

oceanbase版本社区版4.2.1.4,obproxy版本使用4.2.1
某台机器出现io_write_time的毛刺现象,不定时出现写入时间过长,这个如何排查呢,

QPS、TPS、RT、memtable 内存 的对应时间段的监控图一并发一下,需要综合多个方面信息才能判断。
是要机器的还是集群的还是租户的呢
只要有都发,信息越全 越有助于判断。

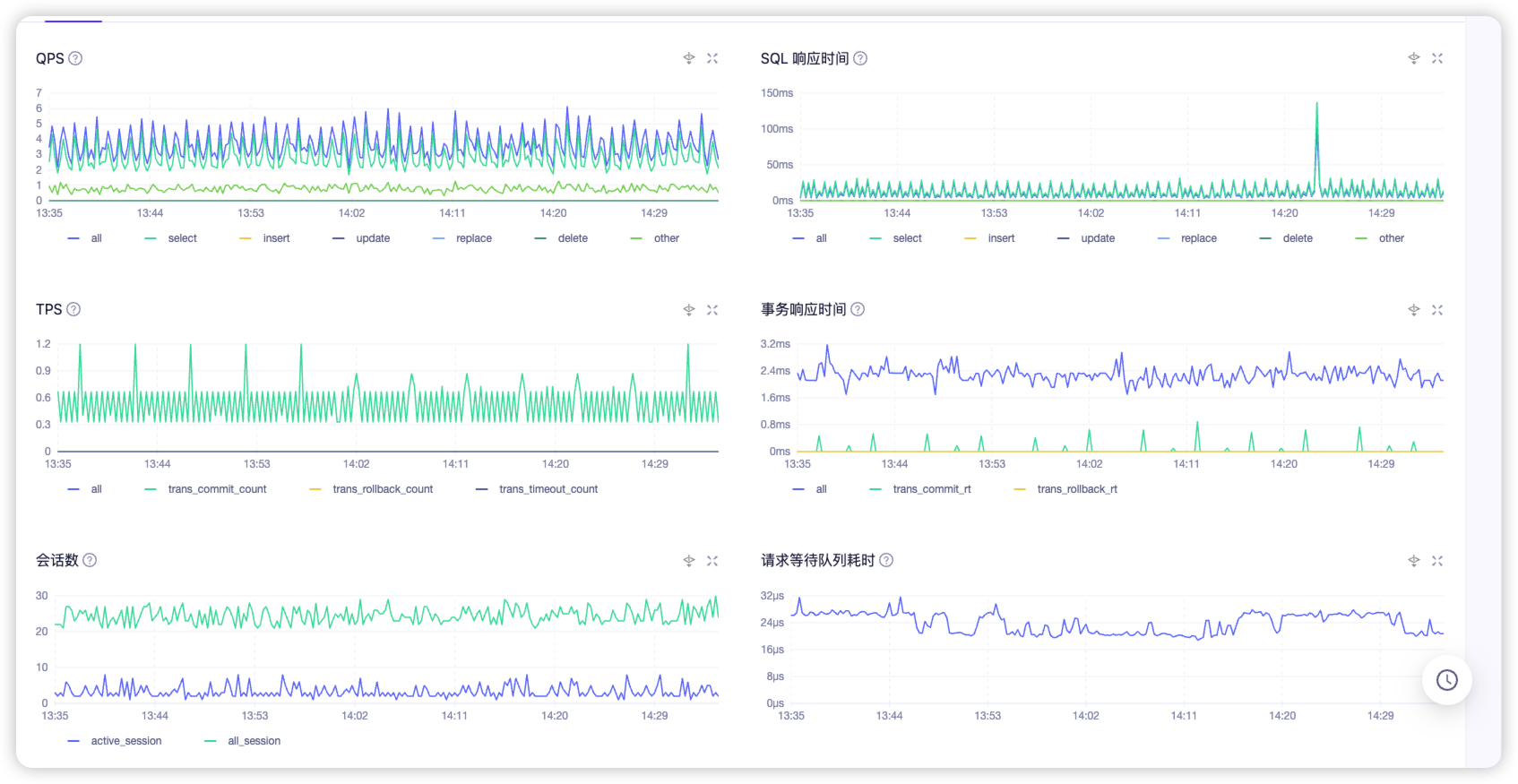

从第一个图大概就知道了。总体 IO 很少,数据库的 QPS 也很低。因为 请求次数少,自然显得抖动有点大。 这种情形下偶尔的尖刺没有什么关系,分析的意义不大。
如果你做压测,IOPS 每秒能到几百,然后 IO 延时还经常有这种尖刺,那就是问题了。

