

【 使用环境 】生产环境
【 OB or 其他组件 】OB
【 使用版本 】OBCE 4.2.1
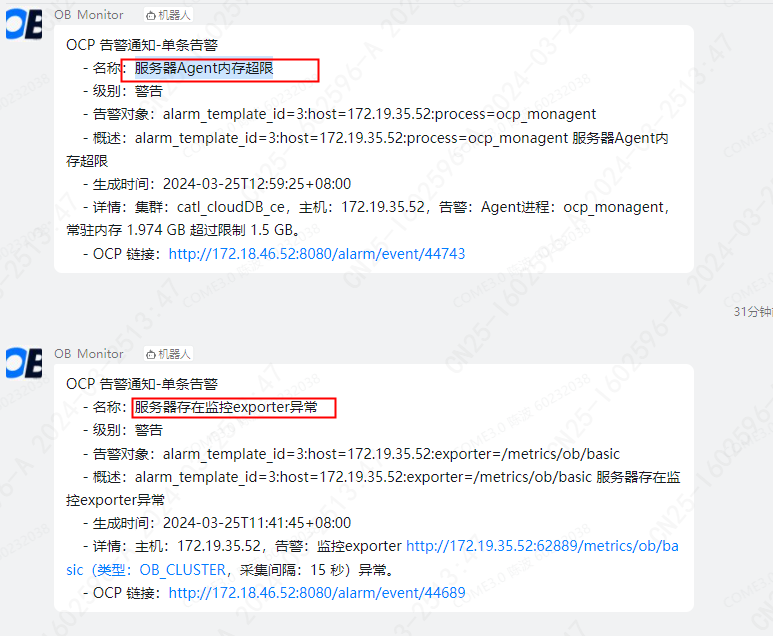
【问题描述】服务器存在监控exporter异常 && 服务器Agent内存超限
【复现路径】问题出现前后相关操作
【附件及日志】
之前一直出现内存超限问题,执行了 “/home/admin/ocp_agent/bin/ocp_agentctl config -u monagent.limit.memory.quota=4096MB”,然后重启了 ocp_agent ,观察了一周后 又复现了这个问题,并伴随着 两个告警一起出现,不知道这两个有没有直接联系?
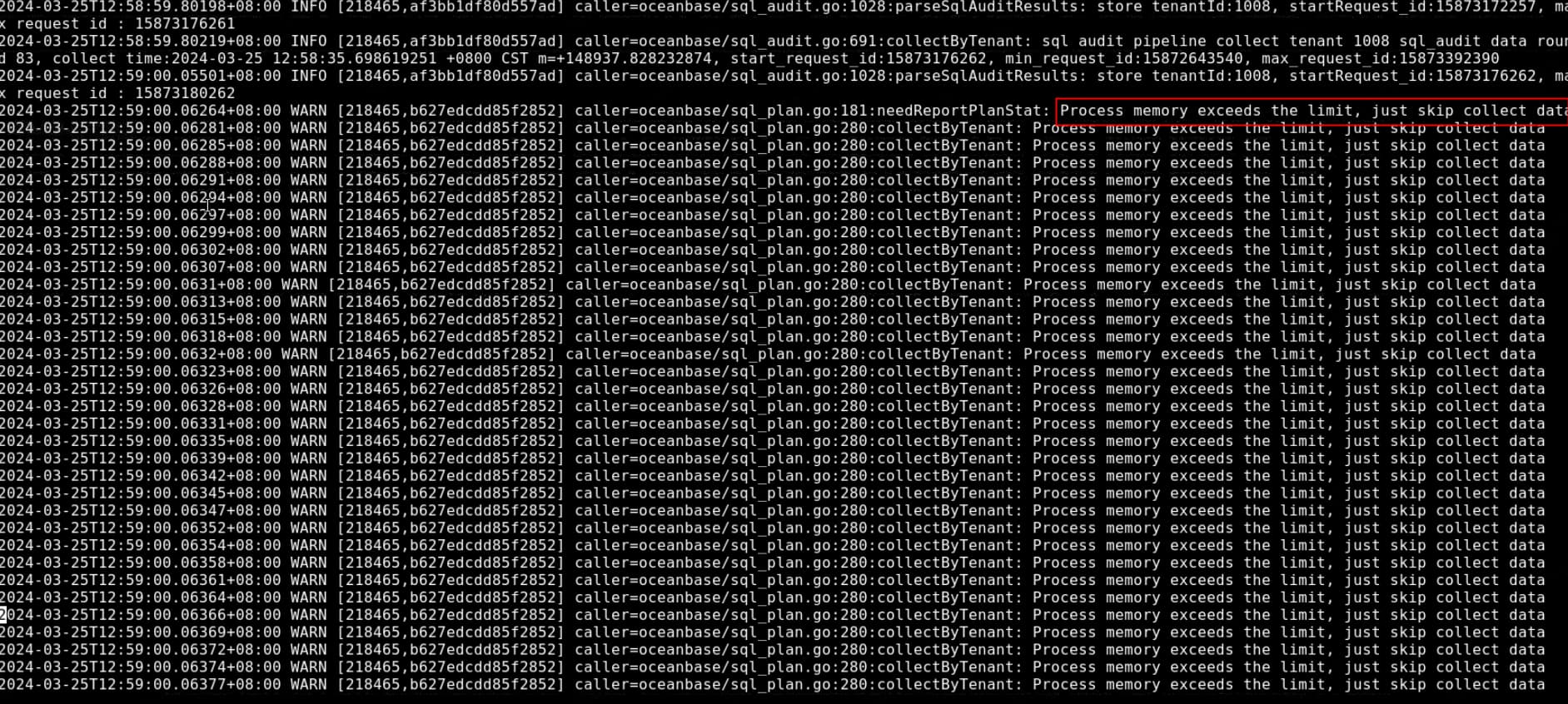
- 把服务器内存超限的那个节点的ocp_agent的日志捞回来,默认是在/home/admin/ocp_agent/log/monagent-xxx.log, 找到对应时间点的。
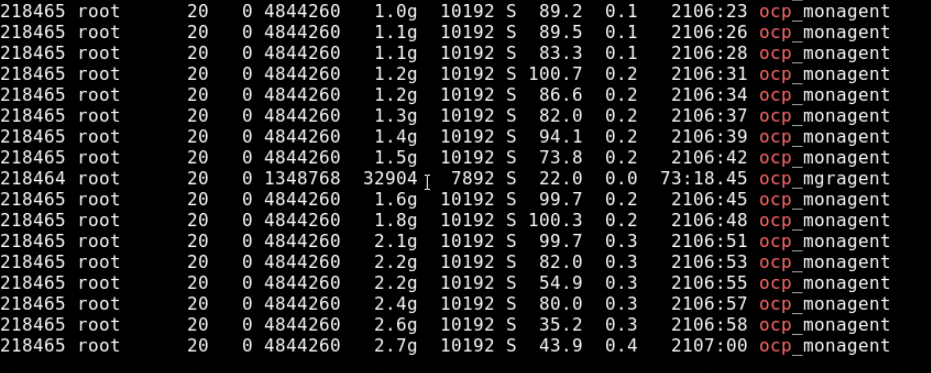
- 观察下ocp_monagent的内存使用,使用top | grep ocp_monagent看就行,是不是使用量比较高,比如超过1.5GB? 是的话,去主机上可以执行下这个命令,用于获取agent的内存调用图,发出agent来分析下内存的消耗
