【测试环境】
【 obdiag 2.2.0】
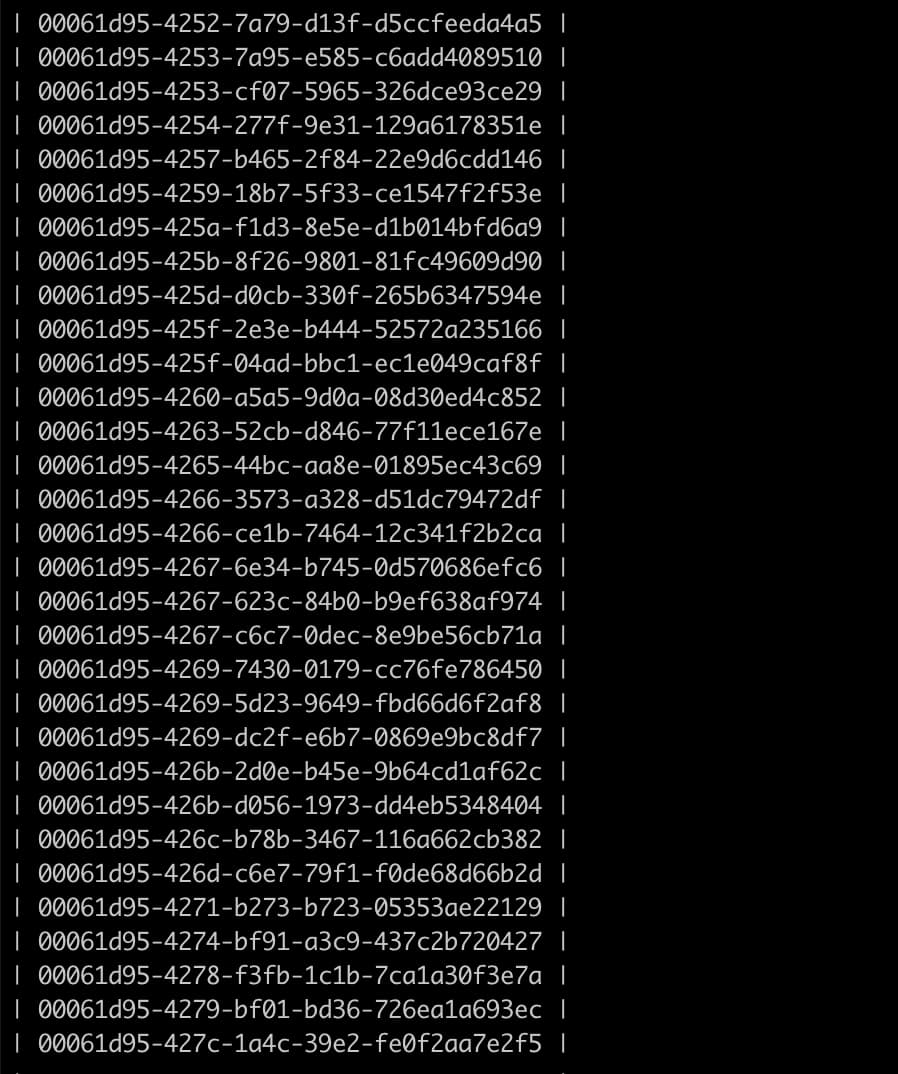
想通过obdiag去分析一个慢SQL的根因,但是执行结果为空:
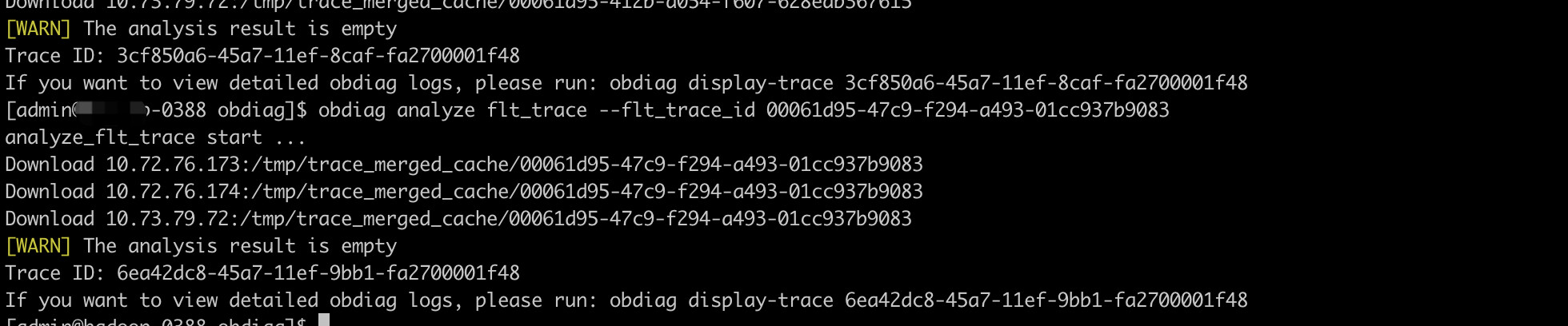
obdiag analyze flt_trace --flt_trace_id xxx
1.此处的flt_trace_id不能是从OCP报警找到的trace_id吗
2.会不会是依赖的日志文件被清理了,但是observer.log的日志目前保存还有几个小时以前的
【测试环境】
【 obdiag 2.2.0】
想通过obdiag去分析一个慢SQL的根因,但是执行结果为空:
obdiag analyze flt_trace --flt_trace_id xxx
1.此处的flt_trace_id不能是从OCP报警找到的trace_id吗
2.会不会是依赖的日志文件被清理了,但是observer.log的日志目前保存还有几个小时以前的
ocp也是通过找到ob里的sql_audit放到ocp表里面 显示出来的
看你看这个文档
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000001050207
有两个问题:
1.我在OCP里看到的SQL Trace ID和ob_sql_audit看到的从风格来说不是一类
OCP:
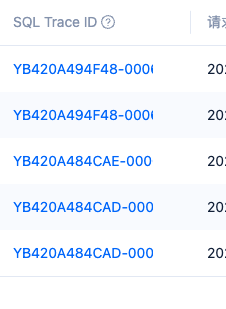
ob_sql_audit:
2.找了最新的几条flt_trace_id找的内容也是空
flt_trace_id 每次都要去日志里翻才能找到吗。那岂不是很难操作
flt_trace_id 可以从sql_audit中查,参见一楼。内核在实现全链路诊断的时候是有控制打印比例的,默认是百万分之一。
– 关闭 Trace
call dbms_monitor.ob_tenant_trace_disable();
– 记录当前租户中的耗时信息,全部记录并全部打印。
call dbms_monitor.ob_tenant_trace_enable(1, 1, ‘ALL’);
这个是触发全部打印日志,也就是100%打印。
但是由于全部打印的话,有一定的开销,所以大部分时候都是在需要排查复杂链路慢的时候打开的。