2024-04-16 10:34:59,999 [INFO] gather scene variables: {‘observer_data_dir’: ‘/disk/nvme0n1/’, ‘obproxy_data_dir’: ‘’, ‘from_time’: ‘2024-04-16 10:04:59’, ‘to_time’: ‘2024-04-16 10:35:59’}
2024-04-16 10:35:00,000 [INFO] Use gather_pack_20240416103459 as pack dir.
2024-04-16 10:35:00,001 [ERROR] Invalid Task :observer.io
2024-04-16 10:35:00,002 [INFO] execute_tasks. the number of tasks is 0 ,tasks is dict_keys([]) 没有这个task,这个收集io的有参考吗
在大多数情况下,延迟是关注存储性能时最重要的单个指标。 对于硬盘驱动器,在10到20毫秒 之间的平均等待时间被认为是可以接受的(20毫秒是上限)。 对于固态驱动器,根据工作负载,它永远不应超过1-3毫秒。 在大多数情况下,工作负载的等待时间少于1ms。
io在20ms之内的可以是为正常
但是我的是ssd盘啊,会每搁几分钟出现毛刺,毛刺事件在10ms以内,但是又没有查到毛刺时间的写的语句,只有读的语句,这个怎么定位问题呢,主要是怕出现慢盘现象
用的是什么版本的obdiag ,另外安装的时候是不是少执行了一步:source /usr/local/oceanbase-diagnostic-tool/init.sh
直接obd deploy部署的,1.7.0版本
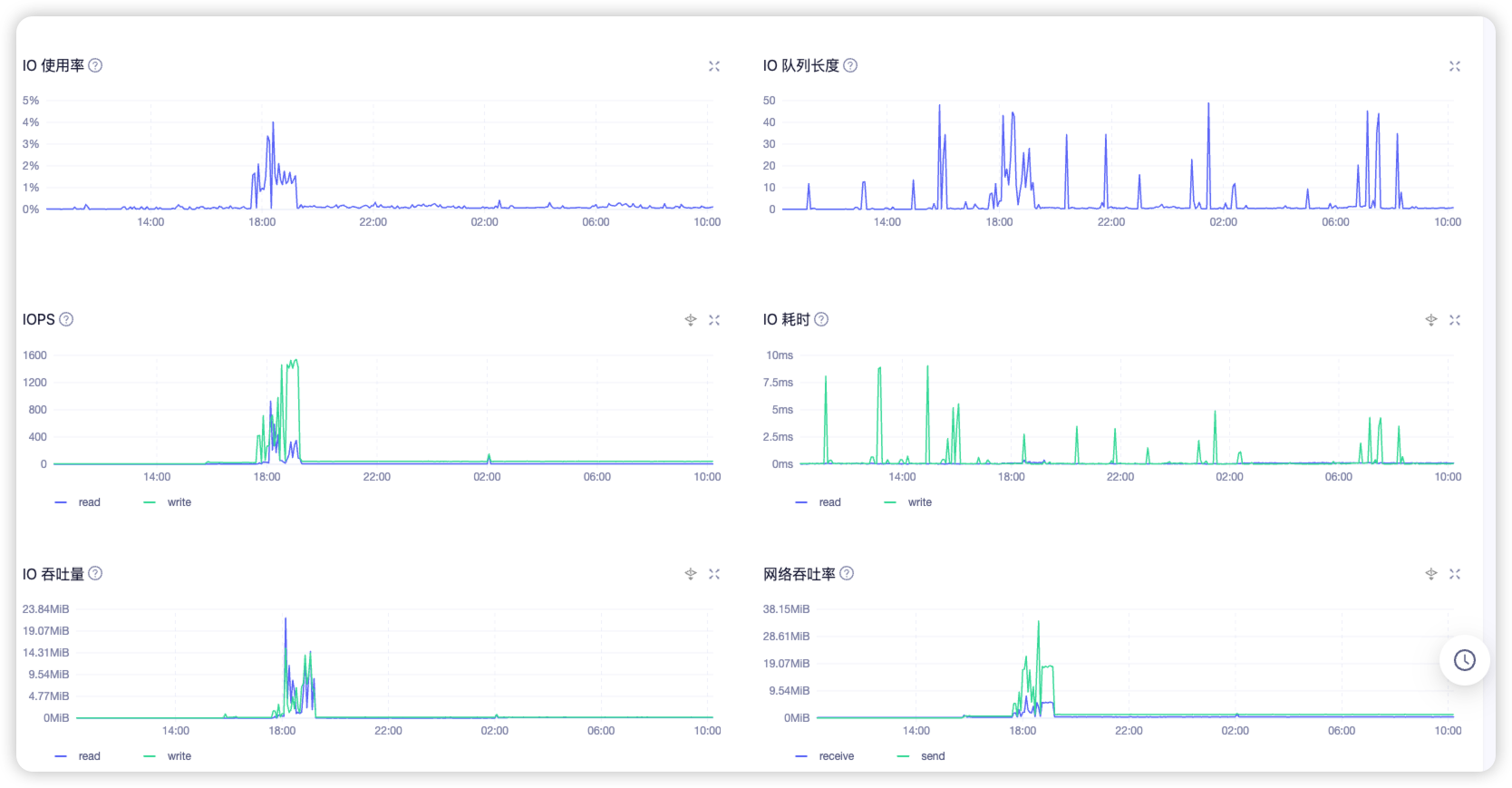
可以和正常的服务器的各项IO指标进行对比,如果除了延迟之外,其他io指标如iops,io队列深度指标都差不多,可以考虑是这台服务器的问题,再进行进一步的分析。


