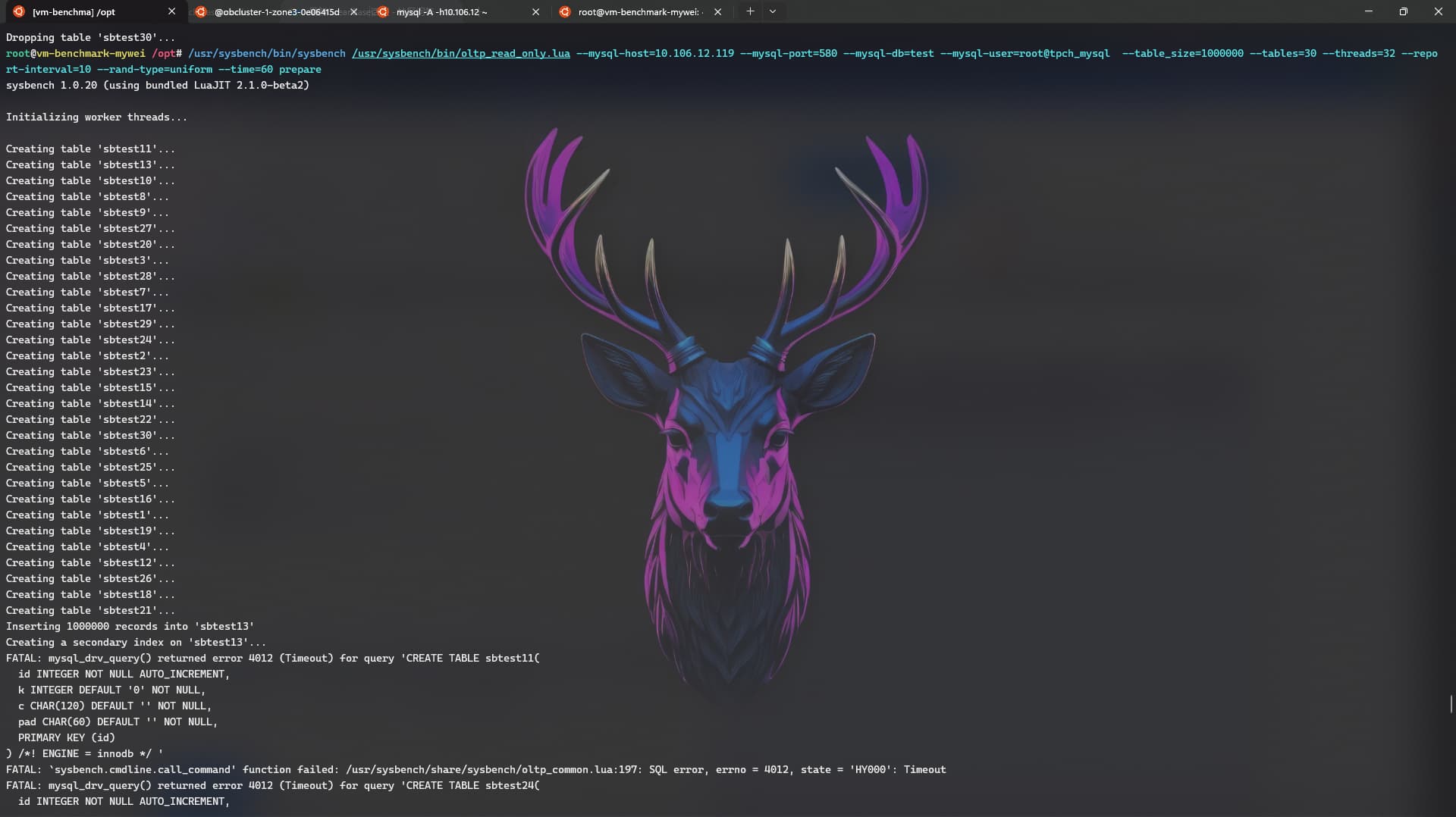
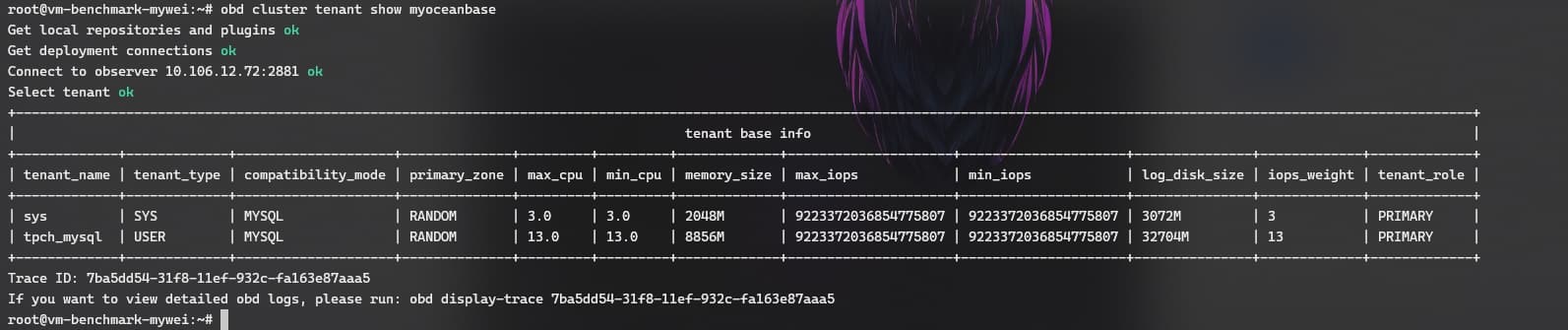
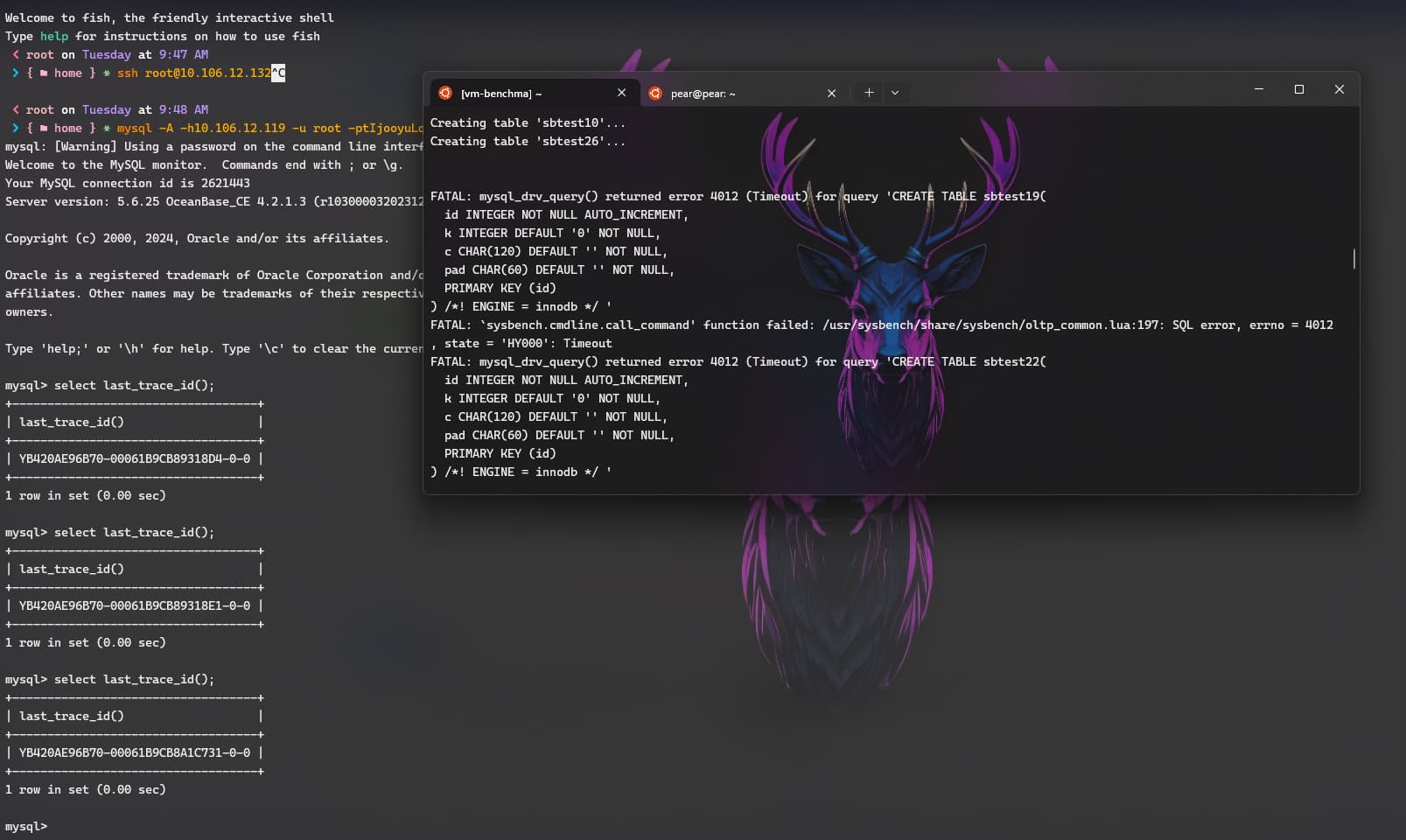
