

【 使用环境 】测试环境
【 OB or 其他组件 】 OceanBase数据库4.0.0
【附件及日志】
obdiag analyze log分析结果
result_details.txt (413.2 KB)
election.7z (6.9 MB)
rootservice.7z (7.7 MB)
因为cpu占用高使用了obdiag gather scene run --scene=observer.cpu_high分析了一下
cpu.7z (578.2 KB)
麻烦排查一下
如果是sql原因是否可以排查出来是那些sql
是单节点部署的吗?机器和租户分别是什么配置啊,我看版本是4.0.0的,建议用4.2.x的版本测试
1、可以看下机器在慢的时间段里的负载情况
2、如果有ocp的话,看下‘租户sql诊断’
抱歉,没有部署ocp,在慢的时间里面使用top 查看ob数据库cpu占用300,内存占用10多个g的样子
还有大佬回复这个问题嘛
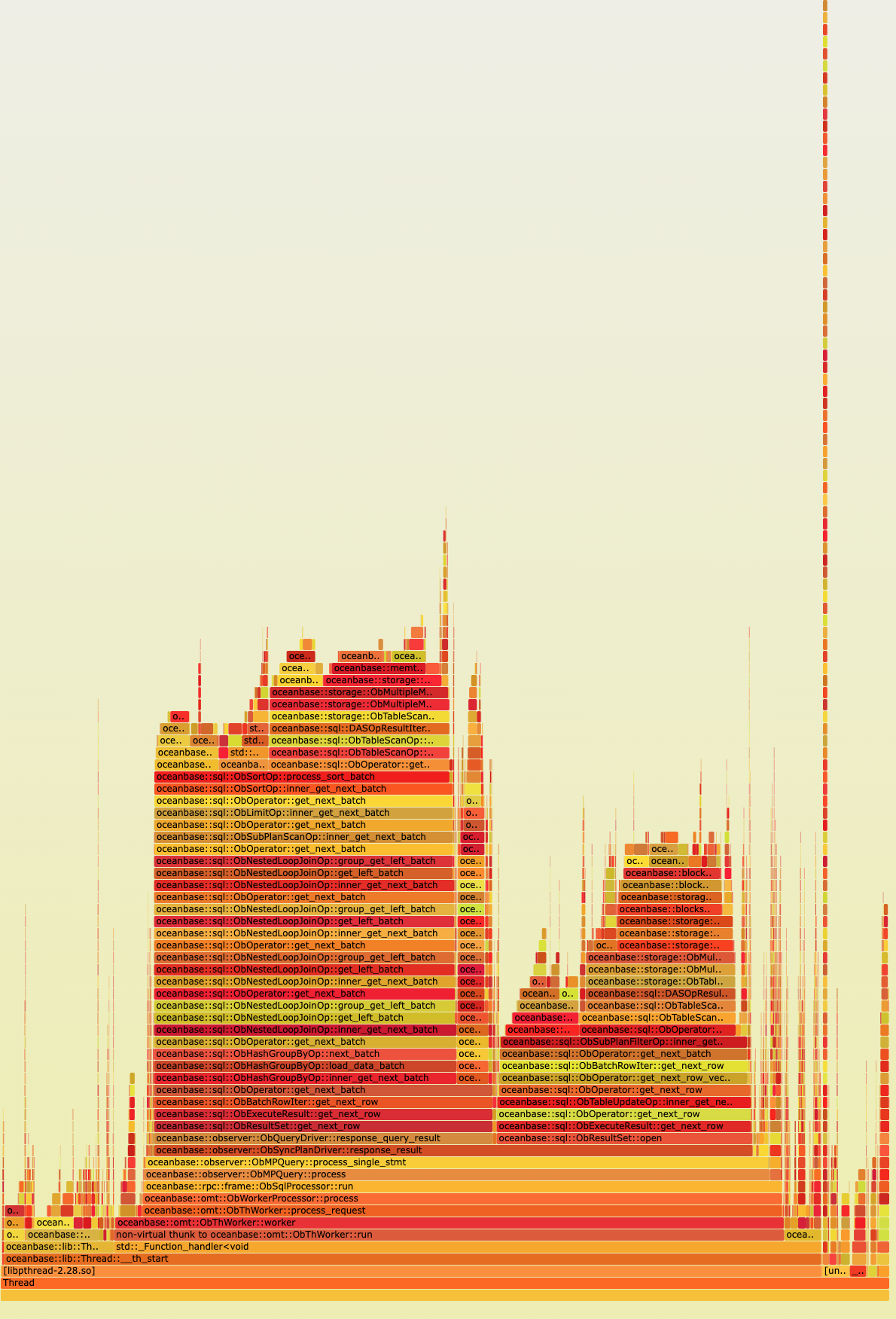
这块分析传过来的日志,看到是有很多表关联的查询,具体sql可以在cpu高的时候,通过GV$OB_PROCESSLIST,或者GV$OB_SQL_AUDIT查看有哪些复杂的sql在执行;
另外这里最好建议用ocp做下监控,可以很直观的通过topsql看到那些sql在跑
4.0.0 版本太老了, 推荐使用4.2.1-bp6 最新的稳定版本, 做一下升级吧
是的
这个环境天天都有在运行的,慢查询的sql应该是一直都有在跑的,为什么会过这么久才会发生一次性能变差。
性能突然变差原因比较多,SQL资源消耗增大是一个常见因素,比如SQL执行计划突变,数据量变化等,建议部署OCP监控下topsql资源消耗情况
可以观察下慢的时间一般多久什么规律,是不是有其他定时任务这时候在跑。