感谢感谢,其实我们也很想尝试着把Oceanbase用起来,毕竟这么优秀的存储性能,但是目前测试下来问题确实有一些些。
统计信息尝试过,但并没有效果~
相关表结构及count:
ftsp_kh_qzkh_lxr总量:101514443;
CREATE TABLE ftsp_kh_qzkh_lxr (
id_ char(32) NOT NULL COMMENT ‘无业务意义主键’,
qzkh_id_ char(32) NOT NULL COMMENT ‘’,
name_ varchar(100) NOT NULL COMMENT ‘’,
gender_ tinyint(4) NOT NULL DEFAULT ‘0’ COMMENT ‘’,
wechat_id_ varchar(50) DEFAULT NULL COMMENT ‘’,
email_ varchar(50) DEFAULT NULL COMMENT ‘’,
other_contact_ varchar(100) DEFAULT NULL COMMENT ‘’,
position_ char(6) DEFAULT NULL COMMENT ‘’,
wechat_status_ char(6) DEFAULT NULL COMMENT ‘’,
is_default_ tinyint(4) NOT NULL DEFAULT ‘0’ COMMENT ‘’,
create_user_ char(32) DEFAULT NULL COMMENT ‘’,
create_date_ timestamp(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT ‘’,
update_user_ char(32) DEFAULT NULL COMMENT ‘’,
update_date_ timestamp(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT ‘’,
is_fr_ tinyint(4) DEFAULT ‘0’ COMMENT ‘’,
cy_lxr_ tinyint(4) DEFAULT NULL COMMENT ‘’,
PRIMARY KEY (id_),
KEY idx_ftsp_kh_qzkh_lxr_1 (qzkh_id_),
KEY idx_ftsp_kh_qzkh_lxr_2 (position_),
KEY idx_ftsp_kh_qzkh_lxr_3 (name_(10)),
KEY idx_ftsp_kh_qzkh_lxr_4 (wechat_status_, update_user_)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMMENT = ‘’
ftsp_kh_qzkh_lxr_phone总量:215939713;
CREATE TABLE ftsp_kh_qzkh_lxr_phone (
id_ char(32) NOT NULL COMMENT ‘无业务意义主键’,
lxr_id_ char(32) NOT NULL COMMENT ‘’,
lxr_name_ varchar(100) DEFAULT NULL COMMENT ‘’,
qzkh_id_ char(32) DEFAULT NULL COMMENT ‘’,
type_ tinyint(4) NOT NULL COMMENT ‘’,
number_ varchar(600) DEFAULT NULL COMMENT ‘’,
status_ char(6) DEFAULT NULL COMMENT ‘’,
is_default_ tinyint(4) NOT NULL DEFAULT ‘0’ COMMENT ‘’,
is_competitor_ tinyint(4) DEFAULT ‘0’ COMMENT ‘’,
same_number_count_ int(11) DEFAULT ‘0’ COMMENT ‘’,
create_user_ char(32) DEFAULT NULL COMMENT ‘’,
create_date_ timestamp(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT ‘’,
update_user_ char(32) DEFAULT NULL COMMENT ‘’,
update_date_ timestamp(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT ‘’,
PRIMARY KEY (id_),
KEY idx_ftsp_kh_qzkh_lxr_phone_1 (lxr_id_),
KEY idx_ftsp_kh_qzkh_lxr_phone_2 (status_),
KEY idx_ftsp_kh_qzkh_lxr_phone_3 (qzkh_id_, lxr_id_),
KEY idx_ftsp_kh_qzkh_lxr_phone_4 (number_(20))
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMMENT = ‘’
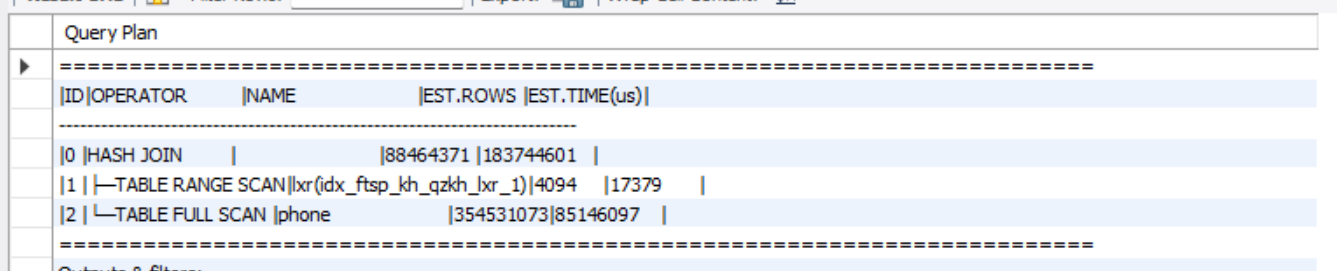
个人感觉是不是由于两个表的数据量都太大,然后走了hash join~~~ 
而且这个SQL真的就是一个很常见的两表内连接SQL,条件过滤后小表驱动大表的场景~