

如题,如果我按照 ID Hash 进行了表分区,分了 128 个区,请问我能够通过什么函数(或其他手段),知道某个 ID 在哪个分区吗 ?
你直接查一下这个id,explain 一下执行计划,有写出这个条件走的哪个分区
我不是针对某个查询语句去分析SQL哦,我是想预先知道它查询的是哪个分区,这样我就好提前通过 PARTITION 子句去优化限定只查询该分区(可能不止一个)的数据。
我的有些业务查询并不包含分片键,但是 它 和 分片键 之间具有某种映射关系,我需要手动根据映射关系来限定优化查询分区。
select partition_hash(id) % 分区数;

意思是没有其他办法吗 ?有没有类似一个函数,传入分片键就显示数据应该位于哪个分区的 ?
因为我的目的不是想这么用。
比如,我的分区是基于 HASH ( ID / 1000000 ) 来分区的,例如 ID = 23000000 ,实际上是 HASH ( 23 ),23 是 一个用户ID。
但是我的业务查询条件是 WHERE user_id = 23,并不包含分片键,默认会查询所有分区。
所以我需要自己构造一个附加的 ID 查询条件,例如 AND id >= 23000000 AND id <= 23999999,才能只查询 HASH(23) 所在的分区。
然而,OceanBase 是难以通过 ID 范围查询去优化命中 HASH 分区的,所以我需要预先知道 HASH(23),是哪一个分区,才能通过添加 PARTITION ( 分区名称 ) 子句 来优化查询。
而且有时候还不只是 = 查询, 还可能是 IN 查询,比如 user_id IN ( 23, 24, 25 )。如果我预先知道 这3个ID 的分区名称,就可以在 SQL 中预先指定,以避免遍历所有分区。
这个方式你也查一下呢
另外,hash的写法,你别用>= <=来构造查询条件,一样会查到很多个分区,要用等值条件=
谢谢,我试试。
是的,我猜数据库也没这么智能,所以才需要自己预先知道分区名称,自己手动指定,这样才能准确命中分区,避免遍历所有分区。
在此谢谢各位热心回复的朋友,非常感谢 ~!
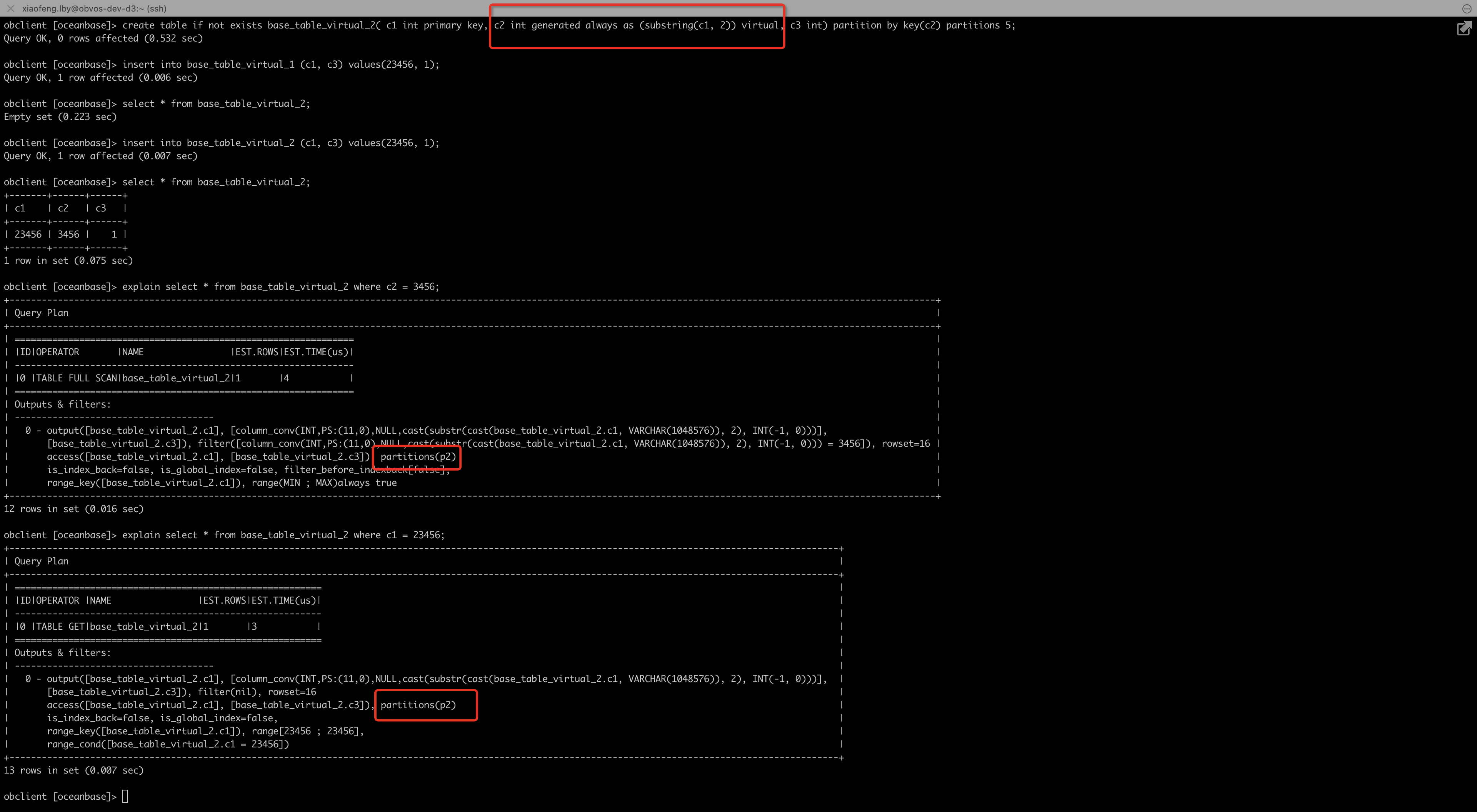
这里还有一个问题,为啥不直接拿 user_id 去做 hash 分区,必须要用 HASH ( ID / 1000000 ) 来分区?
这个问题,可以参考我之前发的另外一个帖子:
因为数据库的分片硬限制太多了,MySQL、OceanBase 都限制 分片键必须是主键 或 唯一键 的一部分。
再加上 分区数量 等其他限制,就只能想办法自己构造一个包含 商户ID、用户ID 的主键ID,然后基于 主键 ID 来进行二级分区。
再次感谢各位大佬的热心回复~!
我理解你的问题其实是:如何让计划能够利用非分区键进行分区裁剪?
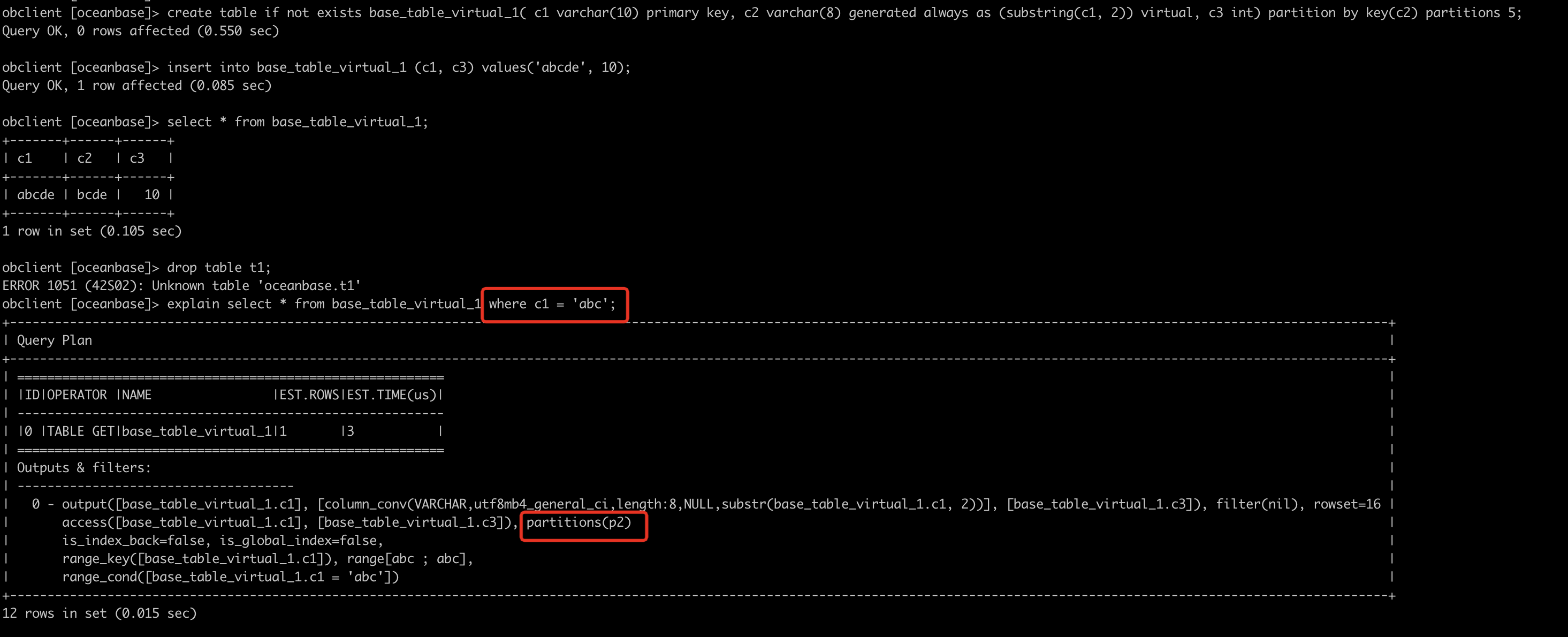
通过有 substr 子串关系的生成列,可以让计划利用非分区键进行分区裁剪,参考我上面发的这张图,通过计划里 partitions 的信息可以看出来已经对非分区键进行分区裁剪了。

1 个赞
好的,谢谢大佬,我先研究下。
如果大家有更好的建议,也欢迎提出来,谢谢! ![]()
create table t2(id int, user_id int generated always as (substr(id, 1, length(id) - 6)) virtual)
