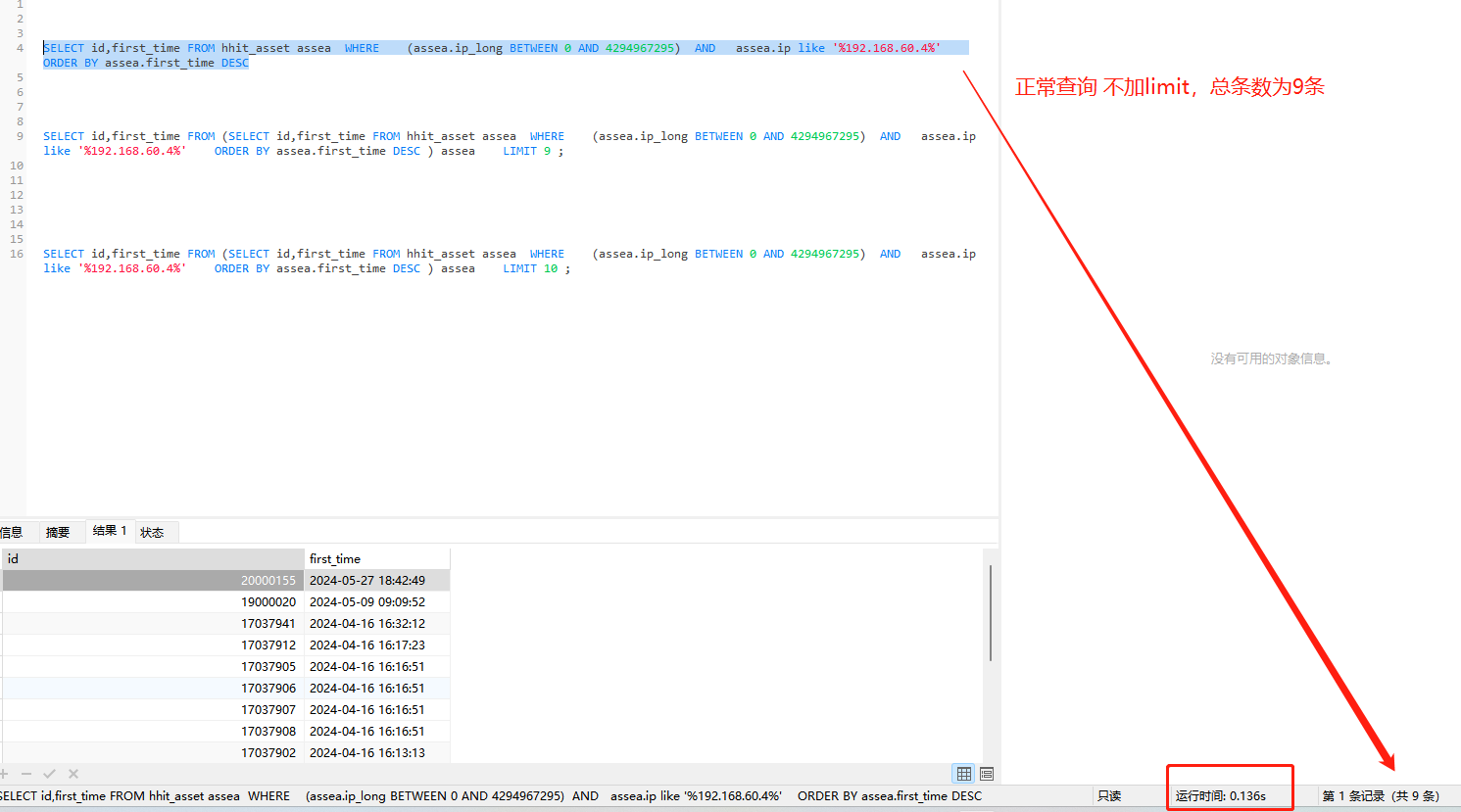
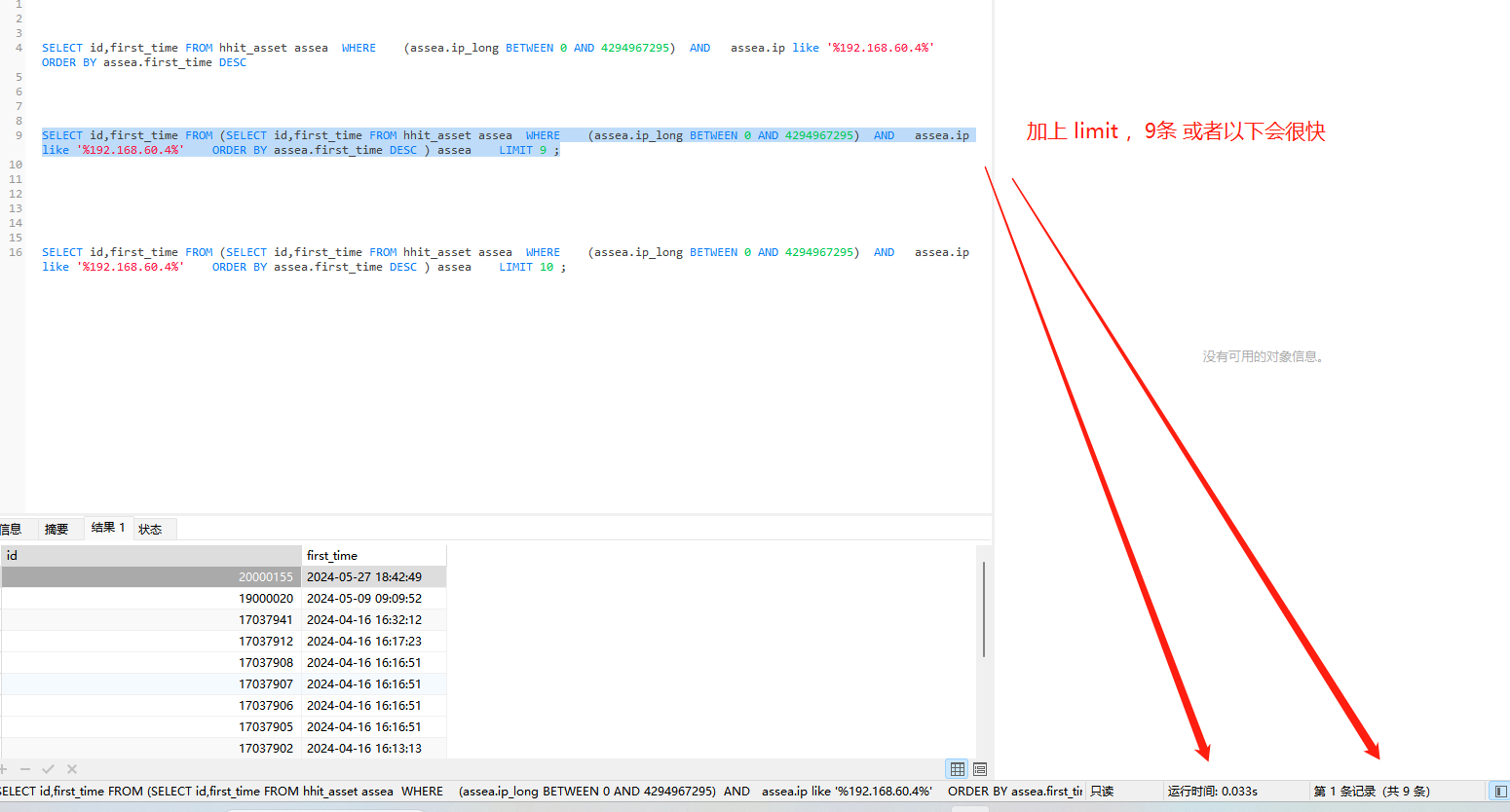
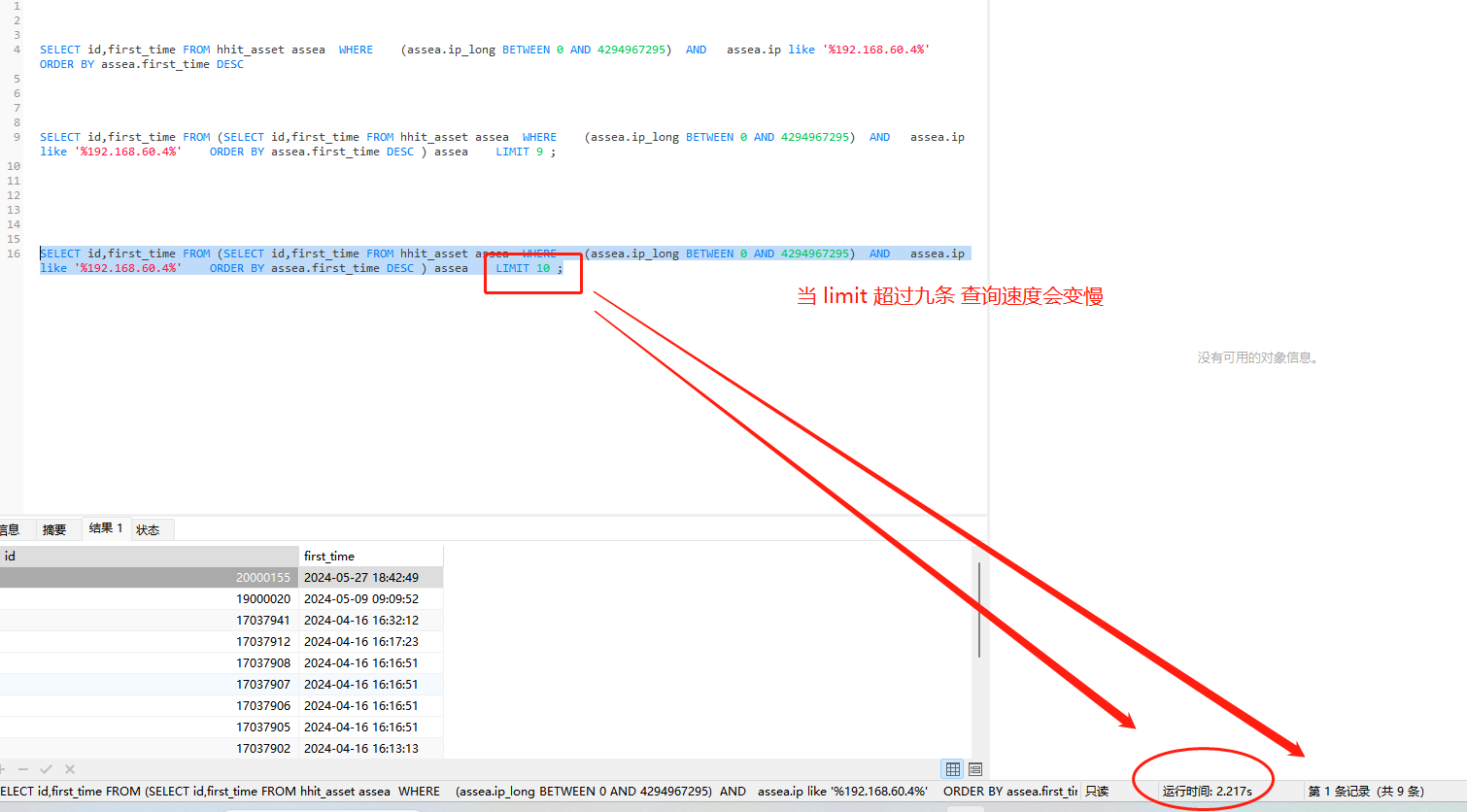
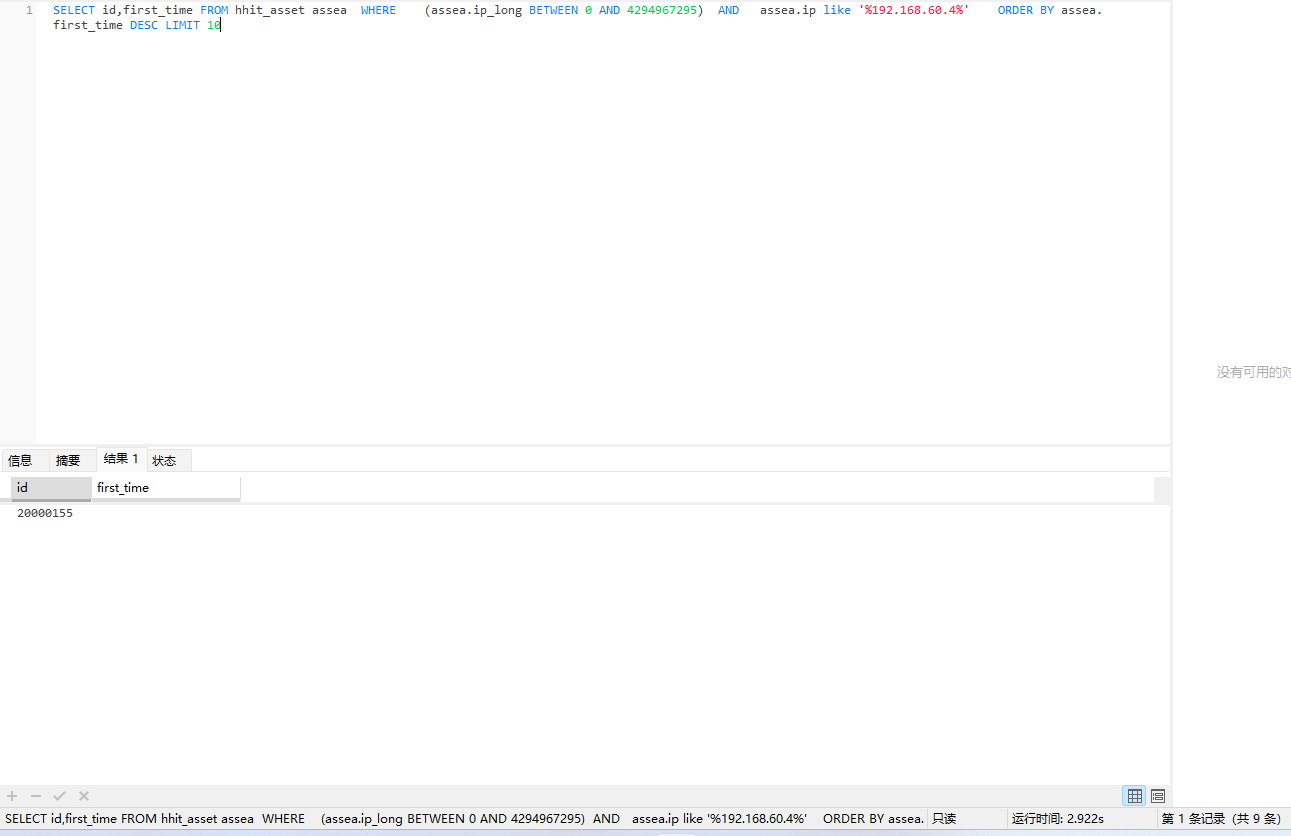
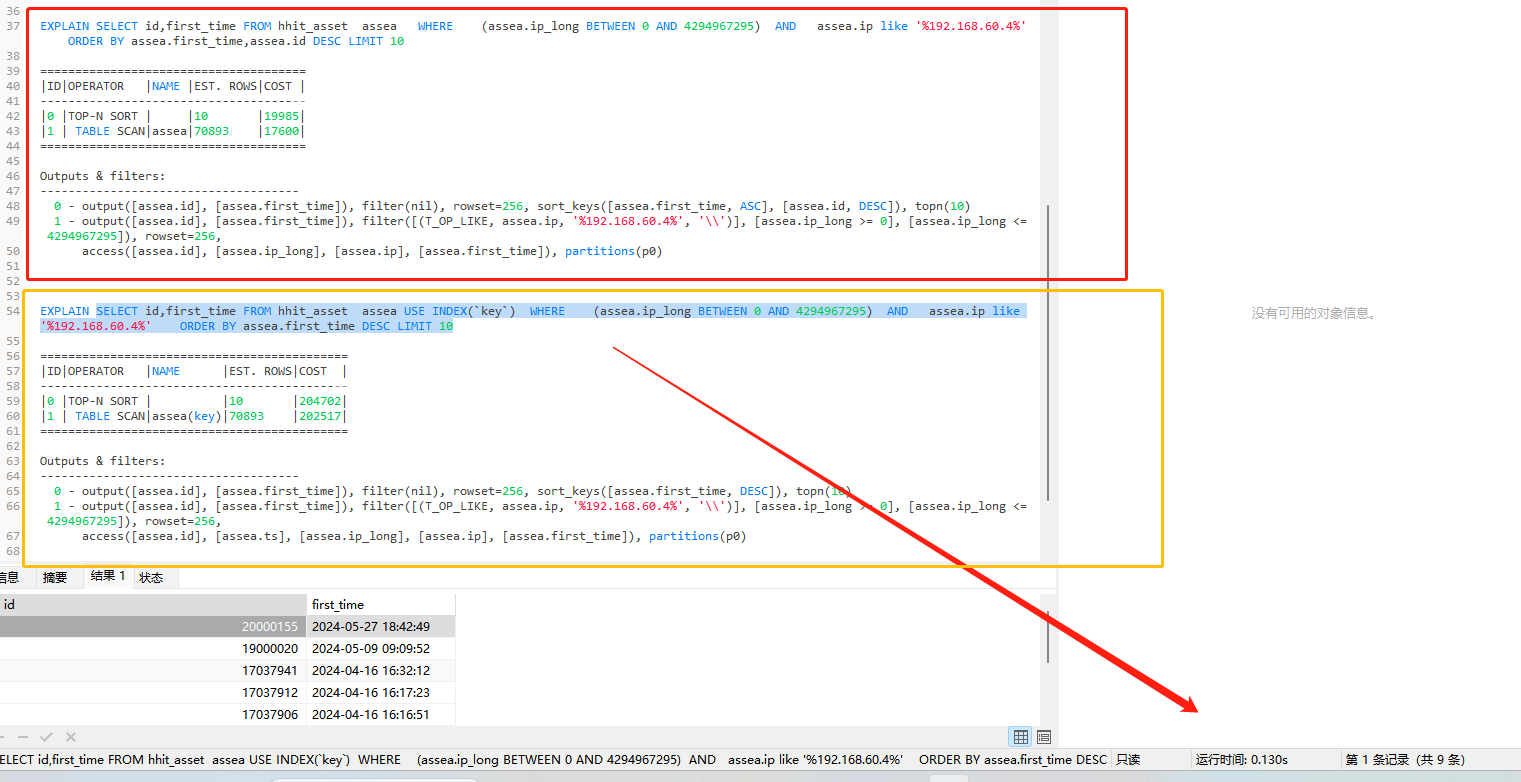