看看两台机器的iops指标对比

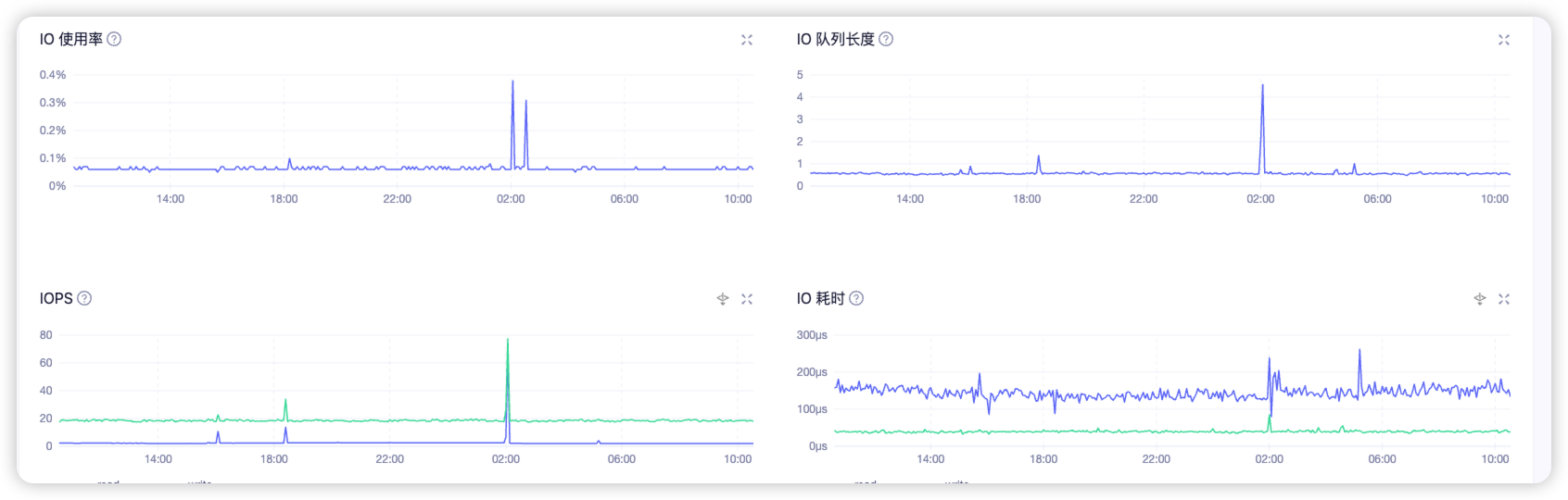
你这集群没啥负载吧
至于你说的单个机器的毛刺,那是因为只有那个机器上在特定的时间点写了点数据吧,量还不大
现在负载不大,我是3副本的,写的话不是只有那一台机器有毛刺,别的应该也有吧,而且我也没查到写的这么慢的语句
从图上可以看出来,写延迟和队列深度有关系,这两台服务器的写iops差距比队列深度的差距要大,可能和操作系统有关