

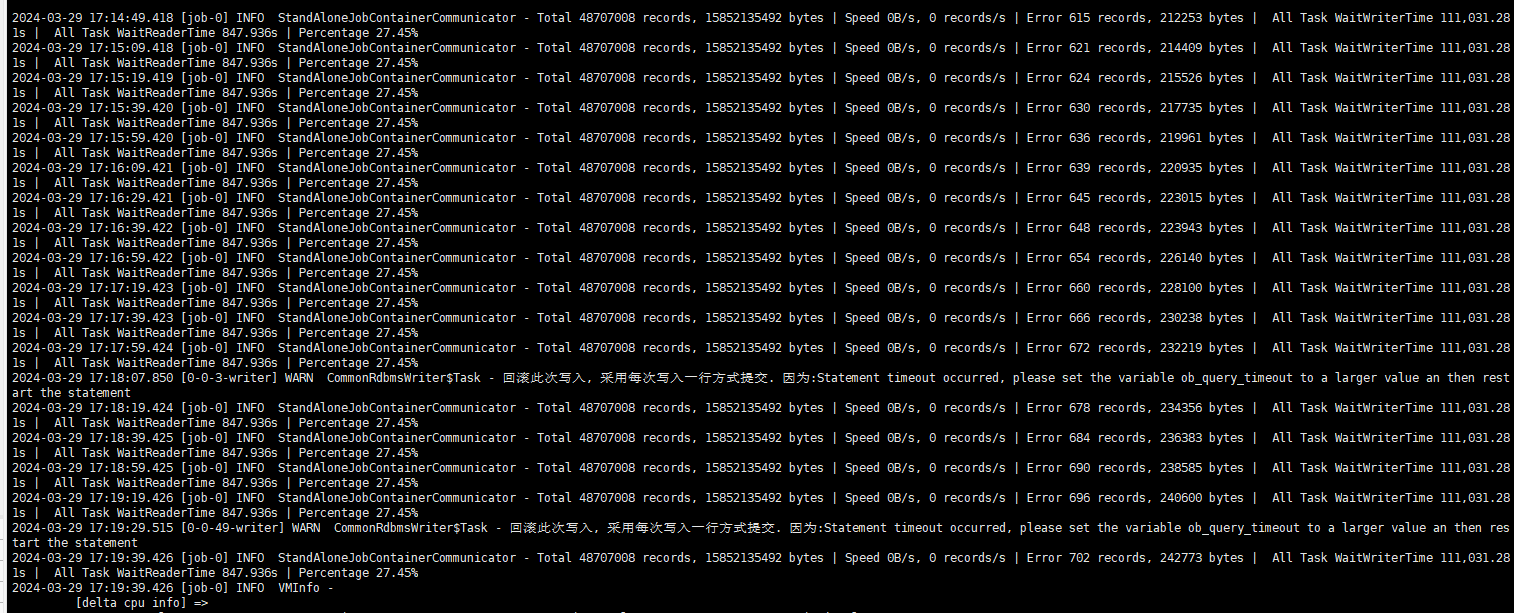
从日志看一直在报错。
登录到租户查看 SQL 审计视图 看看报错的 SQL 是什么。
视图名:gv$ob_sql_audit ,条件:plan_type in (1,2,3) and ret_code <0
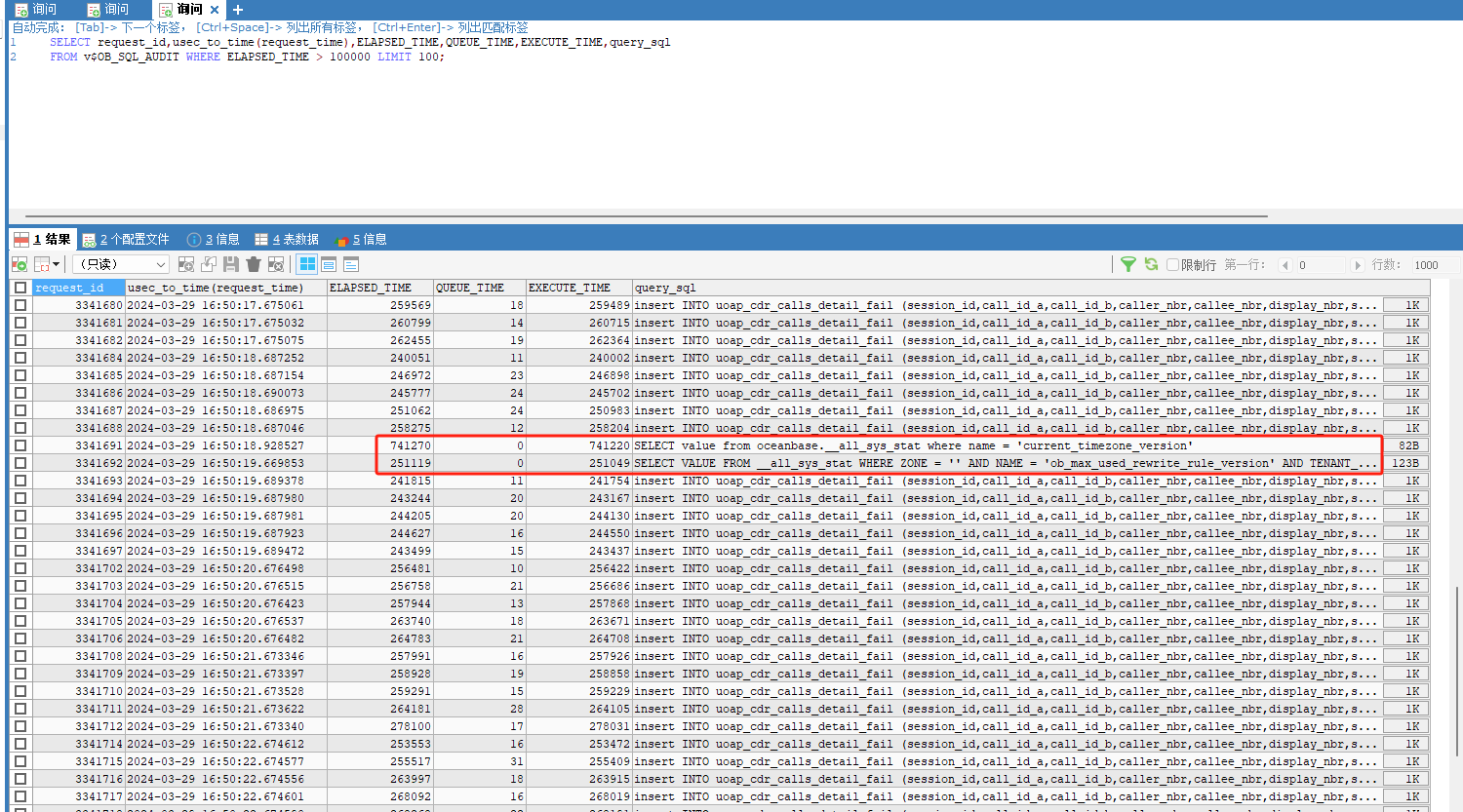

这个视图还有几个字段比较有用。 ret_code, event, return_rows,affected_rows 都看看。
此外集群节点硬件配置、租户资源配置如何也需要说明一下。方便判断是不是性能到了瓶颈。
如果有 OCP,租户的SQL和内存那个监控页面也看看。
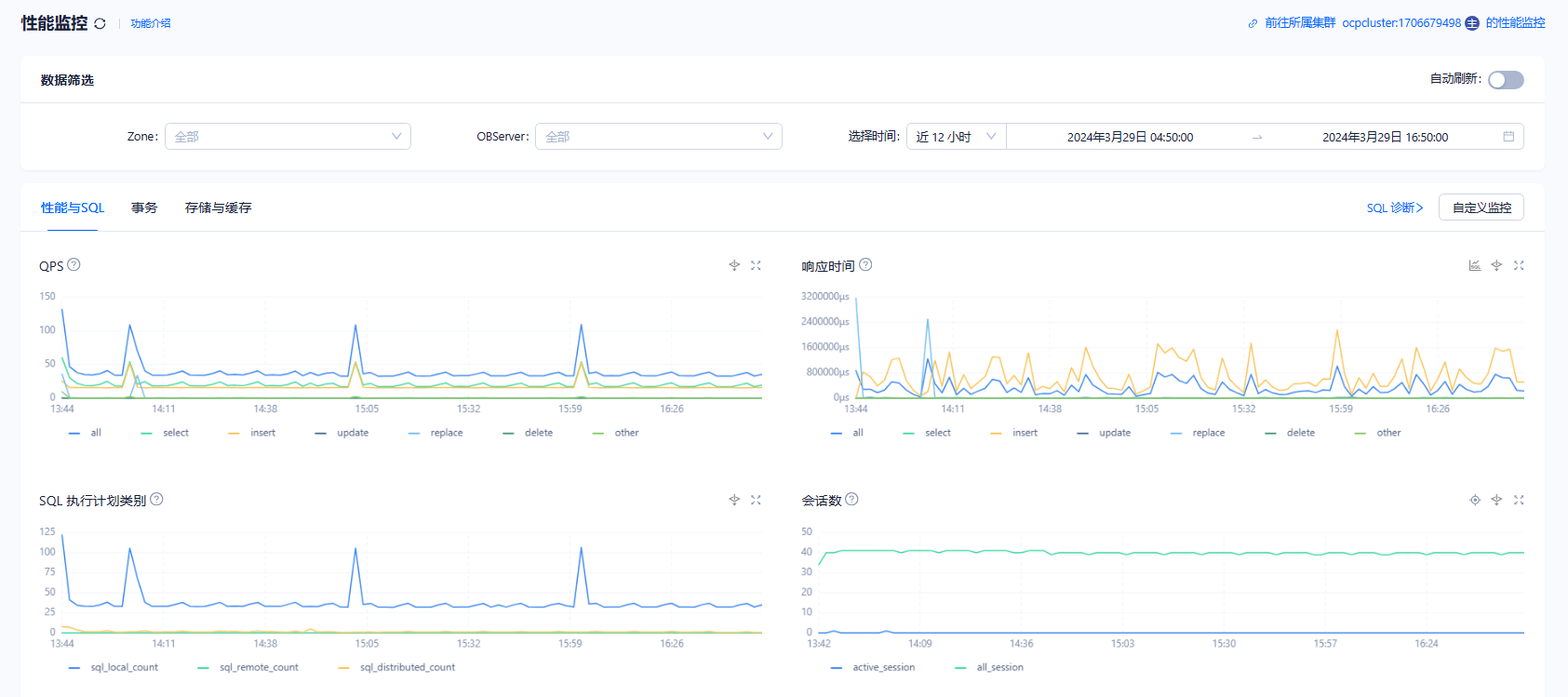

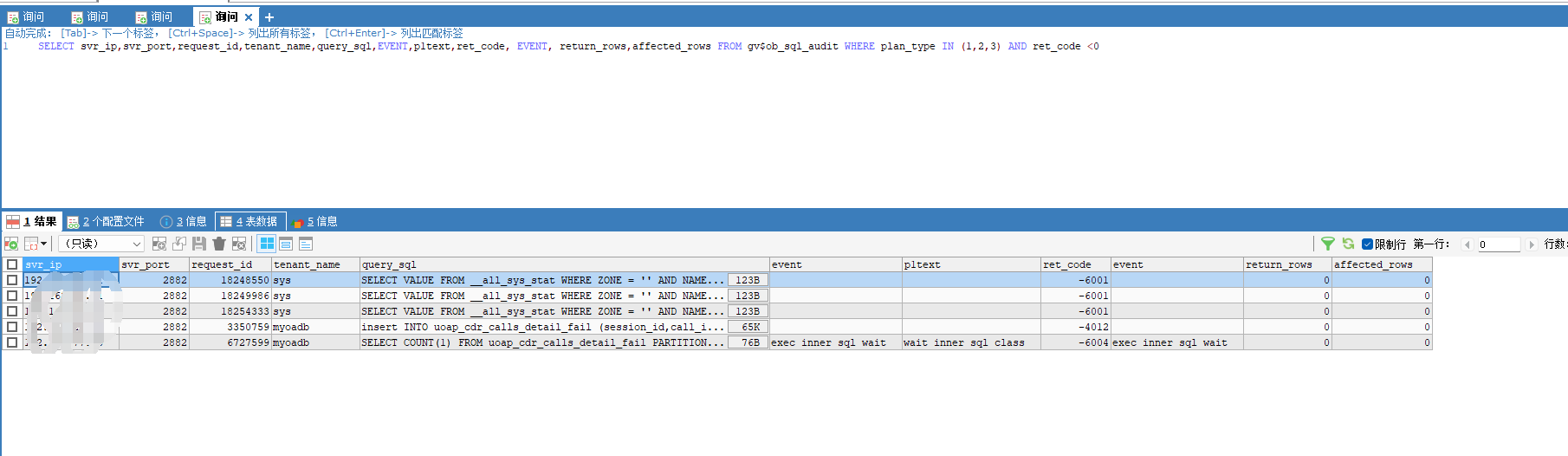
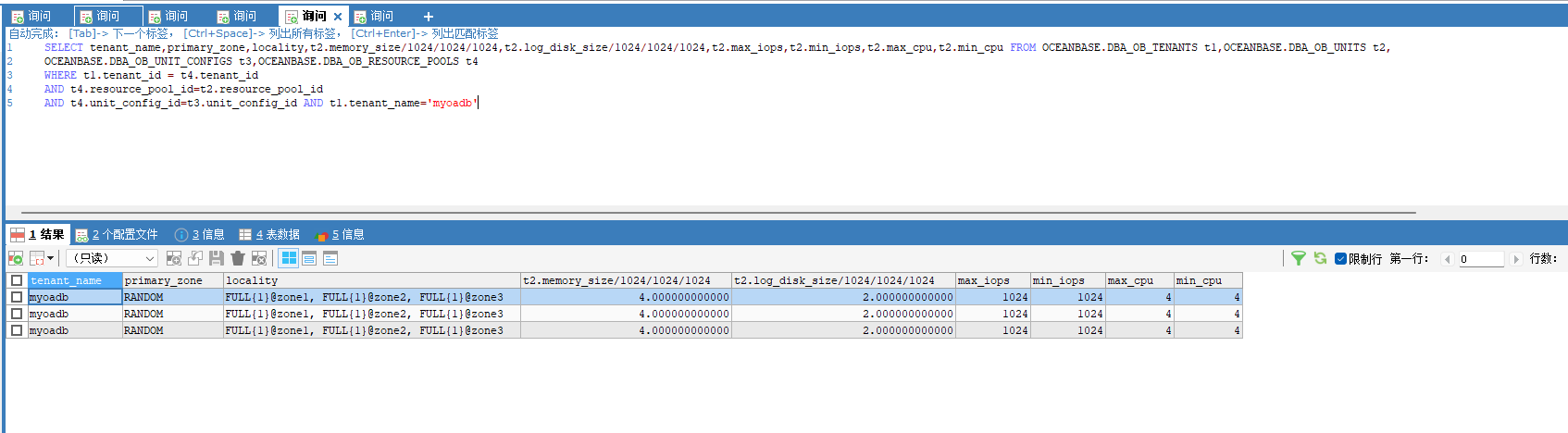
从 第一个图看报错的sql很少,只是慢。 大概率是 写入的压力太大导致业务租户 很慢,sys租户情况也要看看。
