【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】V4.2.2
【 使用版本 】
【问题描述】清晰明确描述问题
【复现路径】问题出现前后相关操作
4月9号晚上之前,该服务器(VM的)内存有512G,ocp平台中主机列表识别,也是这么多,集群资源管理显示是450G,因为给系统留了60+。
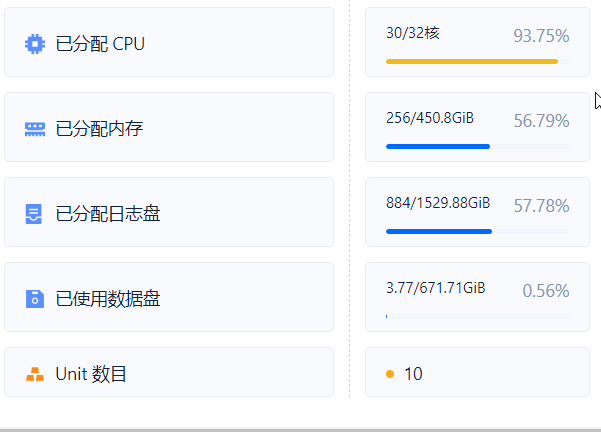
4月9号晚上对该服务器,进行拆内存,减少了150G,ocp平台中主机列表识别为350G,但是集群资源管理显示还是450G,这就有问题了。
为什么资源管理那没有识别呢?如图:
主机列表显示:
集群概览显示:
资源管理显示:
现在有两台机器是这样的,要怎么处理
王利博
#3
减内存的方式是什么呢?
ocp是express还是云平台呢?
服务器是VM的,关了observer和obagent,缩减了,然后启动了服务。
ocp是云平台的
王利博
#5
cat ~/.obd/cluster/name/config.yaml |grep memory
show parameters LIKE ‘%memory%’; 看下
当前重启过嘛
渠磊
#6
ocp里的基于node节点进行采集,集群资源里的通过集群参数进行采集,采集方式不同导致的,可参考memory_limit这个参数
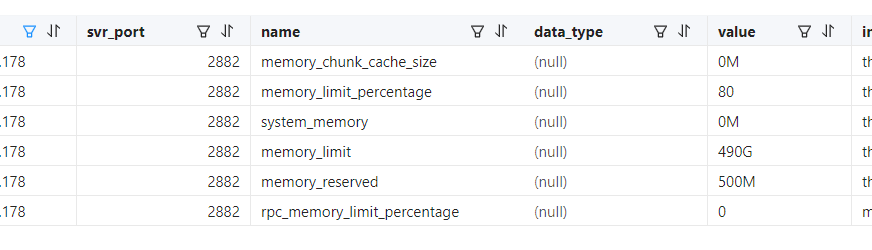
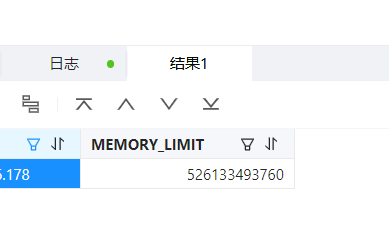
show parameters LIKE ‘%memory%’; 如下:
SELECT SVR_IP,MEMORY_LIMIT from GV$OB_SERVERS;如下:
observer和obagent 都重启过
cat ~/.obd/cluster/name/config.yaml |grep memory 在哪?没用obd部署,ocp部署的
王利博
#9
ocp422底层使用了obd部署原理。 可以发下配置文件。或者 看下oceanbase/etc/observer.config.bin 文件 里面的memory参数
渠磊
#10
从集群参数本身来说,因为这个值非0,可以手动变更这个值进行适配,若为0也可以通过memory_limit_percentage。
不过还是建议通过 ‘piping’ 提供的方案进行操作
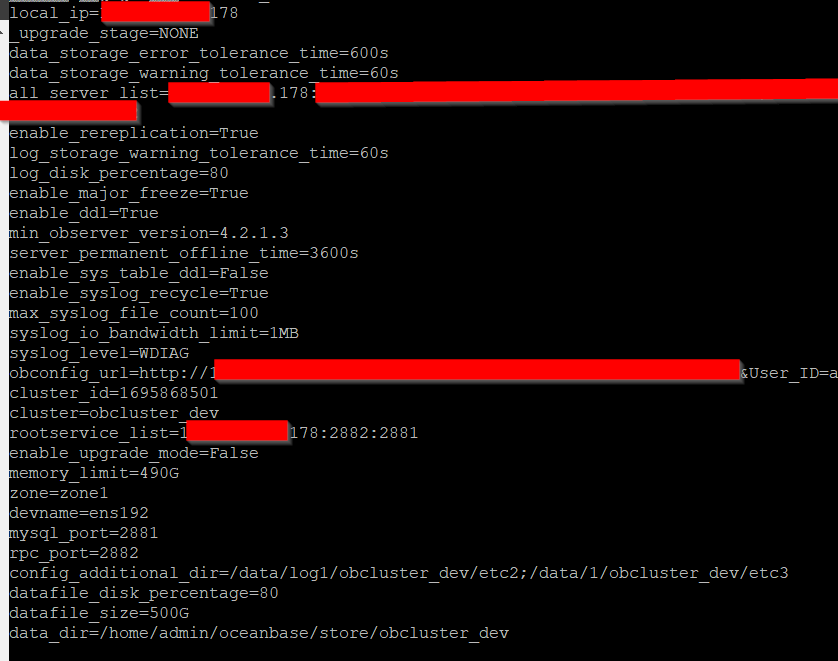
在178(显示异常机器),查看observer.config.bin,memory_limit=490G
王利博
#13
obd cluster list 看下。修改文件建议使用obd cluster edit-config name 的方式进行修改。
之后会出现一个obd cluster reload ocp命令。可以看是触发的重装机制还是重启机制
我处理好了,该集群有9台机器,2台是400左右的内存,7台是512G的,用memory_limit=490G的,我改成0,然后用了memory_limit_percentage=95,这个,现在都识别到了
王利博
#16
ocp是从低版本升级上来的嘛?
企业版还是社区版的呢?