

observer0625.log (3.0 MB)
截取一部分,整个的太大了
按照这个文档将第2步的巡检结果和第4步的日志分析结果先发出来看看吧
从obdiag 上看你的集群问题除了内存不足173节点还有磁盘空间的问题。
再用obdiag 那一份集群的基本信息出来。
obdiag gather scene run --scene=observer.base
173节点空间挺足的呀
Filesystem Size Used Avail Use% Mounted on
devtmpfs 504G 0 504G 0% /dev
tmpfs 504G 12K 504G 1% /dev/shm
tmpfs 504G 572M 504G 1% /run
tmpfs 504G 0 504G 0% /sys/fs/cgroup
/dev/sdi3 40G 4.0G 34G 11% /
/dev/sdi2 488M 117M 336M 26% /boot
/dev/mapper/emcentos-lvopt 164G 2.1G 154G 2% /opt
tmpfs 101G 0 101G 0% /run/user/0
/dev/mapper/vgdata-lvdata 21T 2.6T 19T 13% /data
/dev/mapper/vglog-lvlog 3.5T 2.6T 951G 74% /log
/dev/mapper/vghome-lvhome 3.5T 20G 3.5T 1% /home/admin/oceanbase
tmpfs 101G 0 101G 0% /run/user/1001
tmpfs 101G 0 101G 0% /run/user/1000
发现几个点,我提一下:
-
从你发回来的obdiag sql_result信息中看到了ocp租户只给了1c2GB的配置,这个有点小,ocp这个租户是要存监控数据和ocp的元数据的, 生产环境的话可以看看这个指南:OceanBase分布式数据库-海量数据 笔笔算数
-
从obdiag 日志分析的结果看到了下面的几个报错
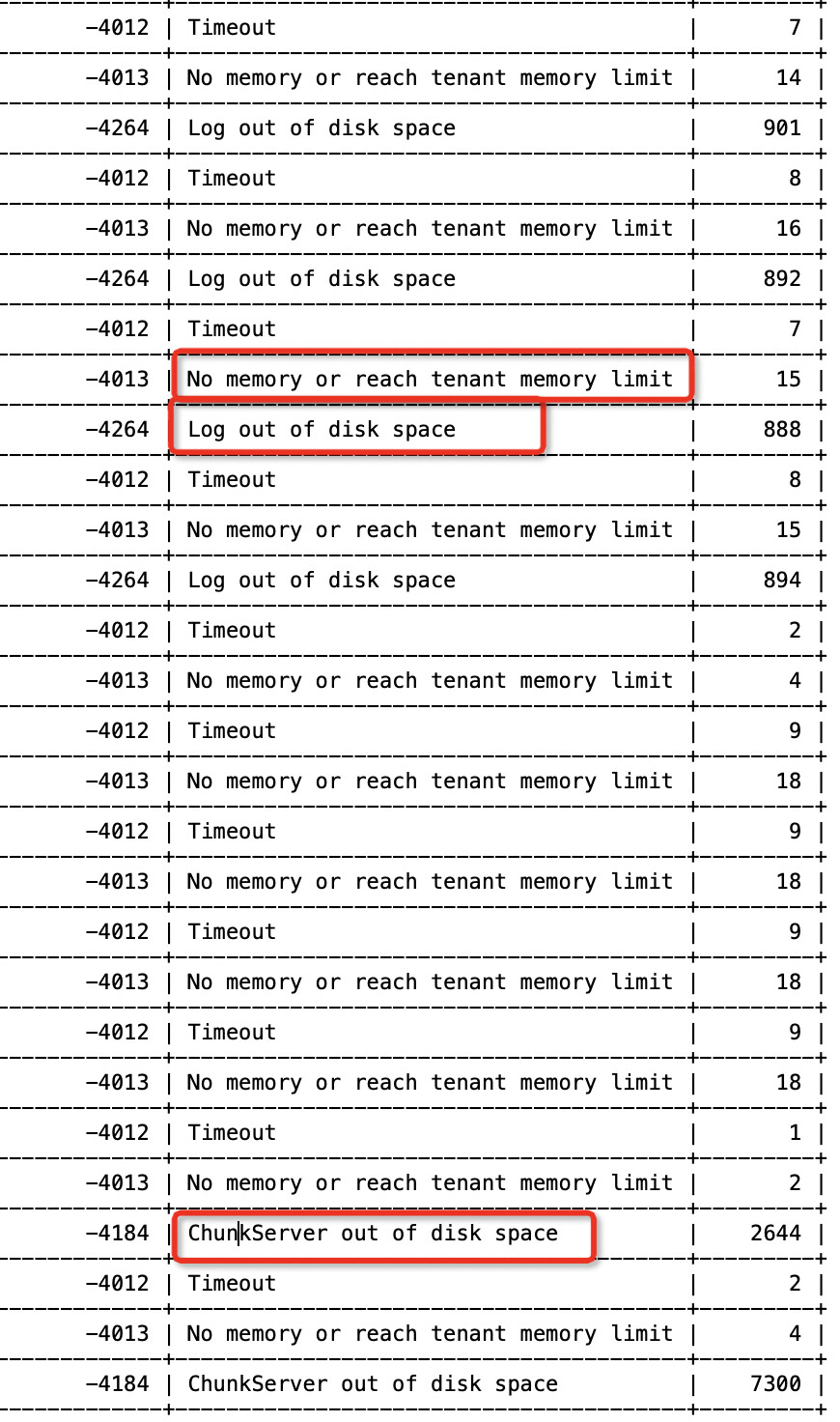
有点像是clog盘满引起的,你用obdiag 2.2.0版本的clog盘满根因分析来查一下
obdiag rca run --scene=clog_disk_full
ocp做了扩容了
root@EM-1RLBCR3: ~/.obdiag/check_report# obdiag rca run --scene=clog_disk_full
[Not Need Execute]ClogDiskFullScene need not execute: Not find tenant_ids about clog_disk_full.
rca finished. For more details, the result on ‘./rca//obdiag_clog_disk_full_20240626083200’
±-------------------------------------------------+
| record |
±-----±------------------------------------------+
| step | info |
±-----±------------------------------------------+
| 1 | Not find tenant_ids about clog_disk_full. |
±-----±------------------------------------------+
下面3个信息提供下。
strings /home/admin/oceanbase/etc/observer.config.bin 看下配置。
sys租户登录:
— 查看磁盘剩余空间
select * from __all_virtual_disk_stat;
— 查看所有租户资源分配信息
select a.zone,a.svr_ip,b.tenant_name,b.tenant_type,
a.max_cpu, a.min_cpu,
round(a.memory_size/1024/1024/1024,2) memory_size_gb,
round(a.log_disk_size/1024/1024/1024,2) log_disk_size,
round(a.log_disk_in_use/1024/1024/1024,2) log_disk_in_use,
round(a.data_disk_in_use/1024/1024/1024,2) data_disk_in_use
from oceanbase.gv$ob_units a join oceanbase.dba_ob_tenants b on a.tenant_id=b.tenant_id
order by b.tenant_name;
问题已经处理好了,可能跟时钟不同步有关系,集群数据使用满是因为没有开启数据文件自动管理,设置完之后问题就都解决了