你的需求想法是好的,实现方式却有点不妥。
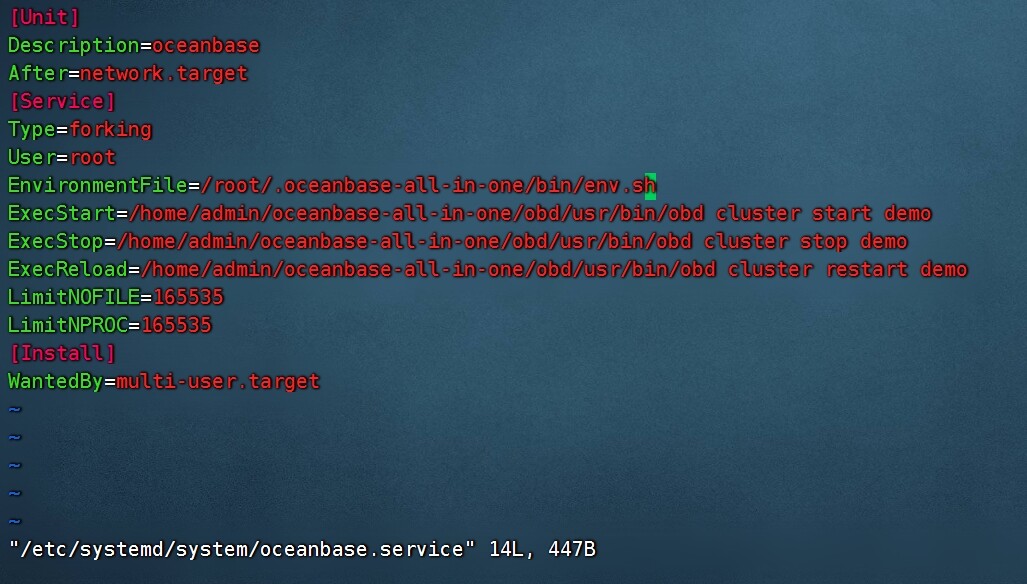
配置 OB 的 systemd 服务
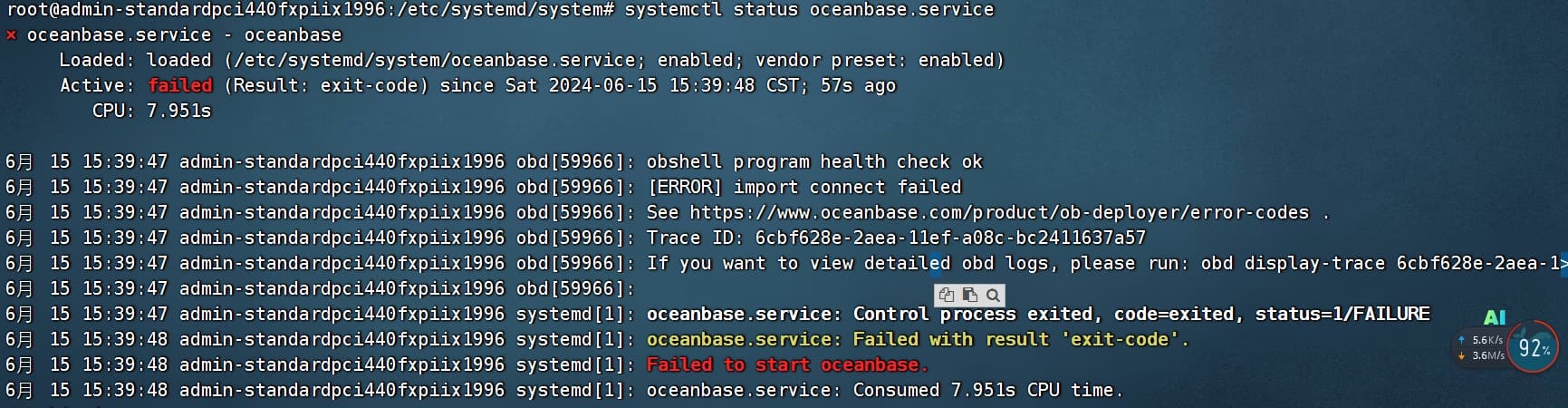
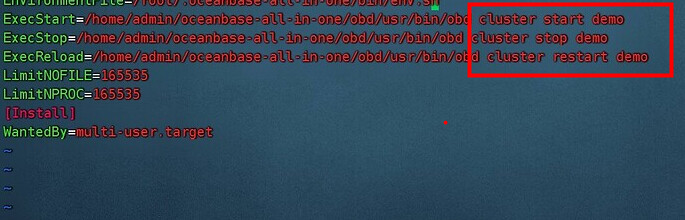
systemd 服务通常是linux 主机用来管理本机服务的,在 systemd 服务里调用 obd 命令去管理一个 OB 集群服务,这个 OB 的节点却可能是在其他服务器上。这种管理方式并不妥。
如果把 obd 命令所在主机称之为 “中控机”,OB 集群的机器不在中控机上。
试想一下,如果中控机重启了,而 OB 集群服务器自身并无异常,中控机又来一个 obd cluster start ,这不是添乱吗。即使这个命令能做到不报错,去启动一个已经启动了的集群,这个想法就是不对的。
另外一种情形,如果中控机无异常,OB 集群的一台机器重启了,那个故障机器的 observer 进程还是要自己拉起来。当然你也可以在中控机上使用 obd 命令带上参数去拉起。
我推测你的目的是想实现 OB 集群服务器如果重启了,能自动把 observer 进程拉起来。那实现方式就是应该去 OB 集群节点上配置一个 systemd 服务。
下面是参考。
[root@server061 ~]# cat /etc/systemd/system/observer.service
[Unit]
Description=observer systemd service
After=network.target
[Service]
Type=forking
User=admin
Environment="LD_LIBRARY_PATH=/home/admin/oceanbase/lib"
WorkingDirectory=/home/admin/oceanbase
ExecStart=/home/admin/oceanbase/bin/observer
ExecStartPost=/bin/sleep 1
ExecStop=/usr/bin/kill -9 $MAINPID
ExecStopPost=/bin/sleep 3
[Install]
WantedBy=multi-user.target
在使用这个脚本之前,先在 OB 机器上把 observer 进程杀掉。
kill -9 `pidof observer`
sleep 3
ps -ef|grep observer |grep -v grep
之所以 sleep 一下,是生产环境,杀一个进程,是需要点时间。
然后就可以使用 systemd 服务来管理 observer 启动。
[root@server061 ~]# systemctl start observer
[root@server061 ~]# systemctl status observer
● observer.service - observer systemd service
Loaded: loaded (/etc/systemd/system/observer.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2024-06-22 08:59:35 CST; 7s ago
Process: 10587 ExecStopPost=/bin/sleep 3 (code=exited, status=0/SUCCESS)
Process: 10584 ExecStop=/usr/bin/kill -9 $MAINPID (code=exited, status=0/SUCCESS)
Process: 10689 ExecStartPost=/bin/sleep 1 (code=exited, status=0/SUCCESS)