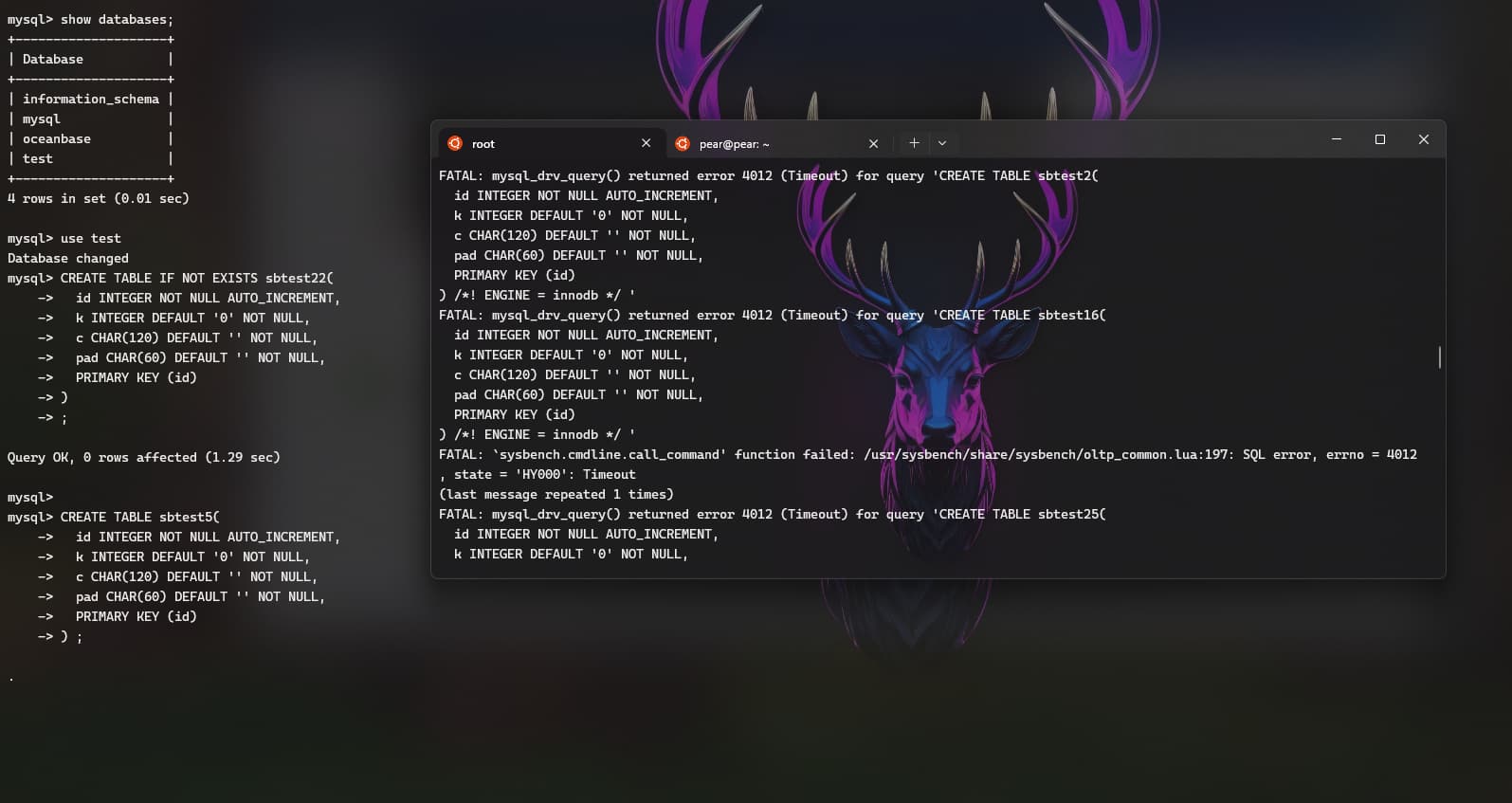
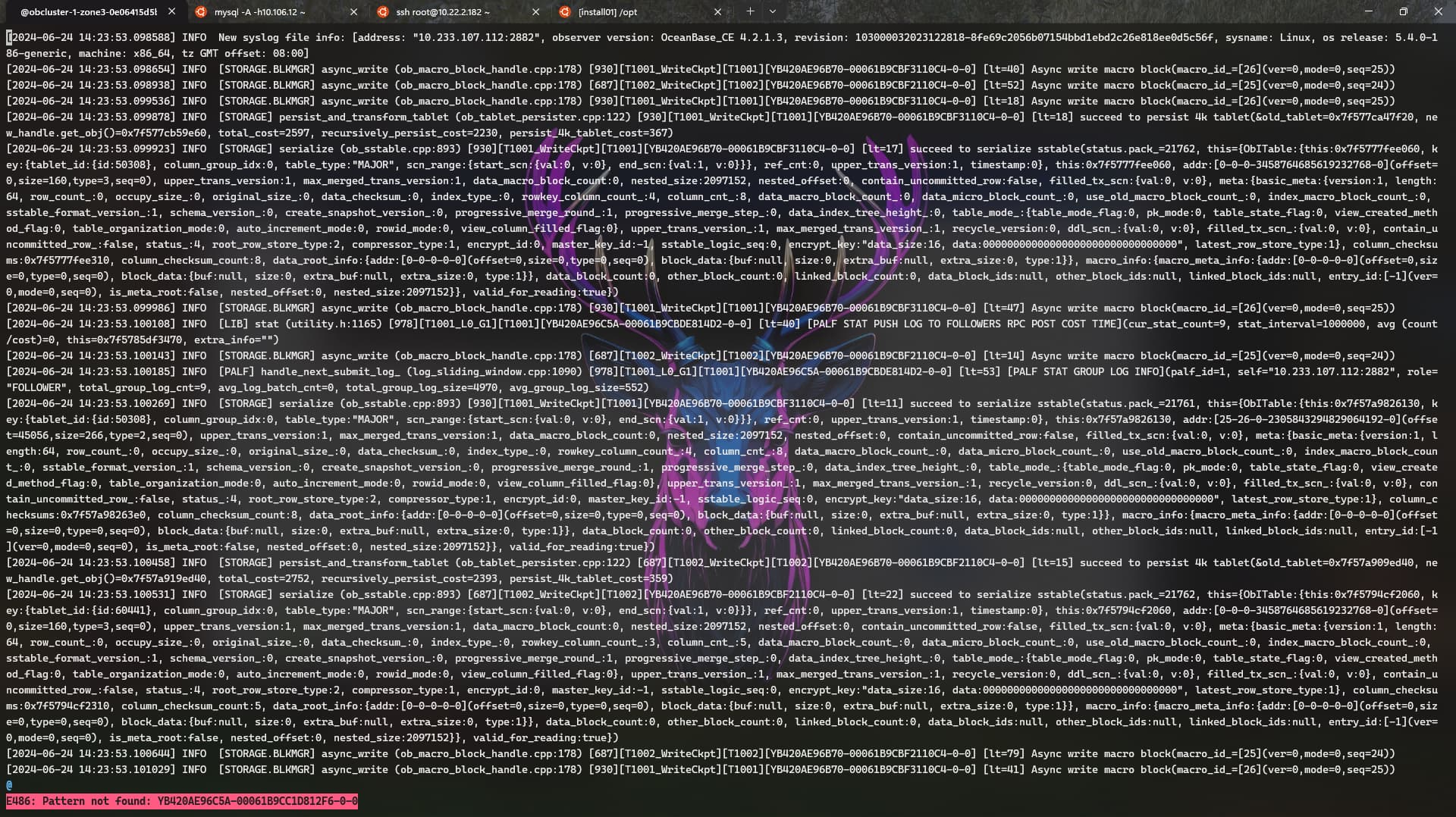
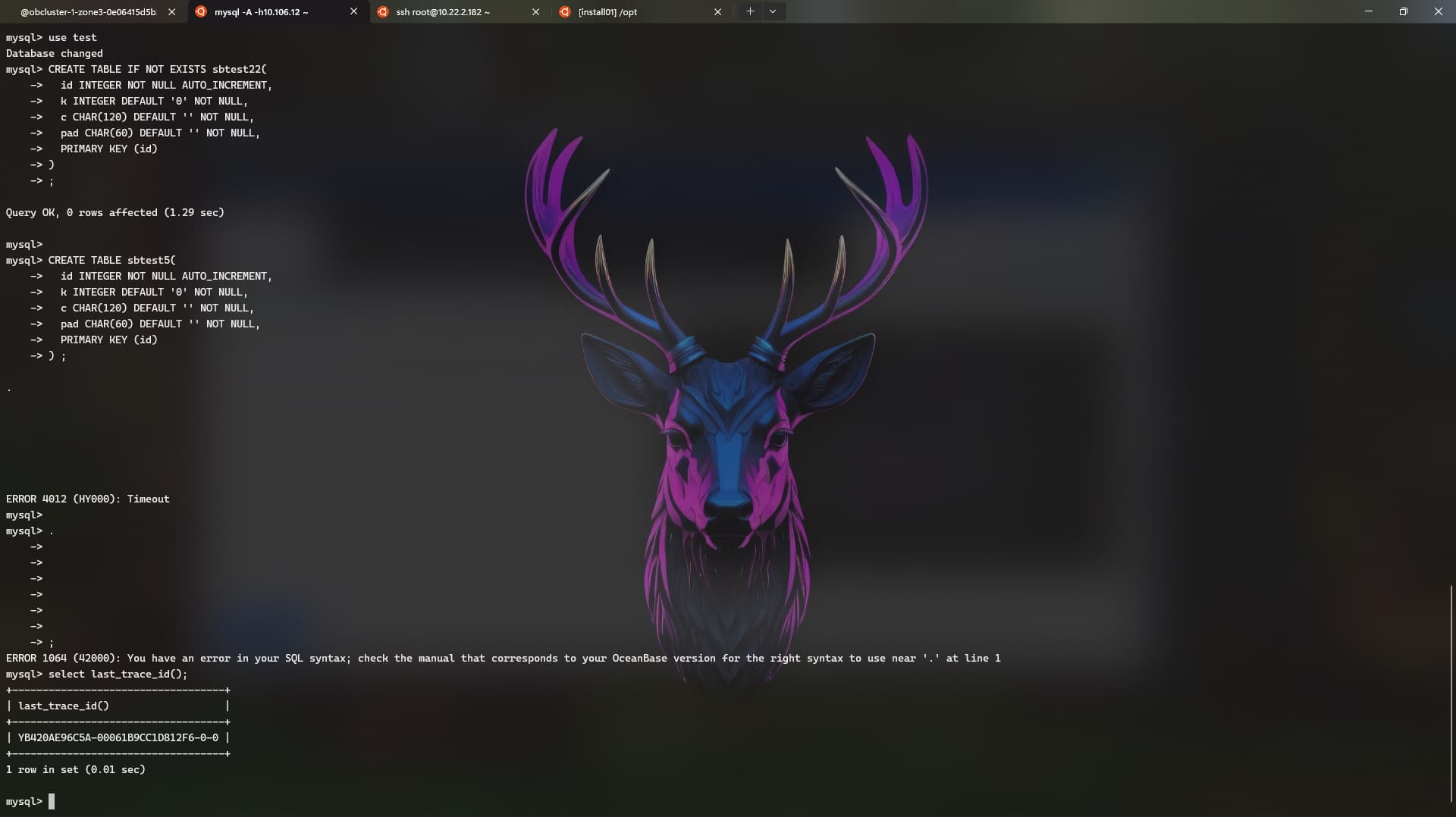