partition by hash(user_id) partitions 128;
insert into t2(id) values(1000000);
insert into t2(id) values(1000001);
insert into t2(id) values(2000000);
insert into t2(id) values(2000001);
insert into t2(id) values(23000000);
insert into t2(id) values(23999999);
select * from t2;
+----------+---------+
| id | user_id |
+----------+---------+
| 1000000 | 1 |
| 1000001 | 1 |
| 2000000 | 2 |
| 2000001 | 2 |
| 23000000 | 23 |
| 23999999 | 23 |
+----------+---------+
6 rows in set (0.016 sec)
explain select * from t2 where id = 23000000;
+----------------------------------------------------------------------------------------------------------------------------------------------------------+
| Query Plan |
+----------------------------------------------------------------------------------------------------------------------------------------------------------+
| =============================================== |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------- |
| |0 |TABLE FULL SCAN|t2 |1 |4 | |
| =============================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t2.id], [column_conv(INT,PS:(11,0),NULL,cast(substr(cast(t2.id, VARCHAR(1048576)), 1, length(cast(t2.id, VARCHAR(1048576))) - 6), INT(-1, |
| 0)))]), filter([t2.id = 23000000]), rowset=16 |
| access([t2.id]), partitions(p23) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t2.__pk_increment]), range(MIN ; MAX)always true |
+----------------------------------------------------------------------------------------------------------------------------------------------------------+
