

【 使用环境 】测试环境(麒麟V10服务器版本)
【 使用版本 】数据库版本:4.3.1 社区版 单机版部署 obd demo 导数工具版本:4.3.0
【问题描述】使用导数工具导出数据库时,每导出一次,使用free -h查询available内存就会少将近100M,obd cluster restart demo后内存又能释放出来,想知道有什么参数可以优化的,或者能不重启demo就能释放内存的方法
您这里服务器内存有多大的,表的数据有多少的
free -h的输出贴出来
每次使用obdumper导数之后可用内存都要减少近100M吗?导出的是相同的表吗?导出结束后一直不释放吗?
您好,服务器是16G的,表数据最大表约80万条,其他表数据量不是很大,导出数据库文件夹大约780M
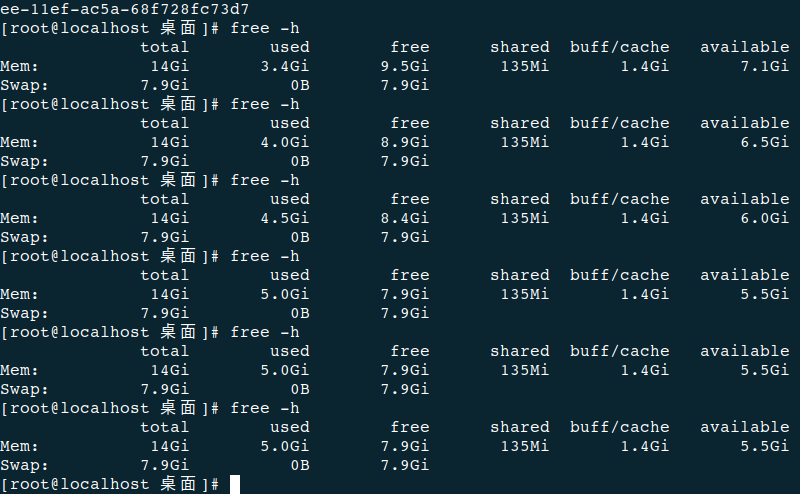
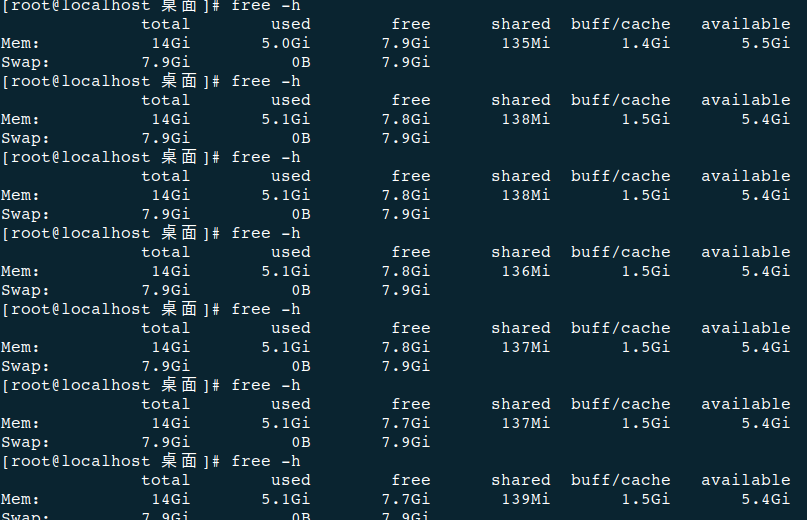
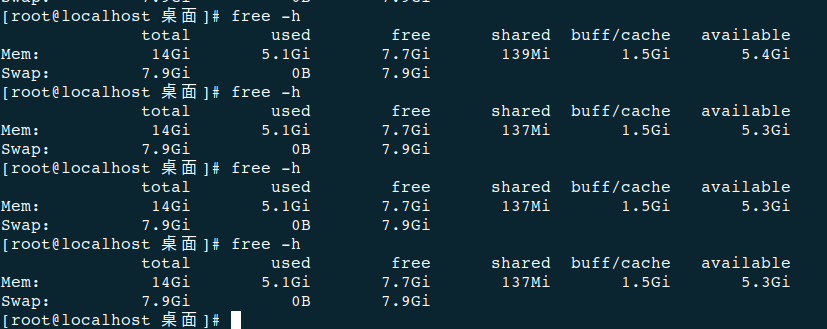
您好!基本每次导出都会占用一些内存,重启obd cluster edit-config demo才能释放出来
参考如下方法处理:
1.查看内存配置
show parameters like ‘%memory_limit%’;
每次导出后,确认一下obdumper进程是否结束
您好,是我的描述不太全面,我用的windows服务器用的导数工具,数据库在麒麟V10服务器,memory_limit 设置的10G,然后每次导出后数据库服务器的可用内存几乎都会减少100M左右
那这个现象就是预期的,你memory_limit 设置的10G,ob最高就可能使用内存10G,你可以调低memory_limit 的值再试试,具体参考
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000000821140
调低内存后导出时会报 No memory or reach tenant memory limit内存不足错误,还发现一个使用find_in_set函数在memory_limit是8G的时候查询不出结果,配置成10G的时候才能查询出结果,您还知道调整哪些参数优化数据库吗?或者不用重启就能释放数据库占用内存的方法。
-
重启demo(为了在排查时,故障现象更加明显,我看到你执行free -h的输出,第一次导出时,内存少了将近1.5GB)
-
重启后,再次导出数据。 同时执行如下SQL,每隔几秒钟执行一次:
select
tenant_id,
svr_ip,
mod_name,
sum(hold) / 1024 / 1024 module_sum_MB
from
oceanbase.__all_virtual_memory_info
group by
tenant_id,
svr_ip,
mod_name
having
module_sum_MB > 100
order by
tenant_id,
svr_ip,
module_sum_MB desc;
为了观察在导出数据的时间,observer的哪个组件占用内存会在明显的增大。 -
在导出数据的同时,操作系统层面 ,运行top,ps等相关的命令,按照内存进行排序,查看是哪些进程占用内存比较大,或者占用内存有明显的增大。


