

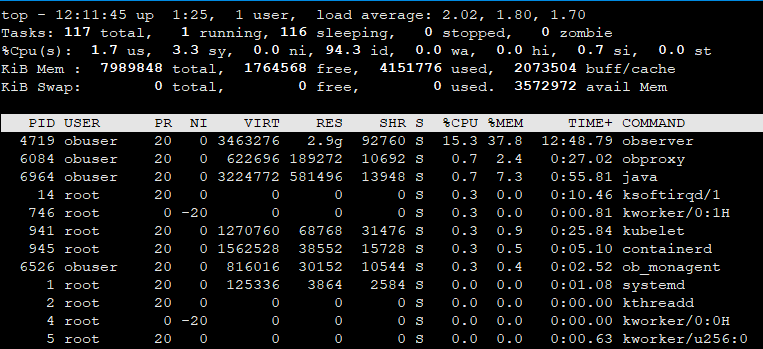
我们在另外一个环境搭建的集群,也是最小化安装,只有默认的 sys 和 ocp 租户,貌似 CPU 占用只有 15+%,看起来就是比较正常的。

我把租户 1004 删除后,CPU占用降低了 200%左右,不过还是有 400+%
![]()
这个参数 调大些。 比如5G吧。 这个参数太小了 。 。
可以看下这个说明https://ask.oceanbase.com/t/topic/20400058
调整下租户资源。
OceanBase 数据库
配置文件看一下
另外 也可以看下per top -p cpu这么高 - #5,来自 近墨者
这是系统的默认配置,没有修改过。
关键是我啥数据都还没有呢。
我在本地环境,也另外搭建了一个进群,也是这个配置,但是 CPU 占用就是正常的(单节点只有15%左右)。
感谢回复,第一个链接,我之前看过。他默认是200%左右,我这边默认是400+%,而且我只要新建一个租户,啥都不干,就会变成 600+%,而且我本地环境一样安装的集群,也都是 obd 白屏部署的 最小化占用的默认配置,CPU占用只有 15+%,就是正常的。
所以,应该还是哪里有问题所致。
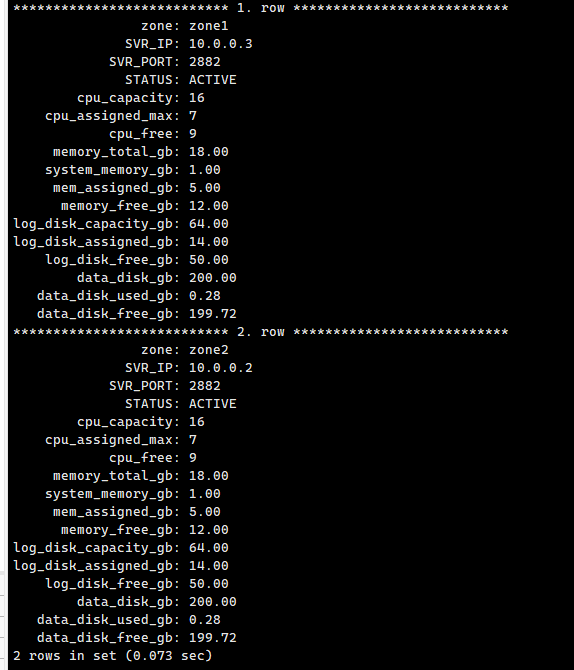
配置文件是默认的,所以直接给你看看这个(单位都是 GB )。
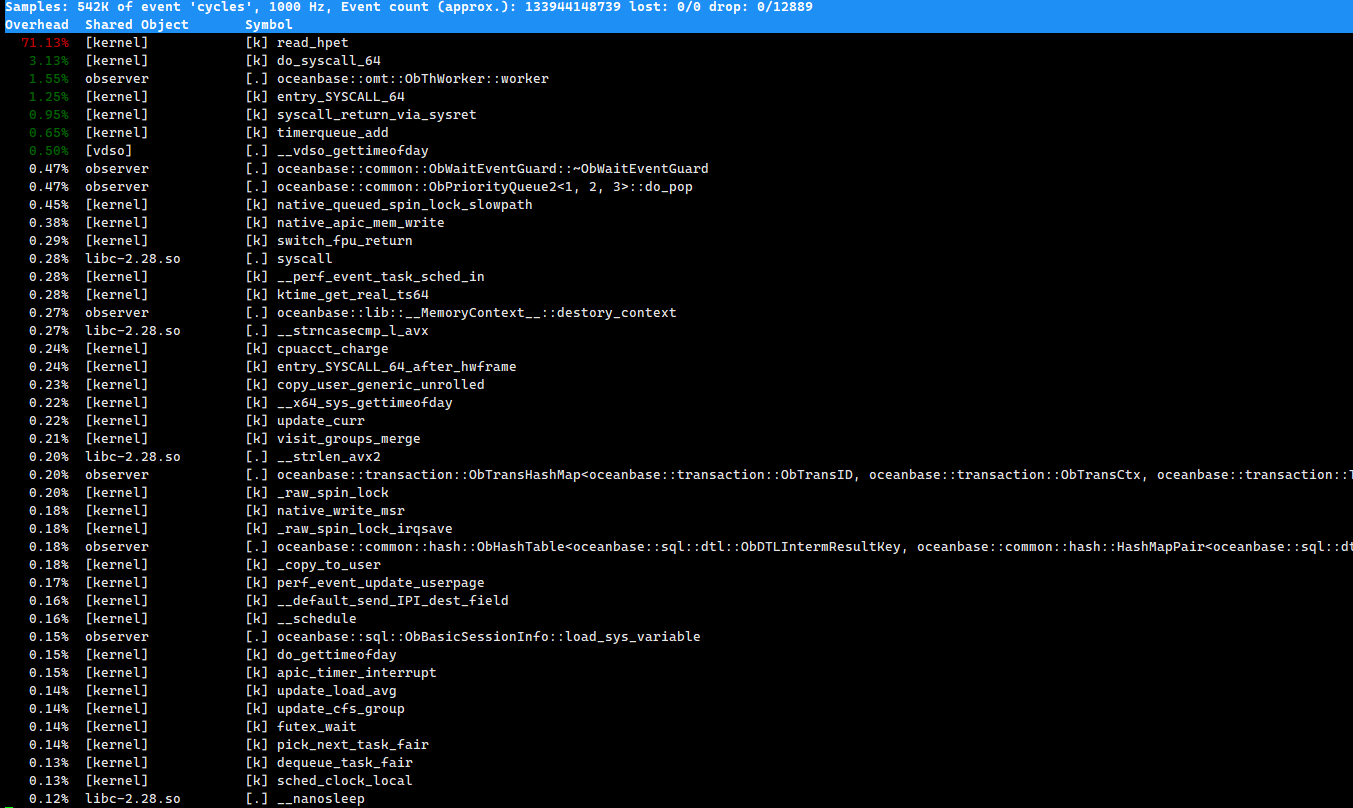
稍等。
看看机器用的时钟源是啥
cat /sys/devices/system/clocksource/clocksource0/current_clocksource
如果怀疑是时钟源的问题,修改一下默认时钟源为tsc
手动修复方式:
echo tsc > /sys/devices/system/clocksource/clocksource0/current_clocksource
执行的输出结果是 hpet。
[admin@test02 ~]$ cat /sys/devices/system/clocksource/clocksource0/current_clocksource
hpet
hpet高精度始终源确实可能引起性能问题,改成tsc,
echo tsc > /sys/devices/system/clocksource/clocksource0/current_clocksource
是的,我也发现我本地CPU占用正常的那个集群,使用的时钟源就是 tsc。出问题的就是这个 hpet 的。
不过我在出问题的机器上,查看可用时钟源,貌似不支持 tsc:
