11小透明
2024 年7 月 8 日 14:52
#1
【测试环境】
2.目前有以下提醒,想问问这些该如何解决
靖顺
2024 年7 月 8 日 15:34
#3
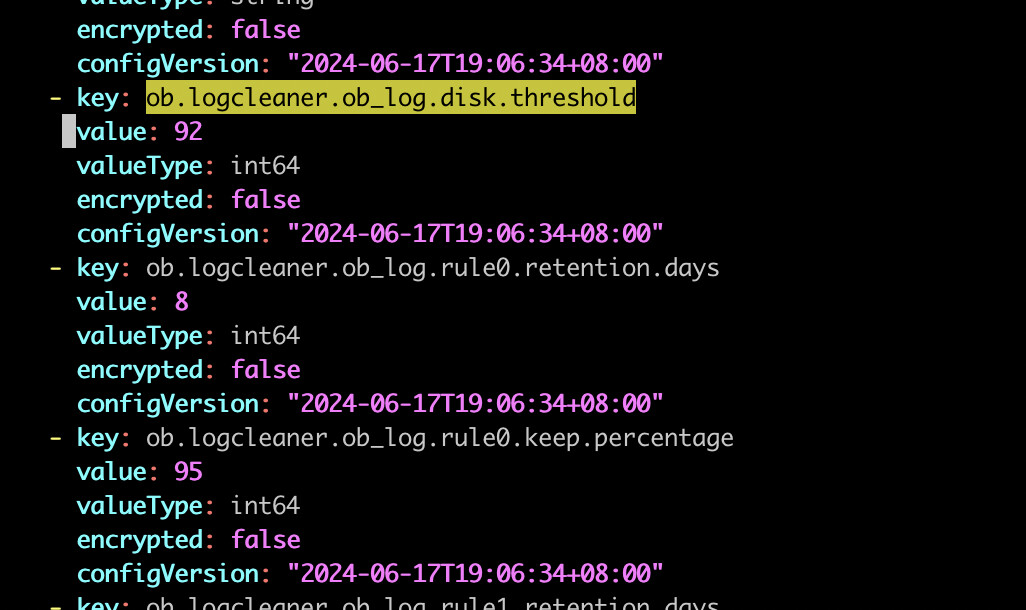
修改agent这个里边的配置即可,/home/admin/ocp_agent/conf/config_properties/ob_logcleaner.yaml,修改完成后十分钟会有定时任务来感知这个参数并生效,无需重启agent。如果想修改完成立即生效的话,就直接重启一下agent就行。
你的第二个问题是obdiag的巡检结果
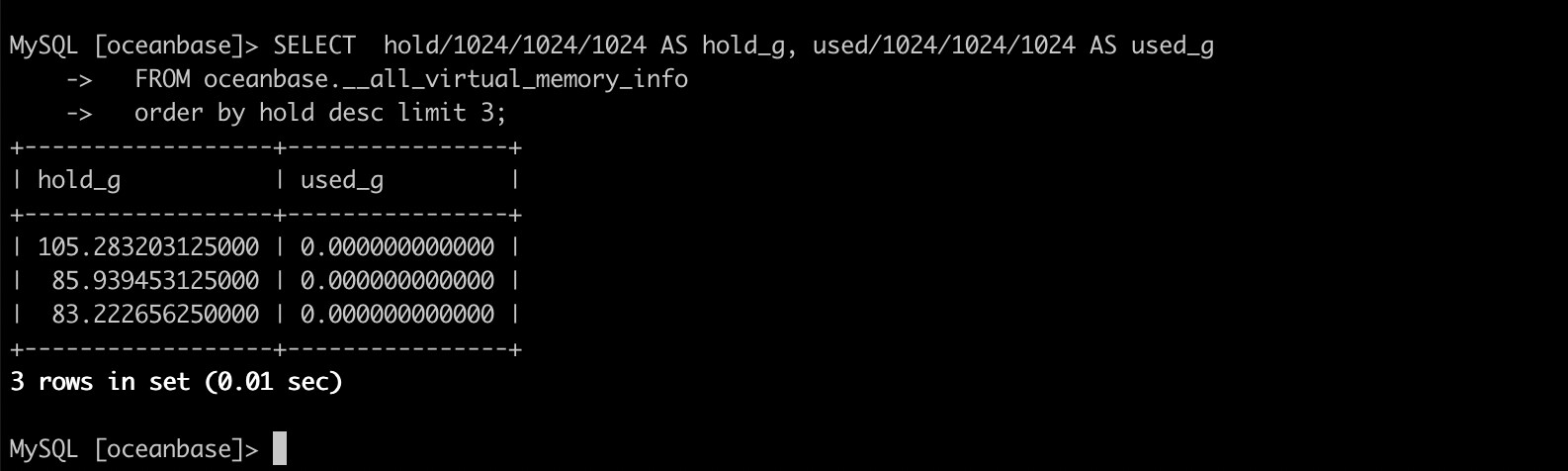
SELECT hold/1024/1024/1024 AS hold_g, used/1024/1024/1024 AS used_g
FROM oceanbase.__all_virtual_memory_info
order by hold desc limit 3;'
11小透明
2024 年7 月 8 日 16:08
#6
日志问题的话,
我改成92%开始回收,但是目前的日志文件还是保留不下来。
靖顺
