


ob clog disk hang,检查一下是不是clog所在文件系统出问题了或者是io过大
看下磁盘的使用情况
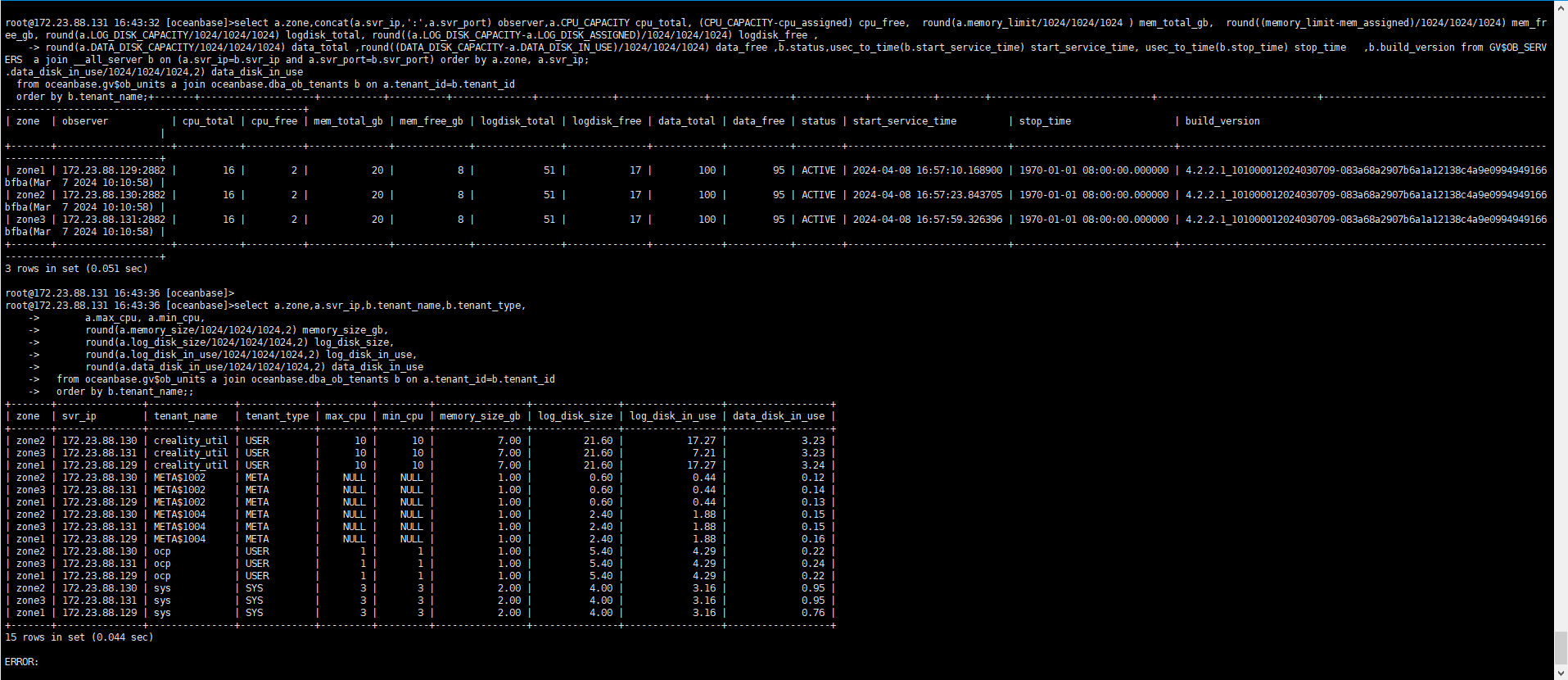
select a.zone,concat(a.svr_ip,':',a.svr_port) observer,a.CPU_CAPACITY cpu_total, (CPU_CAPACITY-cpu_assigned) cpu_free, round(a.memory_limit/1024/1024/1024 ) mem_total_gb, round((memory_limit-mem_assigned)/1024/1024/1024) mem_free_gb, round(a.LOG_DISK_CAPACITY/1024/1024/1024) logdisk_total, round((a.LOG_DISK_CAPACITY-a.LOG_DISK_ASSIGNED)/1024/1024/1024) logdisk_free ,
round(a.DATA_DISK_CAPACITY/1024/1024/1024) data_total ,round((DATA_DISK_CAPACITY-a.DATA_DISK_IN_USE)/1024/1024/1024) data_free ,b.status,usec_to_time(b.start_service_time) start_service_time, usec_to_time(b.stop_time) stop_time ,b.build_version from GV$OB_SERVERS a join __all_server b on (a.svr_ip=b.svr_ip and a.svr_port=b.svr_port) order by a.zone, a.svr_ip;