12 rows in set (0.008 sec)
explain select * from t2 where user_id = 23;
+----------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Query Plan |
+----------------------------------------------------------------------------------------------------------------------------------------------------------------+
| =============================================== |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------- |
| |0 |TABLE FULL SCAN|t2 |1 |4 | |
| =============================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t2.id], [column_conv(INT,PS:(11,0),NULL,cast(substr(cast(t2.id, VARCHAR(1048576)), 1, length(cast(t2.id, VARCHAR(1048576))) - 6), INT(-1, |
| 0)))]), filter([column_conv(INT,PS:(11,0),NULL,cast(substr(cast(t2.id, VARCHAR(1048576)), 1, length(cast(t2.id, VARCHAR(1048576))) - 6), INT(-1, 0))) = |
| 23]), rowset=16 |
| access([t2.id]), partitions(p23) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t2.__pk_increment]), range(MIN ; MAX)always true |
+----------------------------------------------------------------------------------------------------------------------------------------------------------------+
13 rows in set (0.008 sec)
1 个赞
大佬,我想冒昧地再问一下,我还有一个冷热分离的需求。
我们的记录数据有明显的冷热分离的特点,记录数据只需要保留最近3个月的,最近7天的数据属于热数据,每天的数据又较多( 预期增长到约 20亿 )。
所以,我们也考虑过按天分区,后续也方便按天删除过期数据。
然而,我们已经考虑优先按照 商户ID、用户ID 进行二级分区了,如果再按天的话,似乎没有3级分区的说法。
我们现在更倾向于,自己手动按天归档历史数据。
不知道大佬有没有更好的建议,来避免手动分表的麻烦 ?
平时的sql里面,只会有商户ID、用户ID其中之一的条件吗?