2024 年7 月 8 日 17:55
#7
看你三个节点的KvstoreCacheMb挺大的,发一下这个结果文件出来,我看看集群规格:
靖顺
2024 年7 月 8 日 23:52
#10
内存的事情:从你发回的obdiag sql_result.txt看了下集群的基本配置,内存这块配置挺大的。
日志清理的问题,除了ocp agent会有清理,其实observer也有清理策略:文档: OceanBase分布式数据库-海量数据 笔笔算数
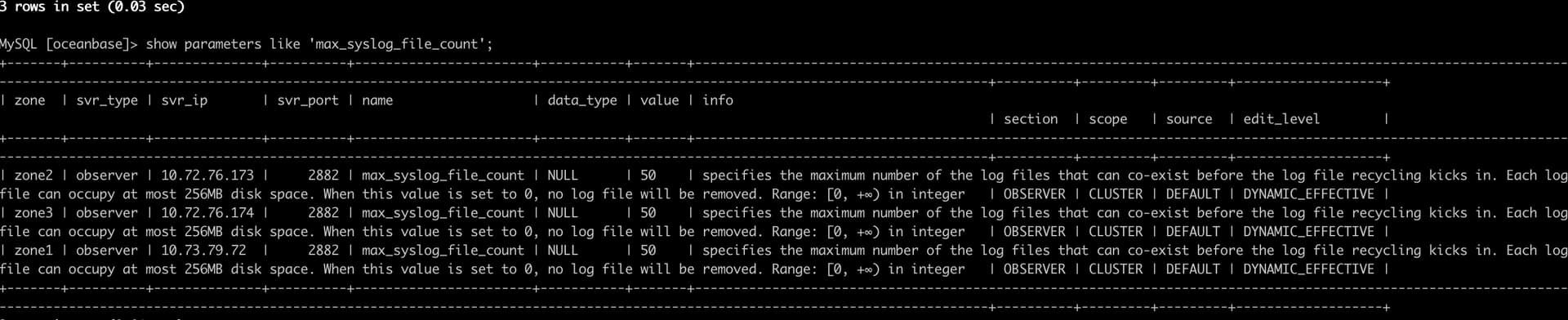
你的集群中:enable_syslog_recycle=true, max_syslog_file_count =50 的
1 个赞
11小透明
2024 年7 月 9 日 13:51
#11
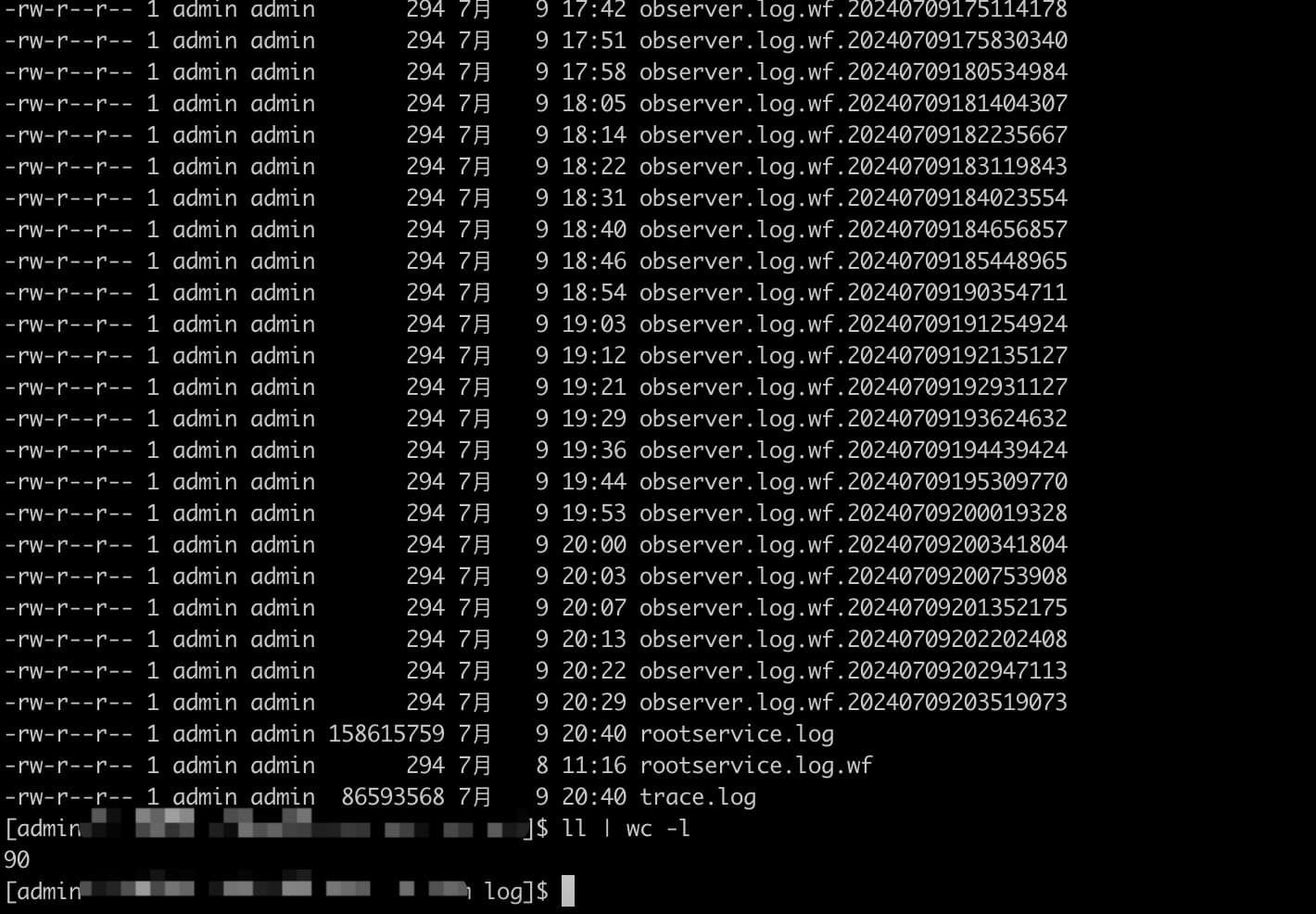
我是设置了这个参数的。但是日志文件并没有保留,而是很少。
靖顺
2024 年7 月 9 日 14:20
#12
你的系统日志盘有多大,我再统一解释一下日志清理,日志清理有两个地方可能控制:
ocp agent:
observer控制
你可以先试试关闭ocp的日志清理看看:
/home/admin/ocp_agent/conf/config_properties/ob_logcleaner.yaml 里的 ob.logcleaner.enabled 对应的 value 调整为 false
/home/admin/ocp_agent/conf/module_config/ob_logcleaner_module.yaml 里的 enabled: ${ob.logcleaner.enabled} 调整为 enabled: false
然后在ocp主机管理-> 点击更多-> 重启ocp_agent (重启一下吧)
渠磊
2024 年7 月 9 日 17:30
#14
disk.disk_hole这个是前置的检查报的,这边特地加了not warning,来表明让用户不用担心,需要使用后续的检查来进一步定位,若没有后续的其他报警就不用在意
11小透明
2024 年7 月 9 日 20:13
#15
好像有点不对劲,把这些参数改成false之后,好像所有日志都不清理了。总数也超过了50。
靖顺
2024 年7 月 9 日 21:10
#17
你是只改了ocp_agent的清理策略为false吧,observer上的配置你没动吧。两个策略你总是要留一个的。