

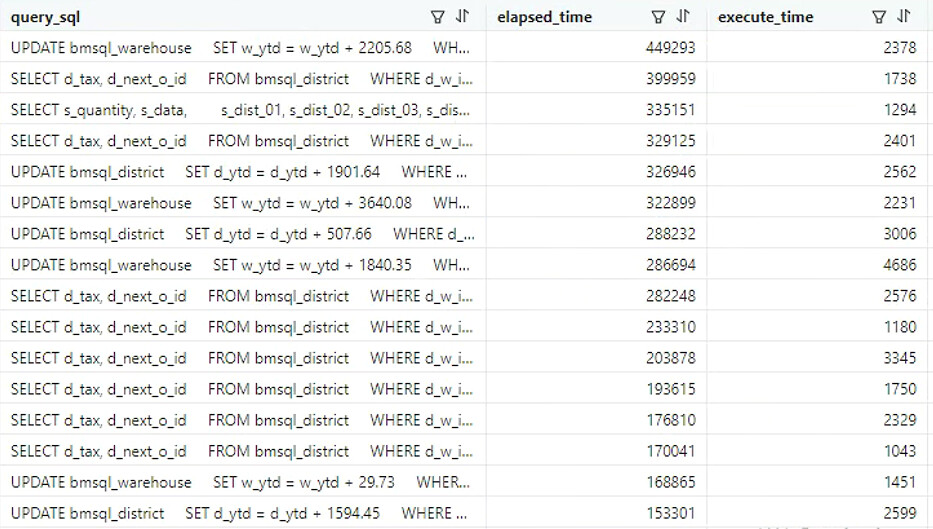
如图是benchmark压测的语句。可以看到,每条SQL的execute_time都非常小, 但最终的elapsed_time都高出好几个数量级。
问题,如何分析一条SQL语句的时间都花费在了哪些模块上?
如图是benchmark压测的语句。可以看到,每条SQL的execute_time都非常小, 但最终的elapsed_time都高出好几个数量级。
问题,如何分析一条SQL语句的时间都花费在了哪些模块上?
还是这个视图,查询其他列
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000000752086#2-title-GV$OB_SQL_AUDIT%20字段说明
把RETRY_CNT重试次数打出来看看
把你查询sql_audit的语句也贴一下吧,图片中的sql隐藏了后半部分
发现一个问题: 这种elapsed_time 比 execute_time 高出非常多的SQL, 基本上都是 DML语句。
如果你所提示的,看retry_cnt指标,这些SQL的retry_cnt基本上都是3次。 这应该是锁等待。
查了gv$ob_locks, 的确有一些锁等待,但这些锁等待都是变化的,也即没有长时间的锁等待, 这种应该属于正常情况。
那么, 针对这种情况, 如何能进一步优化?
retry_cnt这种多次的话确实很大概率是锁等待,可以用obdiag来分析一下是否存在锁冲突。
https://www.oceanbase.com/docs/common-obdiag-cn-1000000000791120
obdiag rca list 可以看到根因分析的场景
obdiag rca run --scene=lock_conflict 可以直接分析集群中是否存在锁冲突
另外:如果真的有锁的话得看看dml语句这块是不是不够合理,为啥会产生锁,是不是需要改改语句
你好,我是obdiag的开发同学,这边已经看到了上传的结果,
好,谢谢! 等obdiag更新后,我再继续收集这个问题的日志。