MON_PID=$(cat /home/admin/ocp_agent/run/ocp_monagent.pid)
curl --unix-socket /home/admin/ocp_agent/run/ocp_monagent.$MON_PID.sock http://unix-socket-server/debug/pprof/heap --output /tmp/heap.pb.gz
另:
- 这两个告警大多数时候是关联性的,ocp_agentd是ocp_agent的守护进程,对于ocp_monagent内存超限如果超过2GB会自动重启ocp_monagent,这期间可能会爆监控exporter异常的告警。
- ocp_monagent内存超限的话对ob本身没有啥影响,可能的影响点:agent内存超限会重启,重启期间,监控的数据会丢点(秒级)
1 个赞
我之前在这个节点执行过
“/home/admin/ocp_agent/bin/ocp_agentctl config -u monagent.limit.memory.quota=4096MB
/home/admin/ocp_agent/bin/ocp_agentctl restart ” 扩内存。
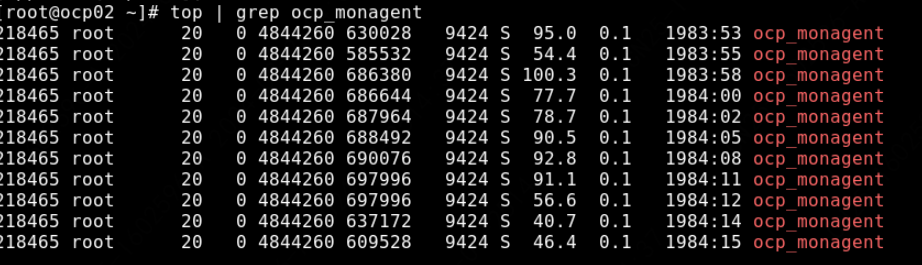
2、在节点查看 ocp_monagent 内存使用,看着都超过了 4G
3、内存的消耗
heap.pb.gz (196.3 KB)
咱们OCP管理多少节点,一共多少租户?
