11小透明
2024 年6 月 14 日 16:47
#1
【测试环境】
CREATE TABLE test02 (id bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT ‘自增主键’,uuid varchar(64) DEFAULT NULL,os tinyint(4) DEFAULT NULL COMMENT ‘os’,create_time datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ‘创建时间’,update_time datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ‘更新时间’,id),I_oaid (uuid) BLOCK_SIZE 16384 LOCAL,I_create_time (create_time) BLOCK_SIZE 16384 LOCAL,I_update_time (update_time) BLOCK_SIZE 16384 LOCAL
SELECT * from test02 where did=‘xxx’ order by update_time desc;【执行2ms】
发现了时快时慢的例子,分析执行计划得知是有时扫了全表,手动收集下统计信息才能正常。
能提供一下快慢时候的explain extended执行计划吗?
道阻且長
2024 年6 月 14 日 16:56
#3
1,先试着找下真实原因。分析下执行计划的差异。另外测试数据和生产数据的分布规律是一样的吗?一般来说尽量真实的数据统计信息才行。
Optimizer Hint-OceanBase 数据库-OceanBase文档中心-分布式数据库使用文档
计划绑定-OceanBase 数据库-OceanBase文档中心-分布式数据库使用文档
表里面的数据是什么时候插入的,现在数据变更量大吗,按理说不需要经常收集统计信息的。
11小透明
2024 年6 月 14 日 16:57
#5
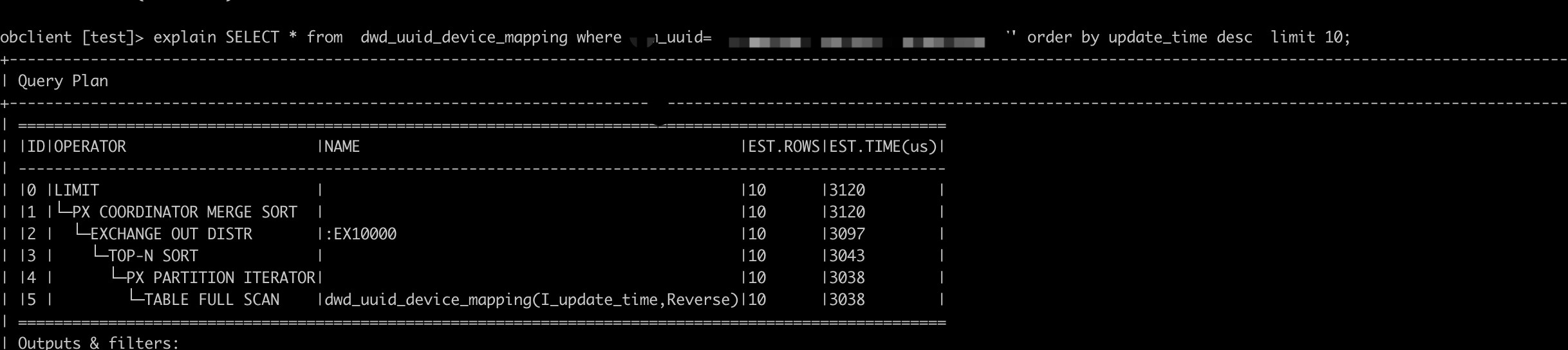
手动统计信息前(这个也不是稳定每次都是慢,时快时慢,复现的几次有发现读全表的执行计划)
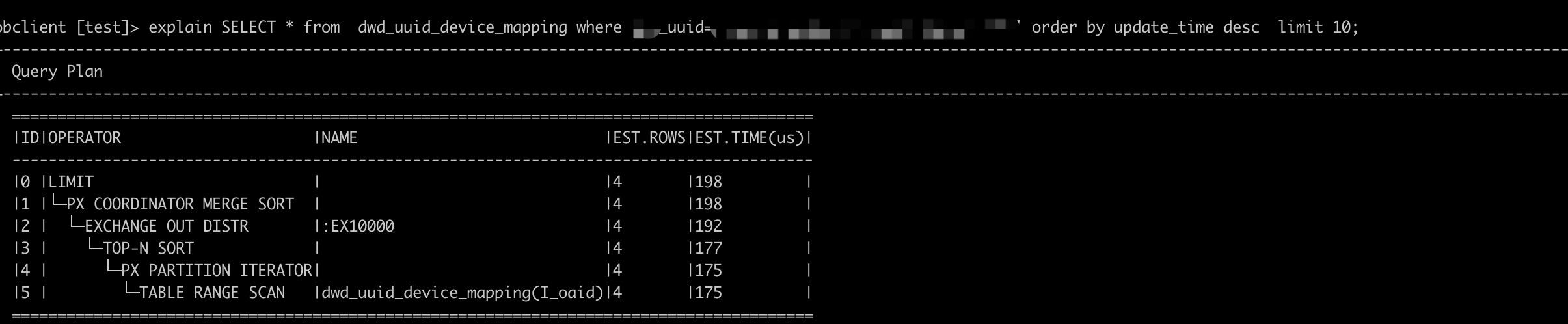
手动统计信息后:
liuxzh
2024 年6 月 14 日 16:57
#6
一般是数据量有较大的变化时,都是要手动执行统计信息收集。
11小透明
2024 年6 月 14 日 17:03
#7
如果这个表是需要实时导入的呢。那这样会不会有不稳定风险。
liuxzh
2024 年6 月 14 日 17:07
#8
有的,准实时的导入累积起来会加大转储,通过转储触发合并这种方式不一定适用实际场景,
这种是buffer表的场景,如果表一直在实时导入,是有可能导致这种不稳定的情况发生,一个是因为查询的链路变长了,第二个是因为优化器获取到的统计信息和实际表中的数据不匹配,4.x没有buffer表的概念了,可以看下自适应合并参数_enable_adaptive_compaction的值,另外个人理解table full scan算子不一定代表是全表扫描,像这个例子中,应该是对i_update_time的全扫描。
liuxzh
2024 年6 月 14 日 17:22
#10
3X版本会有一个处理机制:
淇铭
2024 年6 月 14 日 17:38
#11
1.使用sql_audit诊断
兹拉坦
2024 年6 月 16 日 23:16
#12
1 个赞