取的trace信息’;
5)取对应的svr_ip节点 过滤日志
grep “第三步获取的trace信息” observer.log*
grep “第三步获取的trace信息” rootservice.log*
6)提供日志信息。
1 个赞
磁盘空间是够的有可能是其他问题,先按照上面提供下trace日志
1 个赞
用obdiag自助排查一下,提供一下巡检报告和集群基础信息
- 安装obdiag;OceanBase分布式数据库-海量数据 笔笔算数
- 配置被诊断集群信息;OceanBase分布式数据库-海量数据 笔笔算数
- 执行obdiag check 进行巡检,将巡检报告发出来;
- 执行obdiag gather scene run --scene=observer.base将集群的基本信息发回来;
1 个赞
DDL过程中报磁盘空间不足的问题
obdiag rca run --scene=ddl_disk_full
在线分析最近一小时的日志,诊断出出现过的错误
obdiag analyze log --since 1h
推荐使用obdiag 一键就可以查询出相应日志或问题
1 个赞

目前是一条sql有问题还是所有sql都有相应问题。可以先根据这篇文章查查看
https://www.oceanbase.com/knowledge-base/oceanbase-database-1000000000209971
1 个赞
只有这个sql有问题
1 个赞
df -h 看一下磁盘空间,如果够用先扩容下,如果使用obd安装的请使用obd cluster edit-config
方法进行修改
1 个赞

使用率不高

是的
obd cluster edit-config修改datafile_size后,集群需要重启么
修改保存后 obd会自动帮你执行生效过程,如需重启生效的会自动重启
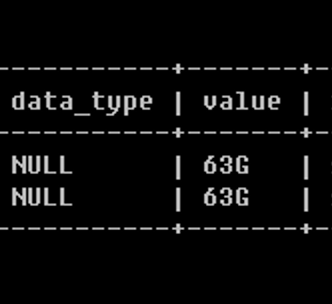
配置文件已经更改:
![]()
但是貌似内存没生效啊,是不是应该用这个ALTER SYSTEM SET datafile_size=100G SCOPE = BOTH;
重启一下试试呢 obd cluster restart ***