使用的sql
SELECT id,first_time FROM hhit_asset assea WHERE (assea.ip_long BETWEEN 0 AND 4294967295) AND assea.ip like ‘%ip地址%’ ORDER BY assea.first_time DESC
SELECT id,first_time FROM (SELECT id,first_time FROM hhit_asset assea WHERE (assea.ip_long BETWEEN 0 AND 4294967295) AND assea.ip like ‘%ip地址%’ ORDER BY assea.first_time DESC ) assea LIMIT 9 ;
SELECT id,first_time FROM (SELECT id,first_time FROM hhit_asset assea WHERE (assea.ip_long BETWEEN 0 AND 4294967295) AND assea.ip like ‘%ip地址%’ ORDER BY assea.first_time DESC ) assea LIMIT 10 ;
有什么好办法解决吗?
但是不走子程序速度还是有区别
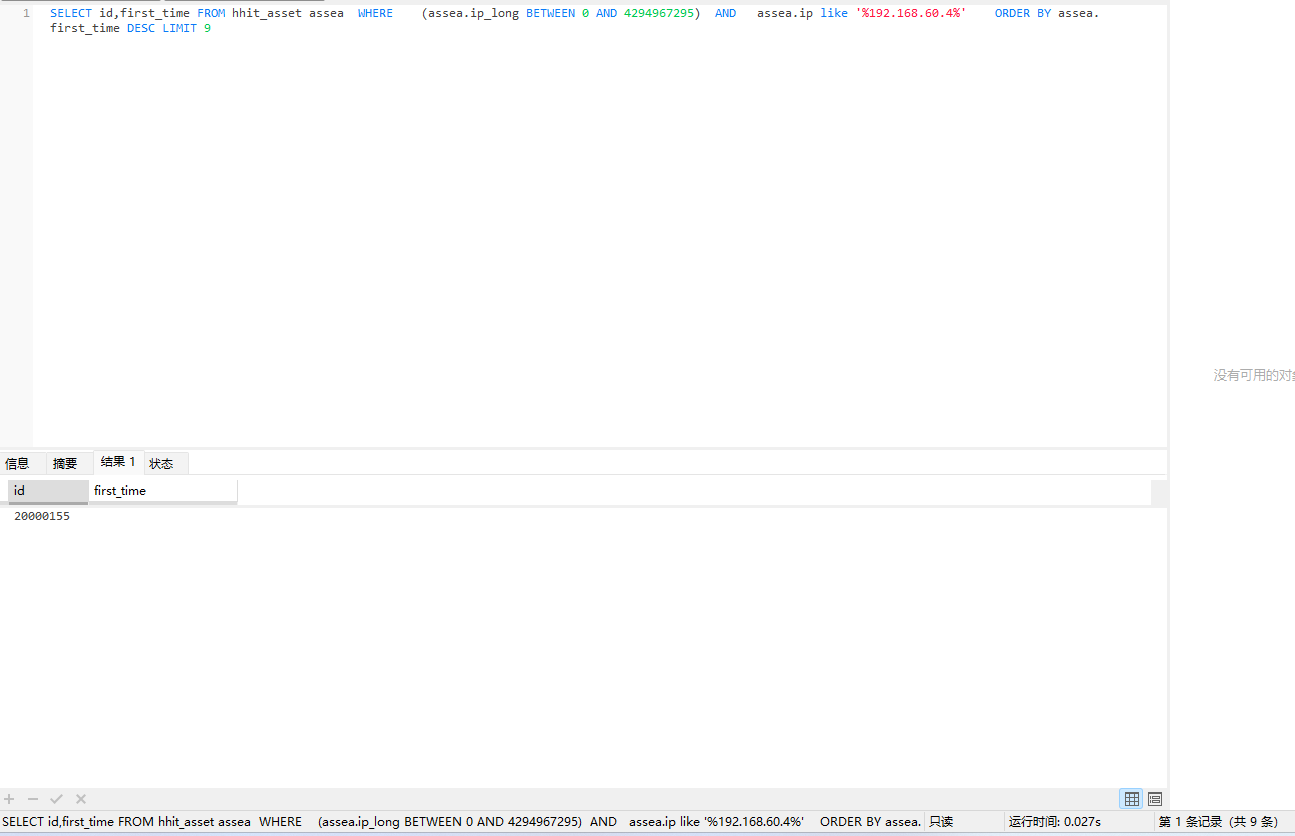