可以考虑升级下OCP422 有一些优化。
你截的top指令的图,得看第6列【RES】实际使用内存,实际使用内存现在才60MB左右,第5列是虚拟的内存。
从提供的heap.pb.gz文件分析了下,可以看到内存的使用情况
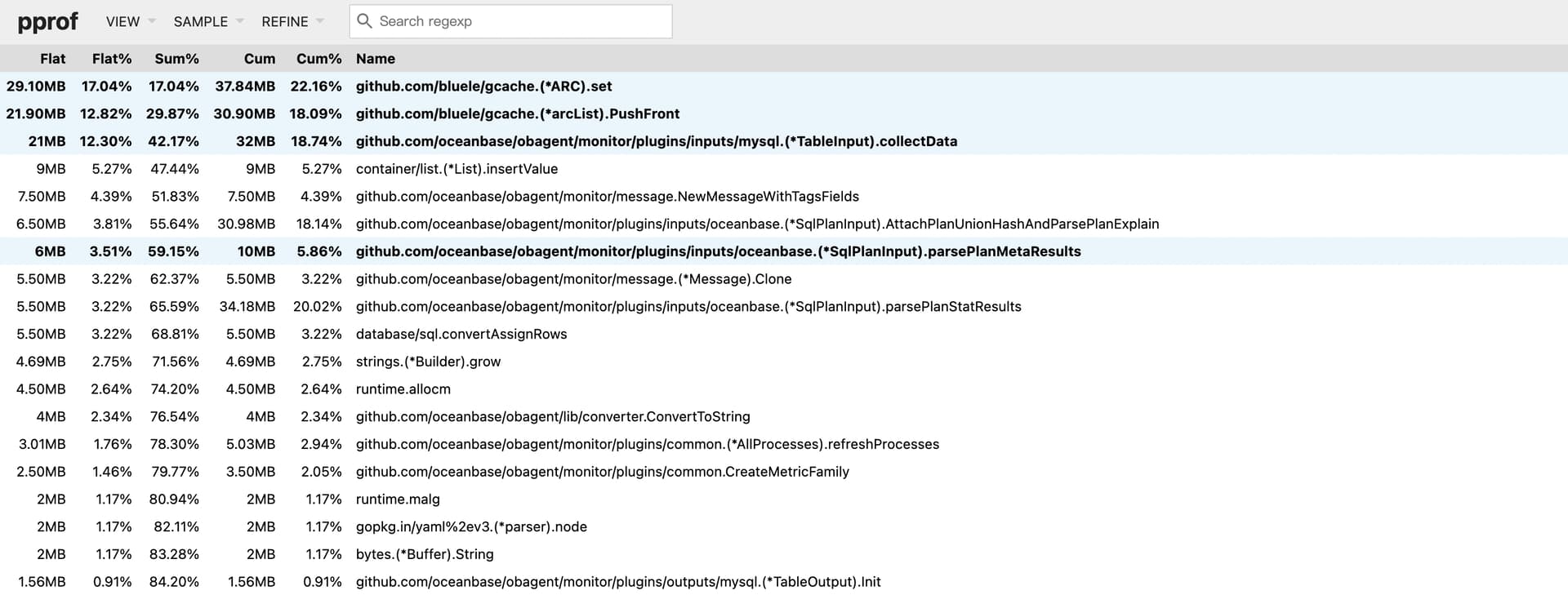
这份文件因为不是内存高的时候,所以没啥太大价值
7台机器,51个租户(包含系统租户)
根据你第二次发的heap文件分析了下, 先贴结果
File: ocp_monagent
Build ID: 9dd5b81a810ce122c7d9b2ecd215f48a830d4c0d
Type: inuse_space
Time: Mar 25, 2024 at 5:12pm (CST)
Showing nodes accounting for 1459.42MB, 100% of 1459.42MB total
----------------------------------------------------------+-------------
flat flat% sum% cum cum% calls calls% + context
----------------------------------------------------------+-------------
660.68MB 99.85% | github.com/oceanbase/obagent/monitor/plugins/inputs/oceanbase.(*SqlAuditInput).Collect /workspace/code-repo/rpm/.rpm_create/SOURCES/ocp-agent-ce/monitor/plugins/inputs/oceanbase/sql_audit.go:295 (inline)
1MB 0.15% | github.com/oceanbase/obagent/lib/log_analyzer.ParseLines /workspace/code-repo/rpm/.rpm_create/SOURCES/ocp-agent-ce/lib/log_analyzer/log_analyzer.go:86 (inline)
661.68MB 45.34% 45.34% 661.68MB 45.34% | github.com/oceanbase/obagent/monitor/message.(*Message).AddField /workspace/code-repo/rpm/.rpm_create/SOURCES/ocp-agent-ce/monitor/message/message.go:99
----------------------------------------------------------+-------------
120.06MB 67.42% | github.com/oceanbase/obagent/monitor/plugins/processors/retag.(*RetagProcessor).Process /workspace/code-repo/rpm/.rpm_create/SOURCES/ocp-agent-ce/monitor/plugins/processors/retag/retag.go:108 (inline)
29.01MB 16.29% | github.com/oceanbase/obagent/monitor/plugins/processors/retag.(*RetagProcessor).Process /workspace/code-repo/rpm/.rpm_create/SOURCES/ocp-agent-ce/monitor/plugins/processors/retag/retag.go:125 (inline)
13.50MB 7.58% | github.com/oceanbase/obagent/monitor/common.(*addTags).Apply /workspace/code-repo/rpm/.rpm_create/SOURCES/ocp-agent-ce/monitor/common/transformer.go:126 (inline)
13MB 7.30% | github.com/oceanbase/obagent/lib/log_analyzer.(*ObLogAnalyzer).ParseLine /workspace/code-repo/rpm/.rpm_create/SOURCES/ocp-agent-ce/lib/log_analyzer/ob_log_analyzer.go:148 (inline)
2.50MB 1.40% | github.com/oceanbase/obagent/monitor/plugins/inputs/log_tailer.(*LogTailerExecutor).processLogByLine.func2 /workspace/code-repo/rpm/.rpm_create/SOURCES/ocp-agent-ce/monitor/plugins/inputs/log_tailer/log_tailer_executor.go:139 (inline)
178.08MB 12.20% 57.54% 178.08MB 12.20% | github.com/oceanbase/obagent/monitor/message.(*Message).AddTag /workspace/code-repo/rpm/.rpm_create/SOURCES/ocp-agent-ce/monitor/message/message.go:161