用下面 SQL 更详细一些。
select zone,concat(SVR_IP,':',SVR_PORT) observer,
cpu_capacity_max cpu_total,cpu_assigned_max cpu_assigned,
cpu_capacity-cpu_assigned_max as cpu_free,
round(memory_limit/1024/1024/1024,2) as memory_total,
round((memory_limit-mem_capacity)/1024/1024/1024,2) as system_memory,
round(mem_assigned/1024/1024/1024,2) as mem_assigned,
round((mem_capacity-mem_assigned)/1024/1024/1024,2) as memory_free,
round(log_disk_capacity/1024/1024/1024,2) as log_disk_capacity,
round(log_disk_assigned/1024/1024/1024,2) as log_disk_assigned,
round((log_disk_capacity-log_disk_assigned)/1024/1024/1024,2) as log_disk_free,
round((data_disk_capacity/1024/1024/1024),2) as data_disk,
round((data_disk_in_use/1024/1024/1024),2) as data_disk_used,
round((data_disk_capacity-data_disk_in_use)/1024/1024/1024,2) as data_disk_free
from gv$ob_servers;
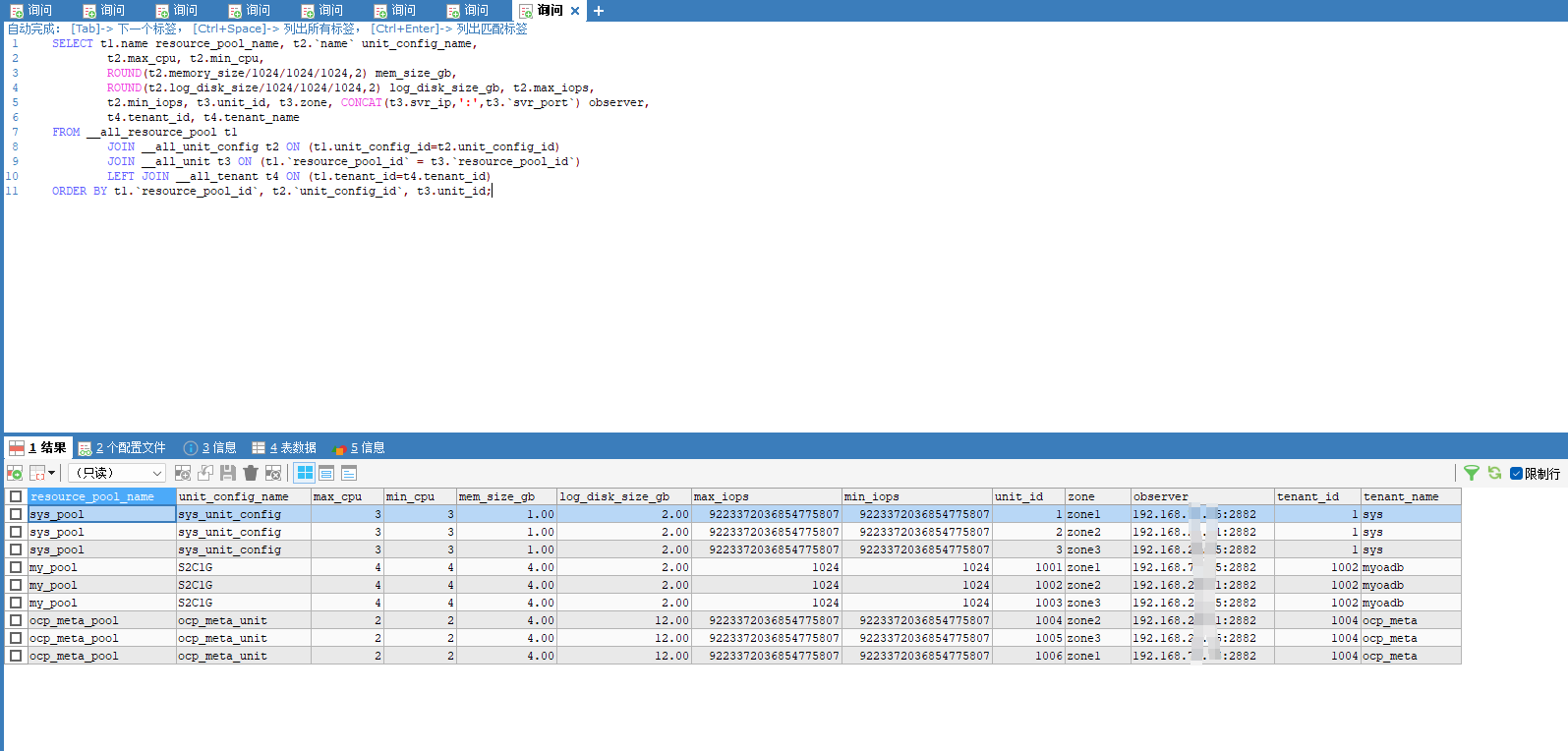
select t1.name resource_pool_name, t2.`name` unit_config_name,
