【测试环境】
【 OB
【 4.2.2】
【问题描述】
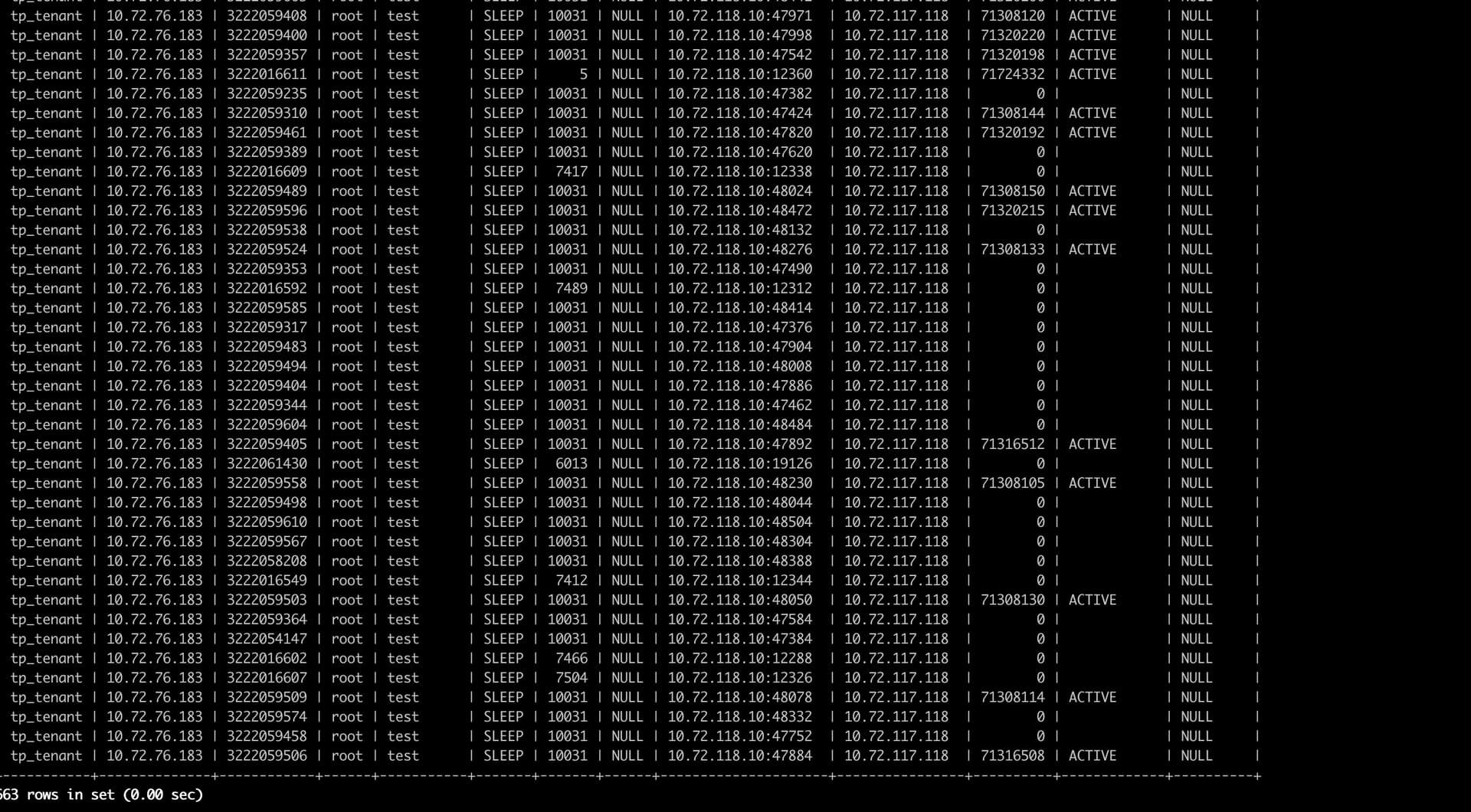
通过sysbench压测的时候触发长事务锁死整个数据库的现象,但是又无法kill掉这个事务,
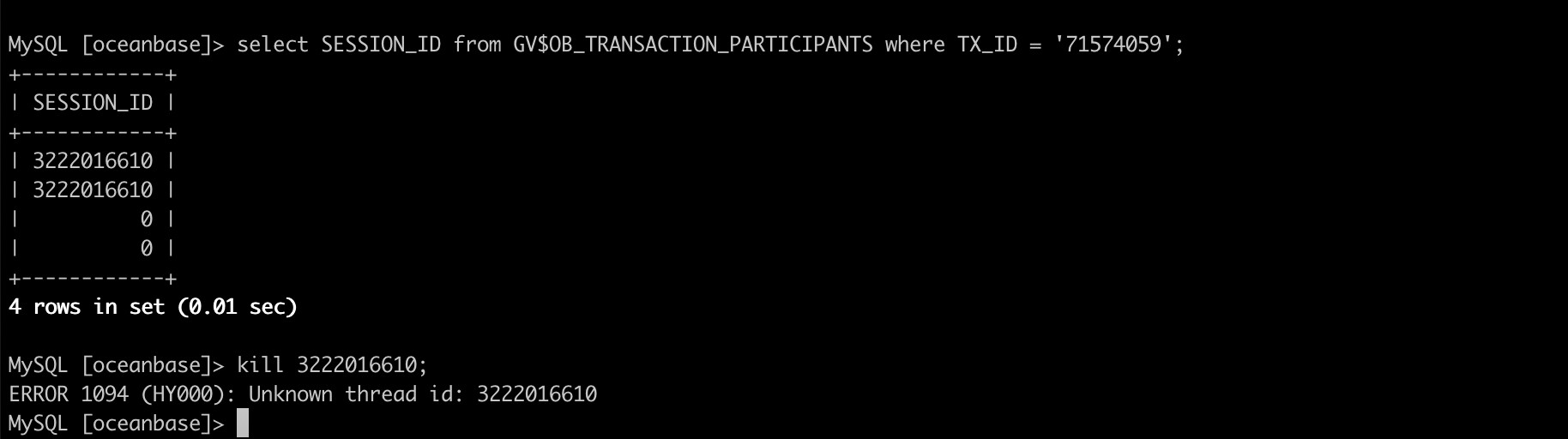
SELECT tenant, svr_ip, id, USER,db, state ,time, info, host, user_client_ip, trans_id,trans_state, trace_id
FROM oceanbase.__all_virtual_processlist
WHERE tenant='oboracle' AND USER='TPCC';
kill 322016610;
这样应该可以杀成功。
试试看。
这样确实可以,那么触发的原因是什么呢,这个可以看下吗 我觉得这个问题会很致命,直接就不可用了
