

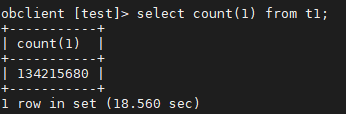
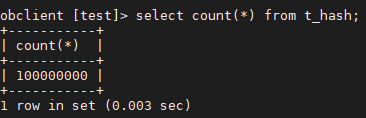
select count(*) from table 分布式只需要0.1s 而单机则需要18s这是为啥?是有参数控制?还是实现不一样啊?
这是为啥?
- 并行处理方式:分布式能够将任务分解并在多个节点上并行执行,可以提高处理速度。而单机受限于单节点的处理能力,应该无法实现这种并行处理。
- 数据分布:分布式得数据分布再不同分区存储在不同的节点上,可以减少数据得访问。单机可能需要从单一存储上读取数据,主要在于磁盘I/O性能上。
问题一、分布式并行能力是默认开启的,不需要有啥参数控制是吧,比如parallel_query_dop之类的?
问题二、分布式中分区表和非分区表是不是全表扫描的耗时会差很多?
不开启并行的情况下,在表结构相同,数据量1亿的情况下,做全表扫描,查询效率:分区表带索引>分区表不带索引>普通表带索引>普通表不带索引 对吧?
发现第一次select count() 耗时18s 隔了一会儿没管,又去执行了下select count() 就变成0.002s了 这是为啥?
缓存,一般不都是这样吗?
前面的回答都不对
区别应该是两个数据一个做了合并, 一个还没合并完
合并后的数据能够走到快速的聚合下压路径
我觉得应该是这个原因,但我的是单机部署,也不是分区表,开启了自适应合并,然后ob也会去做普通表的合并吗?合并的时间一般是啥时候,或者需要多久啊?这个能看吗?

知道了 show parameters like ‘major_freeze_duty_time’; select * from oceanbase.DBA_OB_ZONE_MAJOR_COMPACTION;