cat /sys/devices/system/clocksource/clocksource0/available_clocksource
hpet acpi_pm
这个 acpi_pm 能用吗 ?
你的环境部署是用ocp部署的还是?什么版本的也提供一下吧
obd web 白屏部署,版本是 4.2.2.0 社区版本 一键安装包 。具体下载命令如下:
wget https://obbusiness-private.oss-cn-shanghai.aliyuncs.com/download-center/opensource/oceanbase-all-in-one/8/x86_64/oceanbase-all-in-one-4.2.2.0-100010012024022719.el8.x86_64.tar.gz
问题集群的环境信息如下:
- CentOS 8.2 x86_64:
Linux test02 4.18.0-193.28.1.el8_2.x86_64 #1 SMP Thu Oct 22 00:20:22 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux - CPU:
Intel(R) Xeon(R) CPU E5-2699 v4 @ 2.20GHz - OceanBase:4.2.2.0 社区版
有问题的ob集群,机器是arm的还是x86的
x86_64 的,你看我前面给出的 CentOS 内核信息,也能看出来。
已确认,当 OBServer 服务器使用 hpet 作为时钟源类型时,获取系统时间的开销会比较大,进而可能导致内核态 CPU 使用率高。
如果暂时不想重启机器,可以执行:
echo tsc > /sys/devices/system/clocksource/clocksource0/current_clocksource
cat /sys/devices/system/clocksource/clocksource0/available_clocksource 检查下:
grep tsc /proc/cpuinfo
如果cpu支持的话,dmesg | grep -i tsc 看看有没有什么报错
我之前已经试过了:
sudo bash -c 'echo tsc > /sys/devices/system/clocksource/clocksource0/current_clocksource'
不过,我系统里目前可用的时钟源,没有 tsc。只有 hpet 和 acpi_pm。
不过 CPU 是支持 tsc 和 constant_tsc 特性的,所以目前在想办法,看能不能启用 tsc 时钟源。