所以这个是怀疑和sysbench有关系?
各位老师,现在想先分析下当前这个场景的触发原因
obdiag 的sysbench巡检并不是针对sysbench本身,而是针对ob的巡检,想让巡检一下也是想通过巡检结果看是否能缩小点排查范围
好的,那有建议的obdiag版本吗
直接最新版的obdiag就行,2.0.0
这工具不太好用,半天弄不明白,还有别的排查路径么。
有哪些不好用的点呢,我简单点列一下使用方式:
第一步:安装obdiag, OceanBase分布式数据库-海量数据 笔笔算数
第二步:obdiag config -h <db_host> -u <sys_user> [-p password] [-P port] 配置下需要诊断的集群
第三步:obdiag check --cases=sysbench_free
以上三步就够了
我的集群是通过admin用户部署的,但是这个工具又只能用root部署,配置文件直接生成到根路径下了,我想改还不能改,中间类似的冲突太多了
感谢反馈,obdiag配置文件是生成在用户目录下的,比如在admin用户下去执行obdiag config xxx就行。
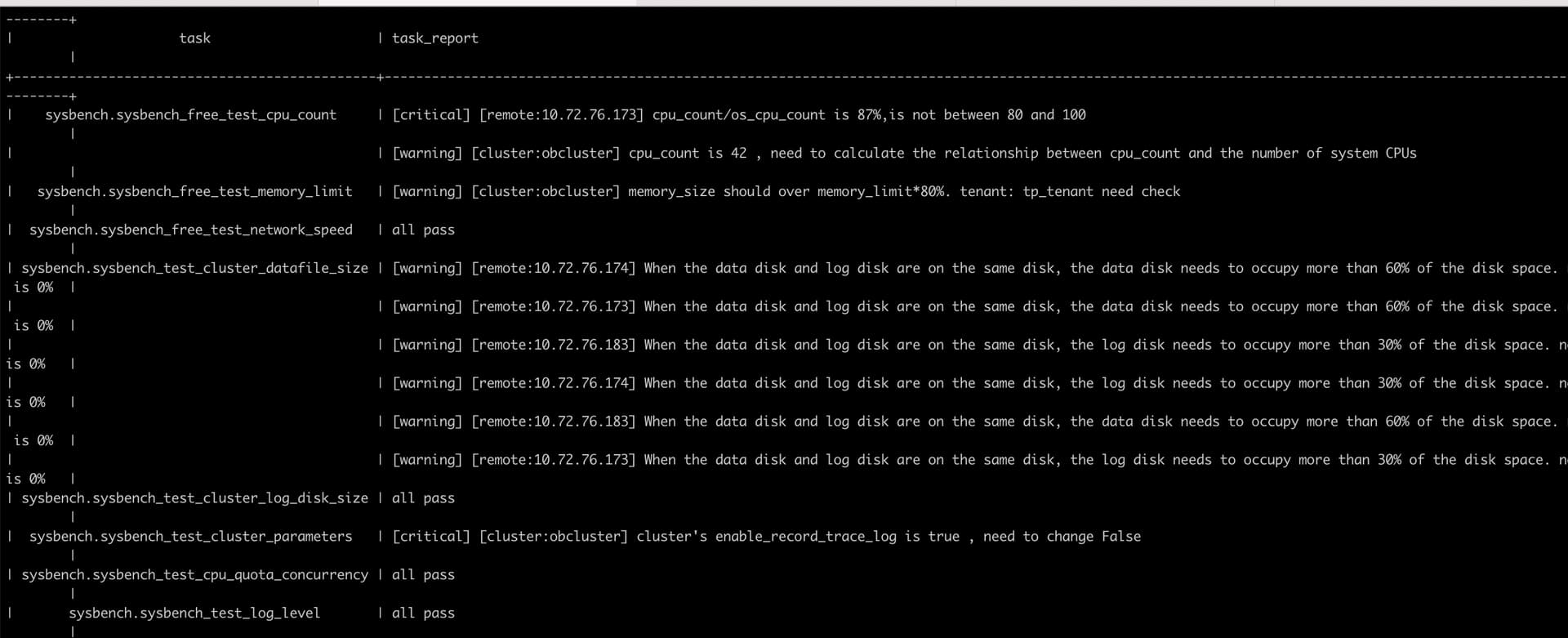
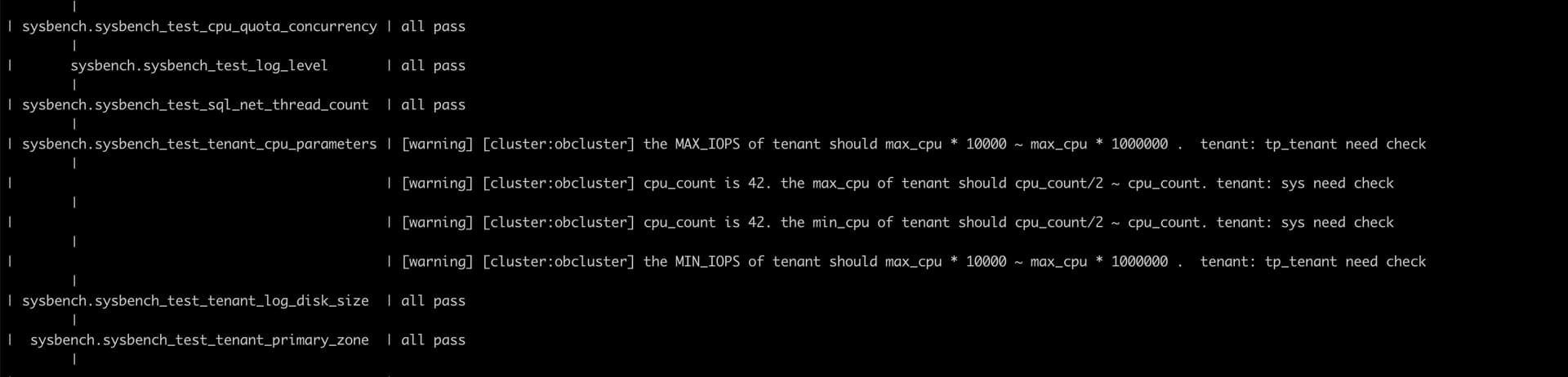
好的,我找性能小组的人看一下这份巡检报告。有结果后回复你。
嗯。不过我感觉问题不会出在这里吧,应该还得去看看为什么会有一堆事务堵着
你这个环境压测时候是必现的吗,还有个思路,压测出问题后,分析下ob的日志。
obdiag analyze log --since 20m (分析20分钟的)
或者直接分析你刚压测时间段内的日志
例如:obdiag analyze log --from “2023-10-08 10:25:00” --to “2023-10-08 11:30:00”
这个现场我还保留着。不重启集群估计会一直卡着,
那可以先分析下卡住事务那段时间的日志看看