这个参数刚安装数据库的时候就设置为50啦,但是memory_limit设置10G以下还是会有这些问题(导出时会报No memory or reach tenant memory limit内存不足错误,还发现一个使用find_in_set函数在memory_limit是8G的时候查询不出结果)。
您好,第一次导出后,查询这个SQL的结果
obdneicun.txt (8.8 KB)
第二次导出后,查询这个SQL的结果
obdneicun2.txt (1.6 KB)
然后监控了进程占用内存和CPU的占用率,是OceanBase占用内存一直在升高
- 从obdneicun.txt中可以看出:
obclient [oceanbase]> select tenant_id, svr_ip, mod_name, sum(hold) / 1024 / 1024 module_sum_MB from oceanbase.__all_virtual_memory_info group by tenant_id, svr_ip, mod_name having module_sum_MB > 100 order by tenant_id, svr_ip, module_sum_MB desc;
±----------±----------±--------------±--------------+
| tenant_id | svr_ip | mod_name | module_sum_MB |
±----------±----------±--------------±--------------+
| 1 | 127.0.0.1 | KvstorCacheMb | 404.00000000 |
| 1 | 127.0.0.1 | Memstore | 142.87500000 |
| 1 | 127.0.0.1 | CoStack | 132.89062500 |
| 500 | 127.0.0.1 | CACHE_MAP_BKT | 128.01960754 |
±----------±----------±--------------±--------------+
4 rows in set (0.021 sec)
…
obclient [oceanbase]> select tenant_id, svr_ip, mod_name, sum(hold) / 1024 / 1024 module_sum_MB from oceanbase.__all_virtual_memory_info group by tenant_id, svr_ip, mod_name having module_sum_MB > 100 order by tenant_id, svr_ip, module_sum_MB desc;
±----------±----------±--------------±--------------+
| tenant_id | svr_ip | mod_name | module_sum_MB |
±----------±----------±--------------±--------------+
| 1 | 127.0.0.1 | KvstorCacheMb | 1768.00000000 |
| 1 | 127.0.0.1 | SqlPhyPlan | 154.53851318 |
| 1 | 127.0.0.1 | Memstore | 142.87500000 |
| 1 | 127.0.0.1 | CoStack | 132.89062500 |
| 500 | 127.0.0.1 | CACHE_MAP_BKT | 128.01960754 |
±----------±----------±--------------±--------------+
5 rows in set (0.003 sec)
整个数据导出过程中,observer的KvstorCacheMb模块占用的内存从最开始的404MB增长到了1768MB。 这基本上也找出了内存消耗的原因。
如果想进一步分析为什么在导出数据时,kvstorcache占用如此多的内存,可以在故障重现时,执行如下SQL:
select
tenant_id,
svr_ip,
cache_name,
priority,
cache_size / 1024 / 1024 as cache_size_MB,
cache_store_size / 1024 / 1024 as cache_store_size_MB
from
oceanbase.__all_virtual_kvcache_info
where
cache_size > 100000000
order by
cache_size desc;
找出是哪种kvcache占用大量内存。
然后有两种处理方式:
1、针对这种kvcache,调整它的priority,让它在内存中存留的优先级非常低。
2、手动flush这种kvcache. 示例:ALTER SYSTEM FLUSH KVCACHE TENANT=‘sys’ CACHE=‘schema_cache’;
1 个赞

谢谢您的回答,除了您的建议,我找到了cache_wash_threshold这个参数,可以自动释放内存,试了导出数据库后,服务器可用内存几乎没有变化。
1 个赞