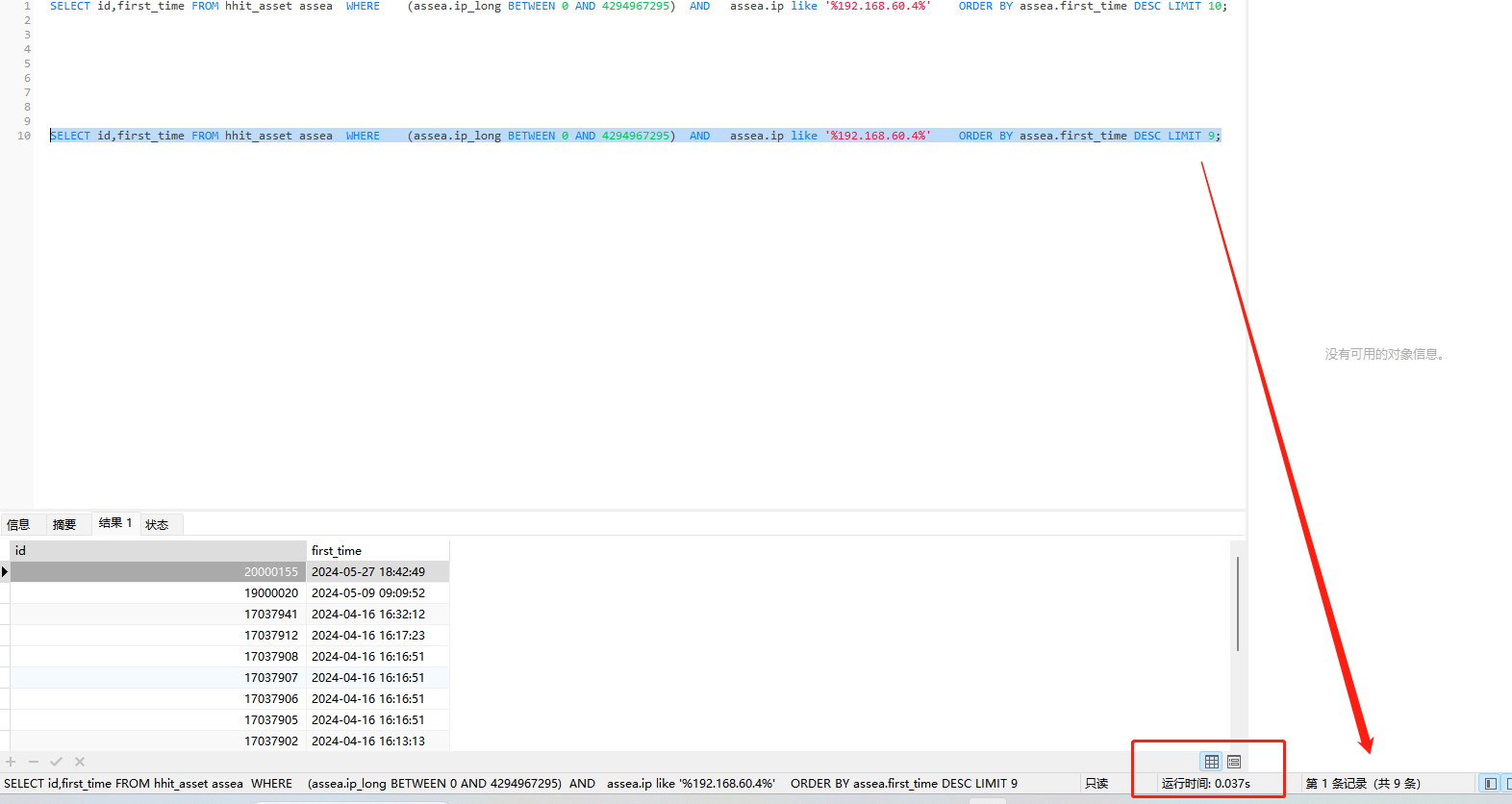
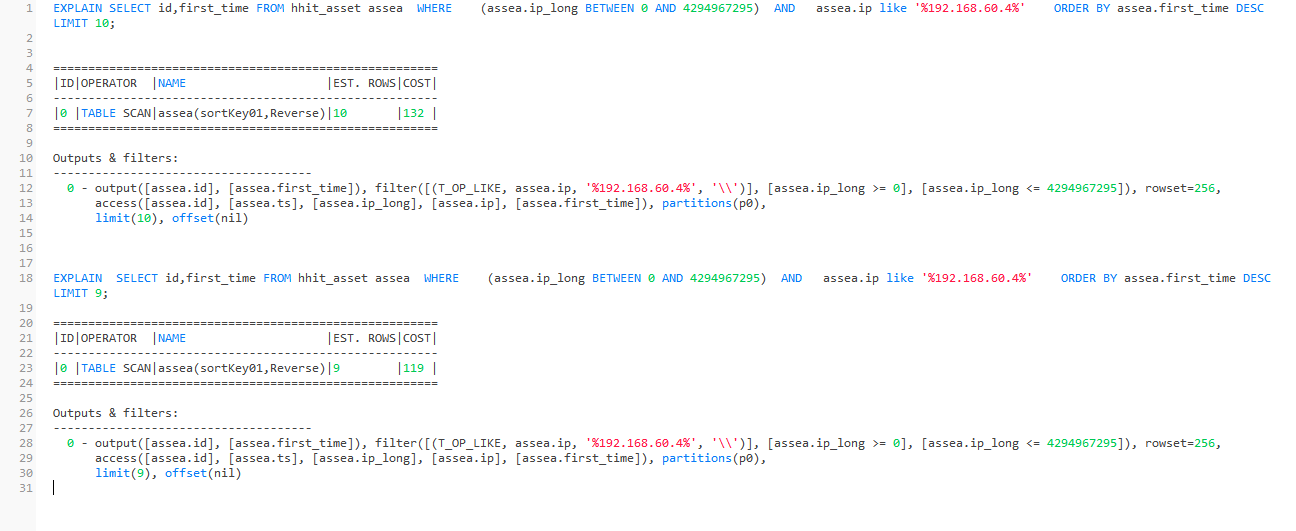
SELECT id,first_time FROM hhit_asset assea WHERE (assea.ip_long BETWEEN 0 AND 4294967295) AND assea.ip like ‘%192.168.60.4%’ ORDER BY assea.first_time DESC LIMIT 9;
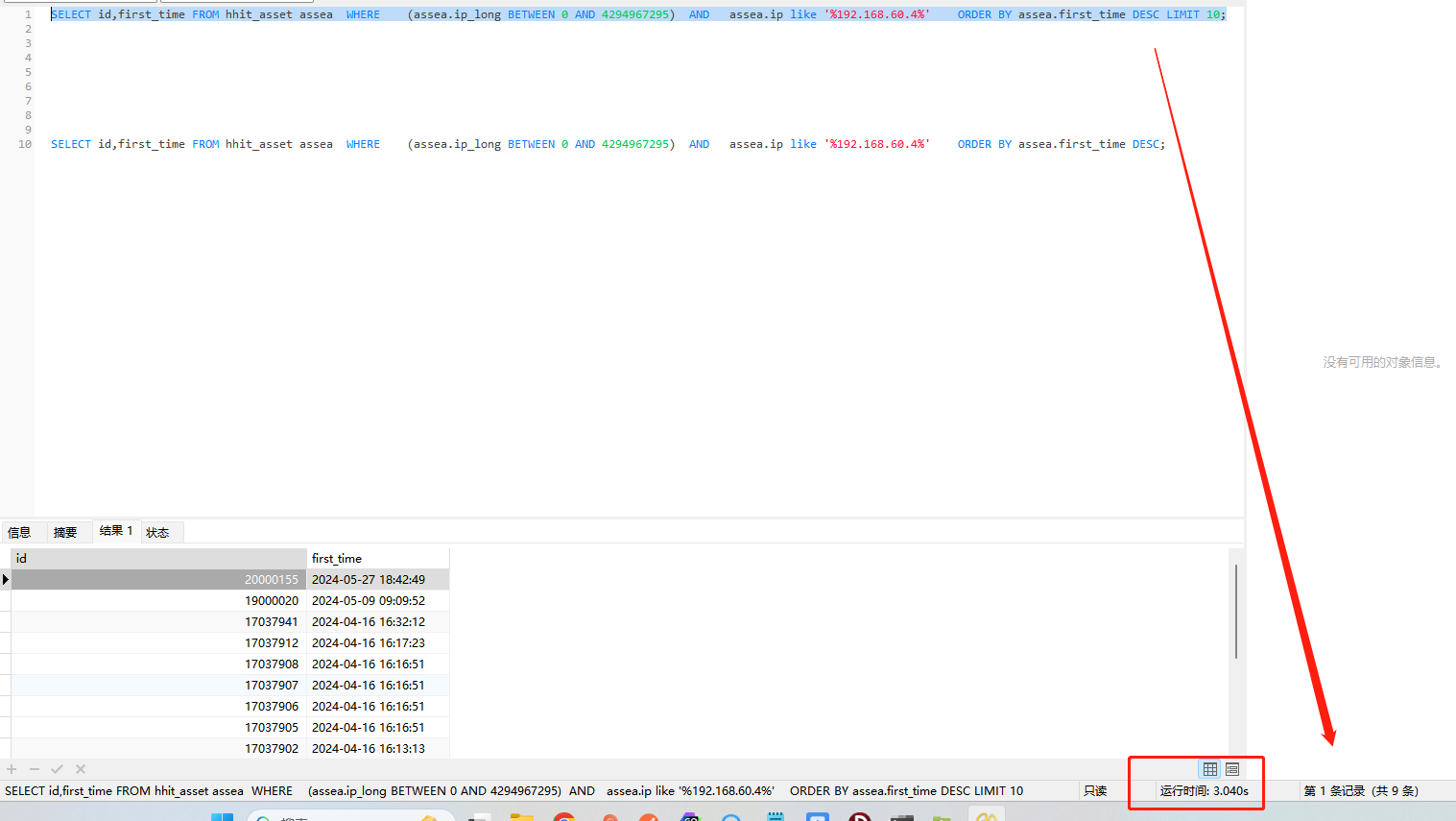
SELECT id,first_time FROM hhit_asset assea WHERE (assea.ip_long BETWEEN 0 AND 4294967295) AND assea.ip like ‘%192.168.60.4%’ ORDER BY assea.first_time DESC LIMIT 10;
有没有办法优化一下
SELECT id,first_time FROM hhit_asset assea WHERE (assea.ip_long BETWEEN 0 AND 4294967295) AND assea.ip like ‘%192.168.60.4%’ ORDER BY assea.first_time DESC LIMIT 9;
SELECT id,first_time FROM hhit_asset assea WHERE (assea.ip_long BETWEEN 0 AND 4294967295) AND assea.ip like ‘%192.168.60.4%’ ORDER BY assea.first_time DESC LIMIT 10;
这两条了?这里没有走子查询原因也是一样的嘛