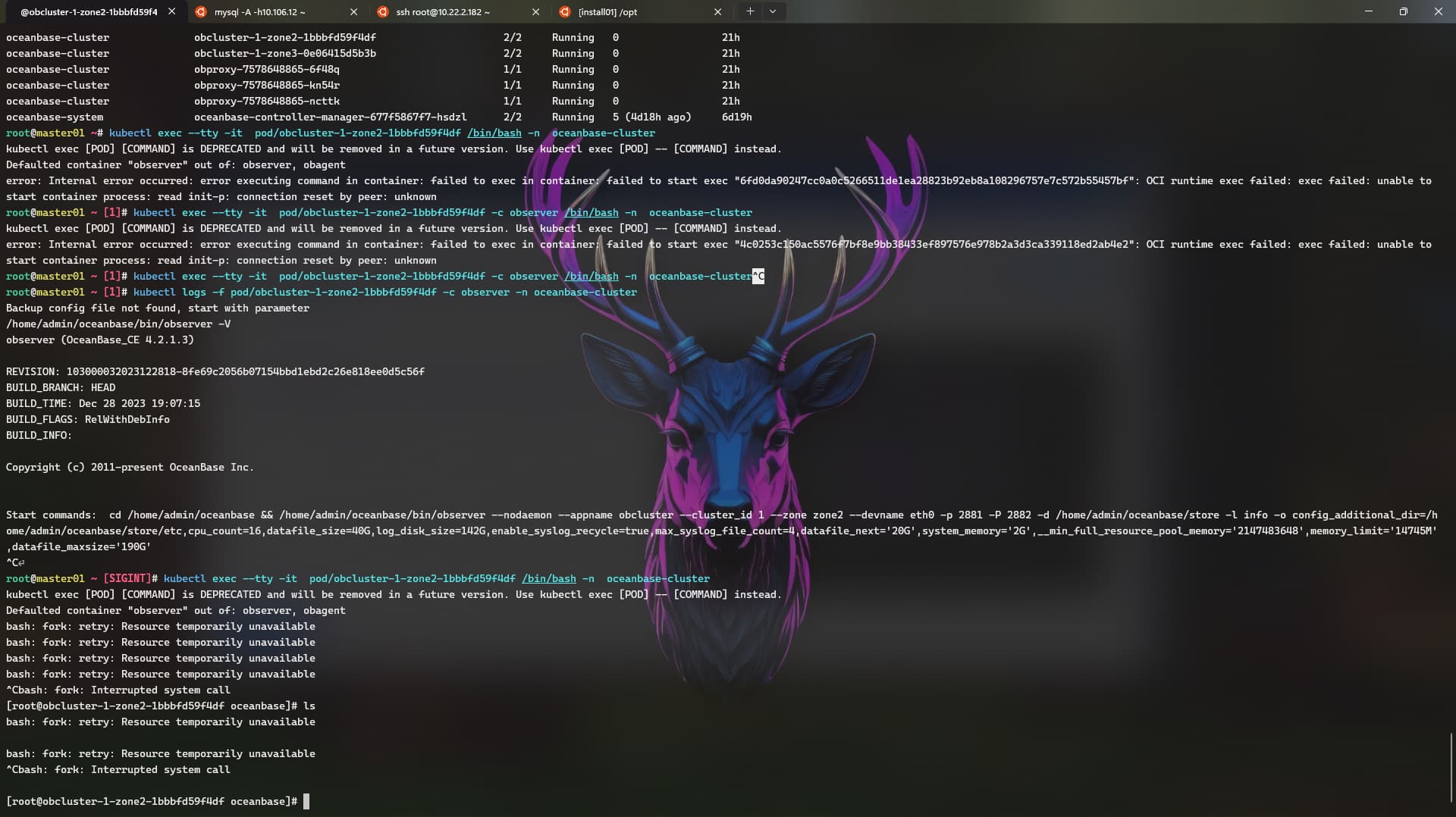
手动连接下集群,执行下建表语句,看下会超时吗。看下是不是client->proxy->observer的网络延迟太大了。在测试租户下把这两个参数调大点试试
set global ob_query_timeout=36000000000;
set global ob_trx_timeout=36000000000;
这两个参数已经配置很大了。在租户下配置了这些参数:
SET GLOBAL ob_sql_work_area_percentage = 80;
SET GLOBAL ob_query_timeout = 36000000000;
SET GLOBAL ob_trx_timeout = 36000000000;
SET GLOBAL max_allowed_packet = 67108864;
parallel_servers_target = max_cpu * server_num * 8
SET GLOBAL parallel_servers_target = 624;