t2.max_cpu, t2.min_cpu,
round(t2.memory_size/1024/1024/1024,2) mem_size_gb,
round(t2.log_disk_size/1024/1024/1024,2) log_disk_size_gb, t2.max_iops,
t2.min_iops, t3.unit_id, t3.zone, concat(t3.svr_ip,':',t3.`svr_port`) observer,
t4.tenant_id, t4.tenant_name
from __all_resource_pool t1
join __all_unit_config t2 on (t1.unit_config_id=t2.unit_config_id)
join __all_unit t3 on (t1.`resource_pool_id` = t3.`resource_pool_id`)
left join __all_tenant t4 on (t1.tenant_id=t4.tenant_id)
order by t1.`resource_pool_id`, t2.`unit_config_id`, t3.unit_id;
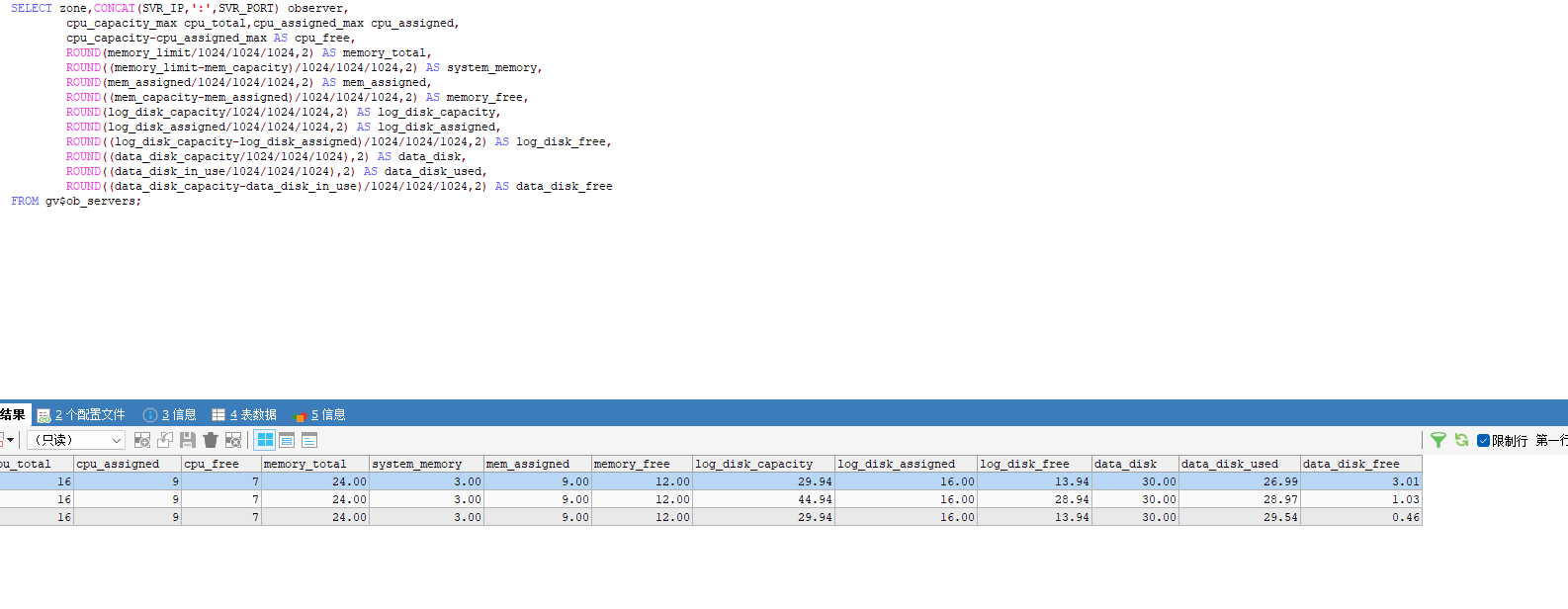
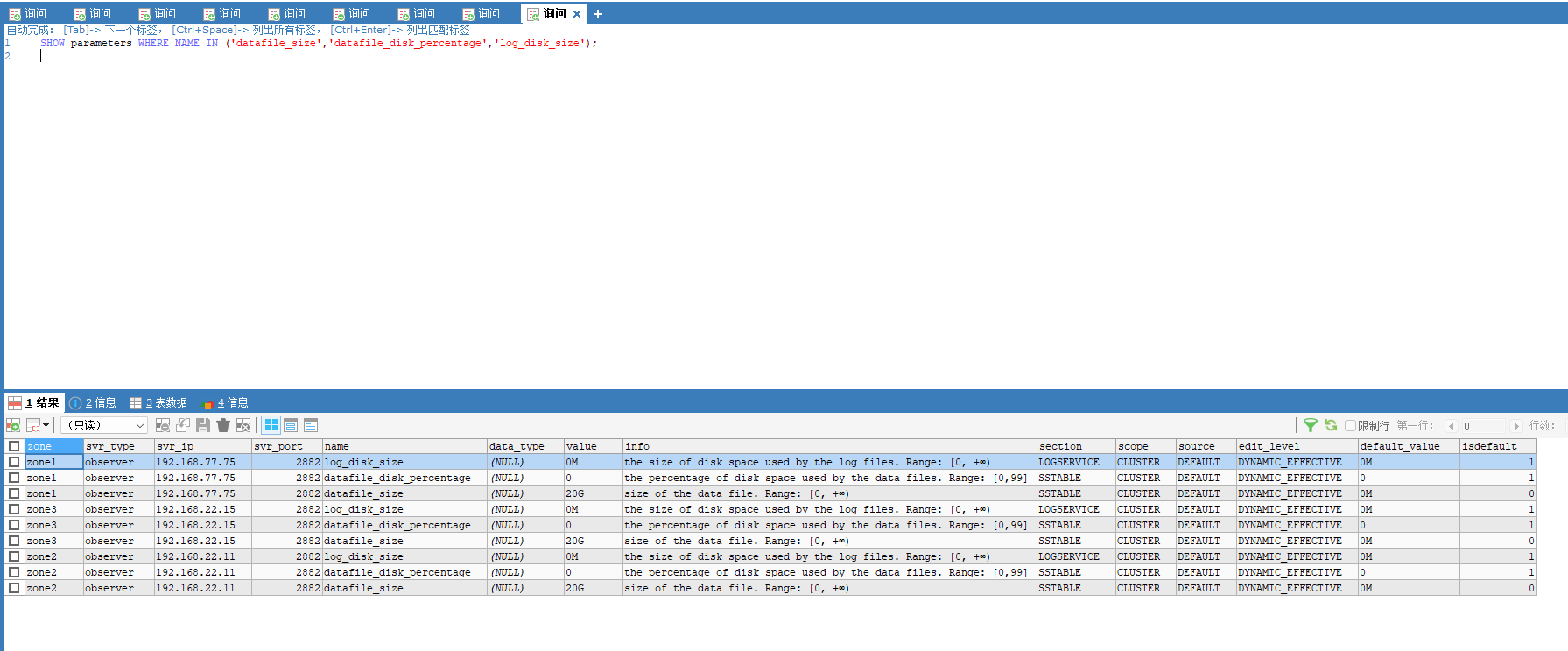
30G 磁盘空间太小,估计 clog 空间都不够。看看这个参数。
show parameters where name in ('datafile_size','datafile_disk_percentage','log_disk_size');

后面报错截图里 insert 报错主要就是插入超时,超时原因也是因为数据库变慢。数据库变慢原因之一很可能是写入超出了租户的资源能力。
租户的资源里 日志 空间大小只有 2 G 这个看起来太小。如果事务很大, clog 空间使用殆尽复用来不及,估计 observer 后台日志会有报错,前端写入会出现等待。 建议将 租户资源的 log disk size 设置到 20G。还有 sys租户的 log disk size 也不要太小,搞到 10G 以上。 sys租户的 cpu调整到5,内存调整到 5G 。