Process: 10679 ExecStart=/home/admin/oceanbase/bin/observer (code=exited, status=0/SUCCESS)
Main PID: 10688 (observer)
Tasks: 65
Memory: 191.1M
CGroup: /system.slice/observer.service
└─10688 /home/admin/oceanbase/bin/observer
Jun 22 08:59:34 server061 systemd[1]: Starting observer systemd service...
Jun 22 08:59:35 server061 systemd[1]: Started observer systemd service.
[root@server061 ~]# ps -ef|grep observer
admin 10688 1 8 08:59 ? 00:00:01 /home/admin/oceanbase/bin/observer
root 10920 2040 0 08:59 pts/2 00:00:00 grep --color=auto observer
停止 observer 进程
[root@server061 ~]# systemctl stop observer
[root@server061 ~]# ps -ef|grep observer
root 11805 2040 0 09:00 pts/2 00:00:00 grep --color=auto observer
将这个服务设置为 自启动模式。
[root@server062 ~]# systemctl enable observer
Created symlink from /etc/systemd/system/multi-user.target.wants/observer.service to /etc/systemd/system/observer.service.
[root@server062 ~]#
observer 启动提醒
首先 observer 的运行用户建议是 admin 而不是 root 。如果使用 obd 部署的集群,特别注意要改这个。
所以,我上面的脚本是运行在 admin 用户下的。
第二,observer 的启动命令的工作目录必须在 软件目录下。我这里是 /home/admin/oceanbase。
启动方式不要求是绝对路径,不过 systemd 服务文件要求必须是绝对路径我才这么写的。
但并不意味着在任意目录下运行 /home/admin/oceanbase/bin/observer 都可以启动 observer。
第三,这个启动方式只适合于 OB 集群已经初始化成功了,所以 observer 启动的时候没有传递命令行参数,因为会自动读取工作目录下的 etc/observer.config.bin 里的参数。
第四, observer 的启动和停止都是需要时间的,特别是生产环境。所以不能频繁的对这个服务调用 start 和 stop 。start 之前要确保进程已经退出,stop 也要留时间等进程退出。所以我在服务文件里加上了 sleep 语句。
不管从哪条路入门的 OB ,最终作为 OBDBA 都需要掌握 observer 的手动启动方法和停止方法。 OBD 只是一个运维工具,只有理解了 observer 进程的启动和停止方法,才可以放心使用 obd 自动化去管理 OB 集群。
上面我的例子中的 OB 是企业版,OCP 部署的。企业版的 OCP 管理 OB 集群的时候会在每个节点增加一个启动脚本,自动拉起 observer 和 obproxy 。社区版也可以参考,详情参考: OBServer 服务器重启后 observer 进程未能自动启动-OceanBase知识库
更多 OB 集群手动部署和启动方法可以参考: OB 4.2 集群手动部署方法 (qq.com)