select a.zone,a.svr_ip,b.tenant_name,b.tenant_type,
a.max_cpu, a.min_cpu,
round(a.memory_size/1024/1024/1024,2) memory_size_gb,
round(a.log_disk_size/1024/1024/1024,2) log_disk_size,
round(a.log_disk_in_use/1024/1024/1024,2) log_disk_in_use,
round(a.data_disk_in_use/1024/1024/1024,2) data_disk_in_use
from oceanbase.gv$ob_units a join oceanbase.dba_ob_tenants b on a.tenant_id=b.tenant_id
order by b.tenant_name;
obdiag 巡检命令:obdiag check (对ob的全量巡检)
obdiag sysbench巡检:obdiag check --cases=sysbench_free
obdiag 工具使用文档:OceanBase分布式数据库-海量数据 笔笔算数
咱们使用的是同盘部署,压测其实是不符合要求的。hang住的场景一般是磁盘故障或者clog响应延迟导致。因此建议使用分盘部署进行测试,同时需要使用SSD磁盘测试。
上面命令查看的截图可以看出不是clog满了是吗,日志的删除机制是有效的吗
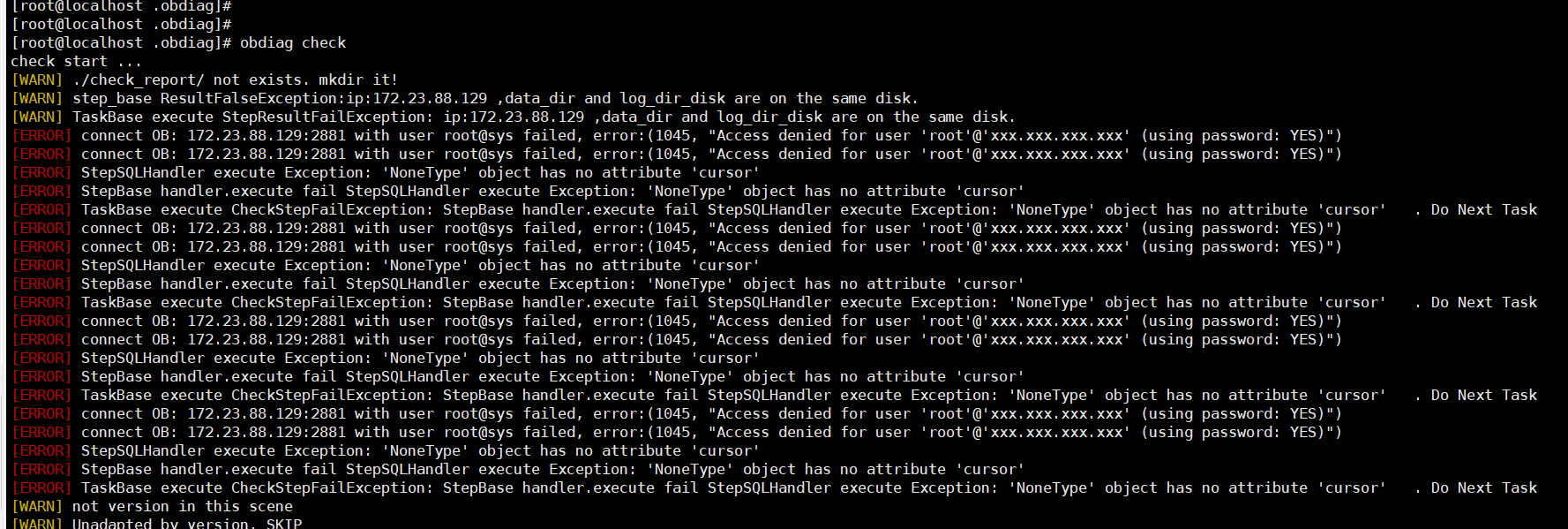
看报错是被诊断集群的配置文件你没设置吧,OceanBase分布式数据库-海量数据 笔笔算数
可以通过obdiag config -h <db_host> -u <sys_user> [-p password] [-P port] 生成一下