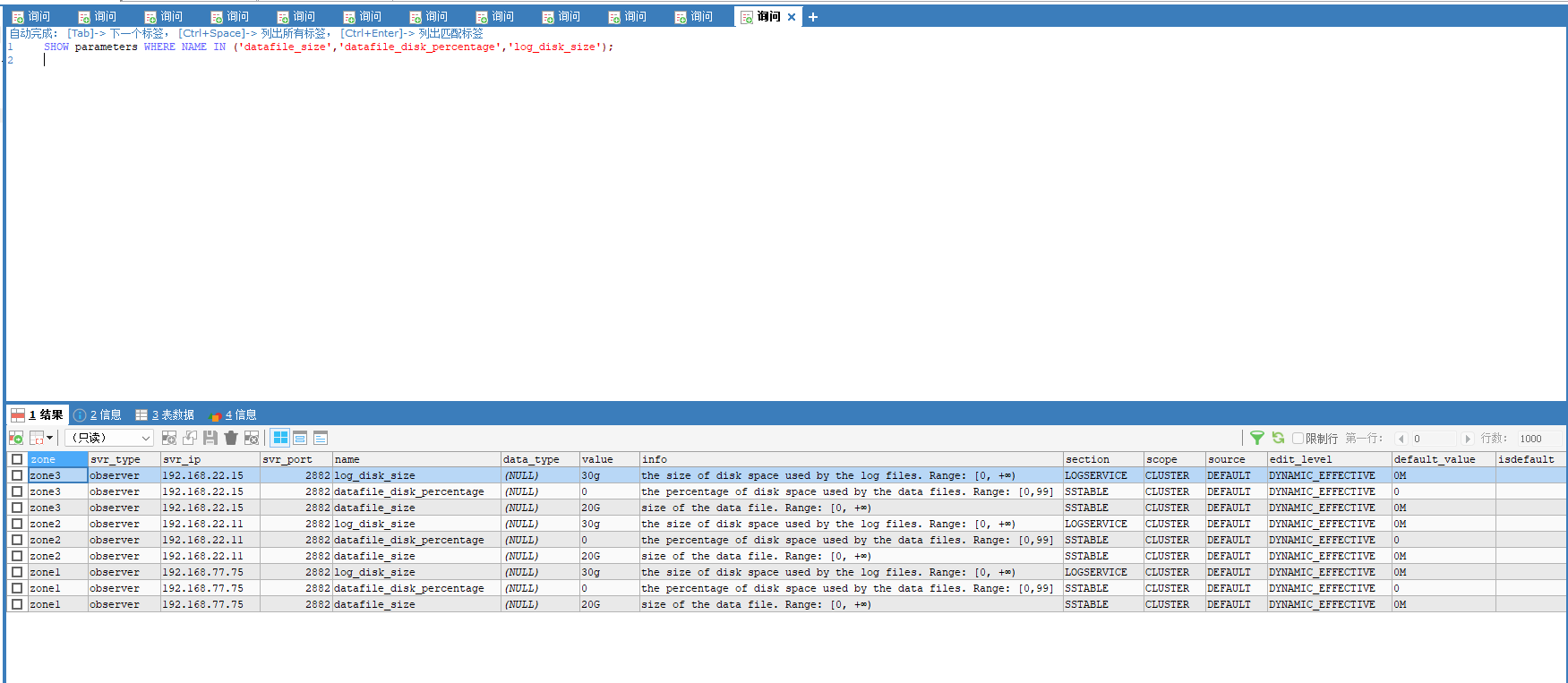
总的集群节点的 log disk size 估计不大,也增大一些。
show parameters where name in ('datafile_size','datafile_disk_percentage','log_disk_size');
CPU、内存和磁盘空间,磁盘空间是最廉价的也容易获取的,没必要这么小。做大批量数据导入,需要消耗日志空间和数据空间。
sys租户负责集群稳定运行,如果做性能测试、数据导入测试,sys租户资源也不要太少。否则内部sql 很慢。
当资源问题解决后再看看问题的现象是什么。
你好,我目前是实验阶段,主要想看看用咱的数据库存储1亿条数据的性能和磁盘占用情况,或者20-30G的数据盘能存储多少数据(目前实验阶段大概有1.8亿条数据,单表);数据盘、日志盘、cpu、内存直接要什么对应关系码?我们将来可能每天有1、2亿条数据,要存储1年,大概一年下来有200-250亿的数据要存储。
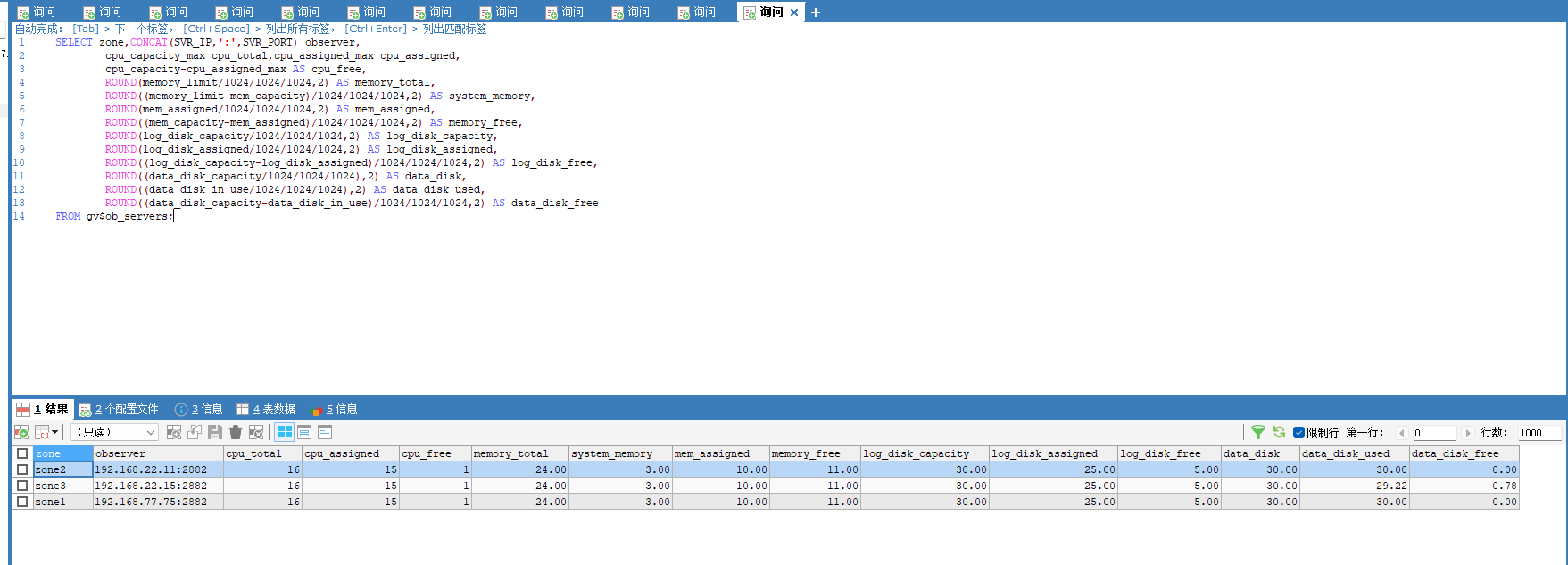

根据您之前提供的信息,我对部分参数进行了优化,如上图。
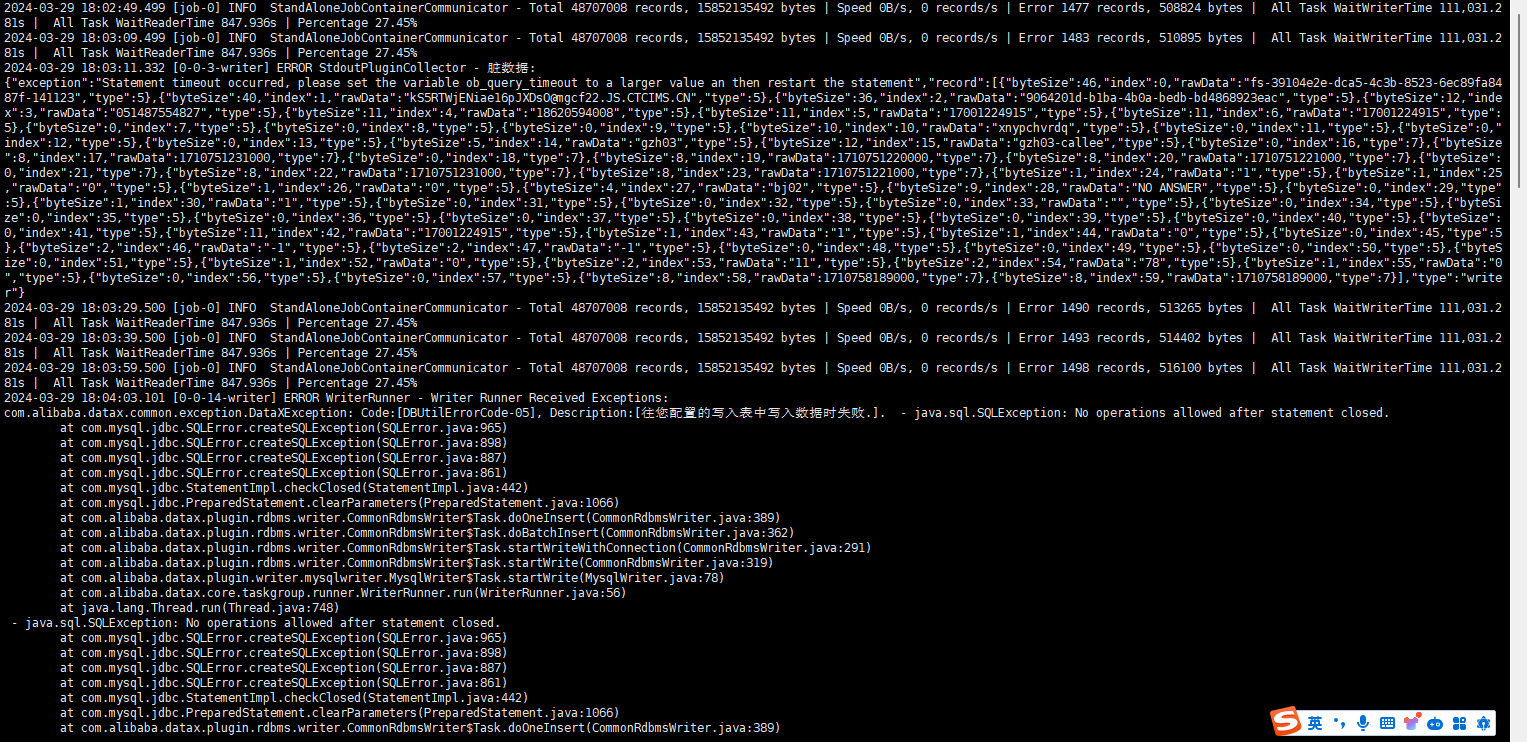
今天再导数据的时候同样卡住了,如下图:
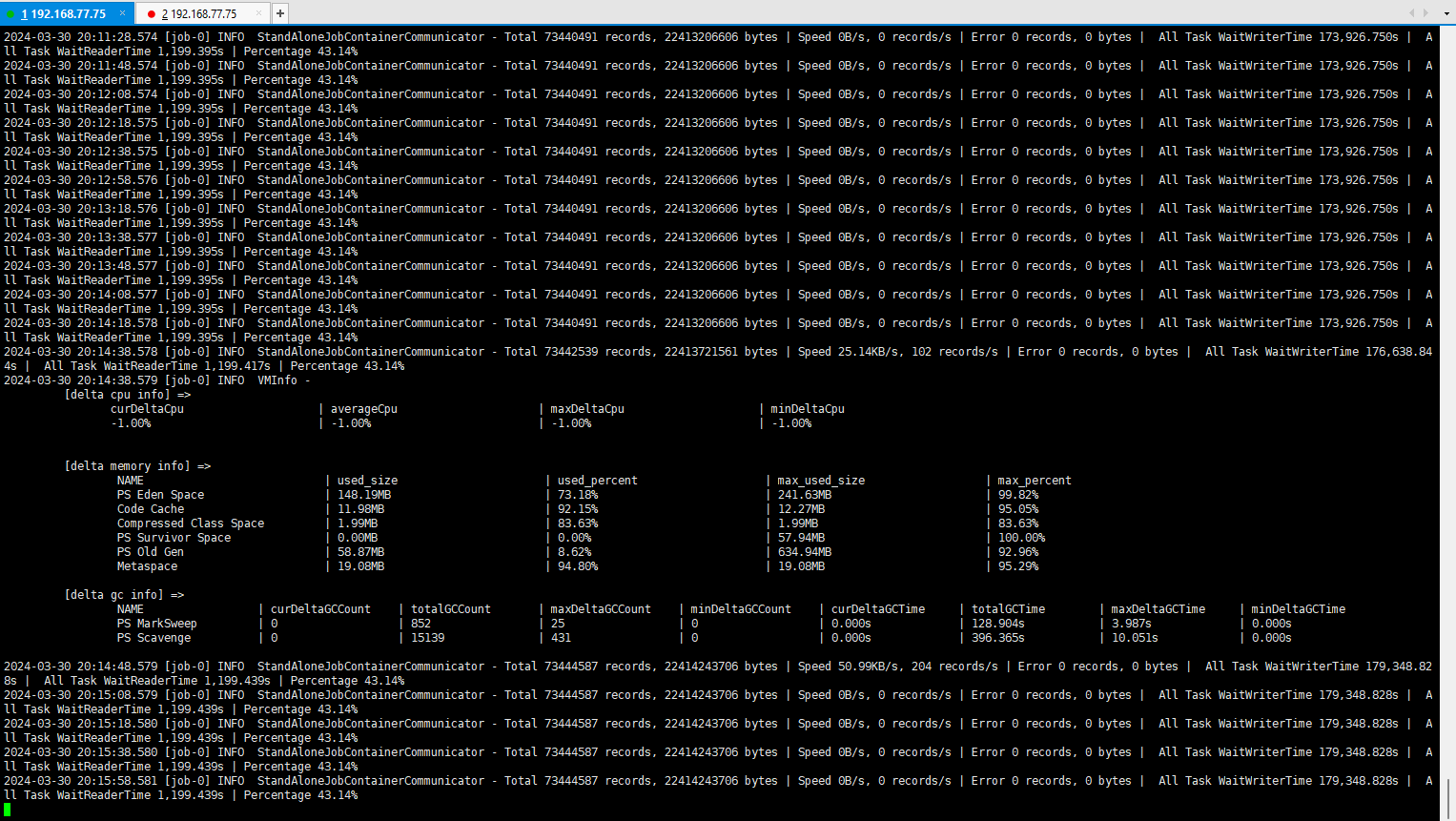
基本上应该是卡死了,今天总共导了73444587就卡住不动了。
如下是obproxy_error慢日志:
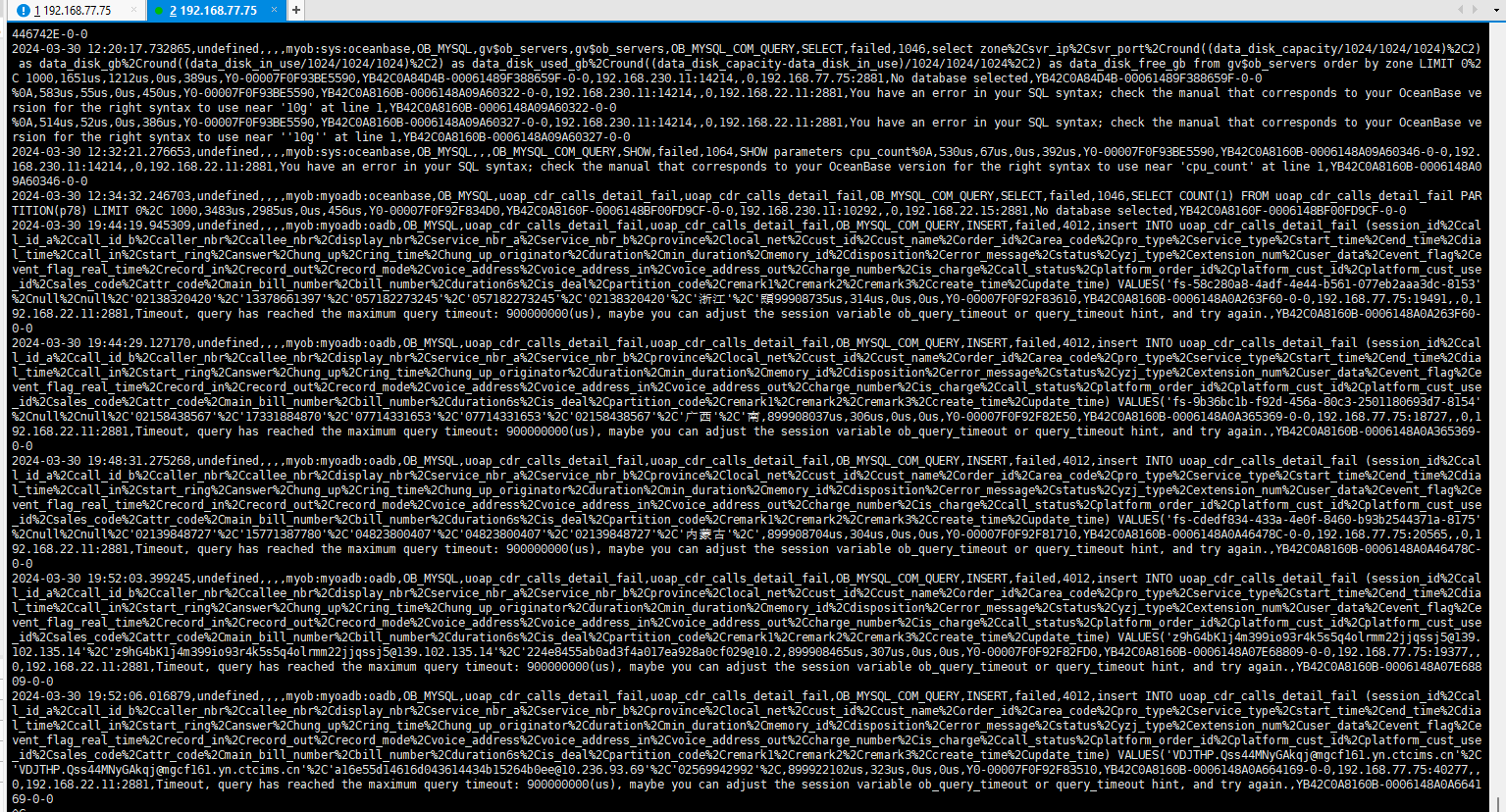
如下是部分observer.log日志
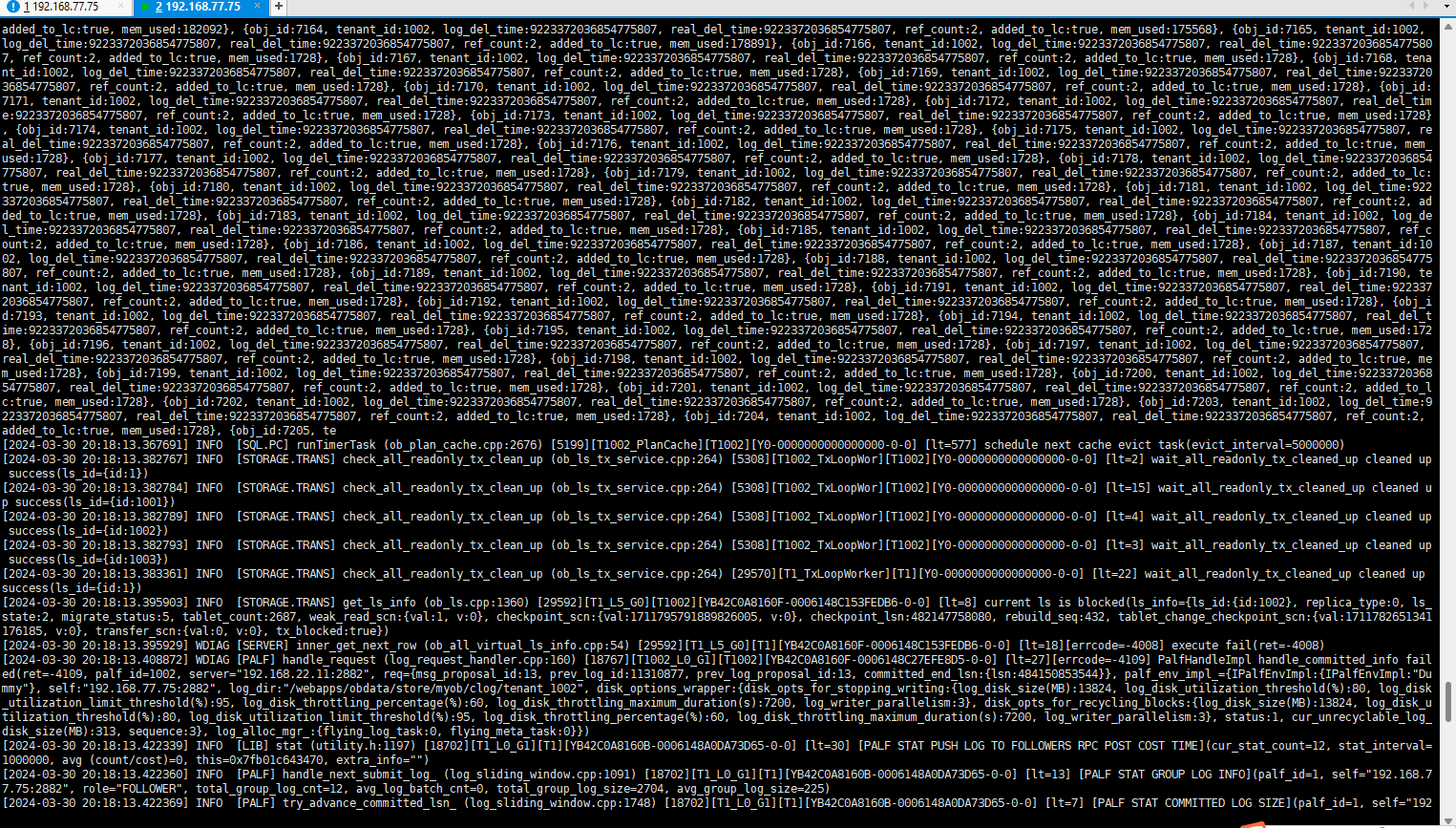
帮忙分析一下是什么原因,是datafile满了吗?
你是不是没有装 OCP?性能问题需要监控信息辅助一下。
另外发一下 datax 任务 配置文件。
OCP 的部署可以参考这个 OCP-SERVER-CE 问题交流贴 - #6,来自 obpilot
鉴于你主要目的是观察数据量,性能是其次的。可以将 datax 任务文件最后的 channel 设置为 1,避免因为数据参数设置不合理导致租户写入过快出现内存频繁转储或限速进而性能下降问题(需要监控数据核实,可以先绕过这个问题)。
再看看。
另外 4.2 的 bin 目录下有个 dooba 文件可以做命令行下实时监控。使用方法可以参考这个 https://mp.weixin.qq.com/s/gUBubuHqgxptf4DbdHcGyA
4.2 有很大变化,步骤和指标结果大体相同。
另外也发一下下面结果文本。过滤掉无关的记录。
SELECT gmt_create ,module,event,name1,value1,name2,value2,name3,value3,name4,value4 FROM oceanbase.`__all_rootservice_event_history` WHERE 1=1-- AND module IN ('server','root_service') AND gmt_create >='2024-03-21 10:27:30'ORDER BY gmt_create DESC LIMIT 100;