----------------------------------------------------------+-------------
95MB 100% | github.com/oceanbase/obagent/monitor/plugins/inputs/log_tailer.(*LogTailerExecutor).processLogByLine.func1 /workspace/code-repo/rpm/.rpm_create/SOURCES/ocp-agent-ce/monitor/plugins/inputs/log_tailer/log_tailer_executor.go:124 (inline)
95MB 6.51% 64.05% 95MB 6.51% | bufio.(*Scanner).Text /home/admin/go/src/bufio/scan.go:113
----------------------------------------------------------+-------------
49.54MB 100% | database/sql.(*Rows).Scan /home/admin/go/src/database/sql/sql.go:3287
49.54MB 3.39% 67.44% 49.54MB 3.39% | database/sql.convertAssignRows /home/admin/go/src/database/sql/convert.go:261
----------------------------------------------------------+-------------
44.08MB 100% | strings.(*Builder).Grow /home/admin/go/src/strings/builder.go:82 (inline)
44.08MB 3.02% 70.47% 44.08MB 3.02% | strings.(*Builder).grow /home/admin/go/src/strings/builder.go:68
再说结论:
目前最消耗内存的是sql_audit插件的采集,sql_audit数据是和业务流量强相关的,说明业务侧应该是流量比较大。
再帮忙去ocp的monitordb中查几个数据:
select cluster_name,count(1) from ob_hist_sql_audit_stat_0 partition(P20240324) group by cluster_name;
select cluster_name,count(1) from ob_hist_sql_audit_stat_0 partition(P20240325) group by cluster_name;
select cluster_name,count(1) from ob_hist_sql_audit_sample partition(P20240324) group by cluster_name;
select cluster_name,count(1) from ob_hist_sql_audit_sample partition(P20240325) group by cluster_name;
select cluster_name,count(1) from ob_hist_sqltext partition(P20240324) group by cluster_name;
select cluster_name,count(1) from ob_hist_sqltext partition(P20240325) group by cluster_name;
另:拿到agent的heap.pb.gz文件后可以用go tool打开看看,
go tool pprof -http=127.0.0.1:8081 heap.pb.gz
mysql> select cluster_name,count(1) from ob_hist_sql_audit_stat_0 partition(P20240324) group by cluster_name;
+-----------------+----------+
| cluster_name | count(1) |
+-----------------+----------+
| catl_cloudDB_ce | 6219530 |
| XMdbcloud | 1405060 |
+-----------------+----------+
2 rows in set (1.19 sec)
mysql> select cluster_name,count(1) from ob_hist_sql_audit_stat_0 partition(P20240325) group by cluster_name;
+-----------------+----------+
| cluster_name | count(1) |
+-----------------+----------+
| catl_cloudDB_ce | 3668364 |
| XMdbcloud | 742093 |
+-----------------+----------+
2 rows in set (1.25 sec)
mysql> select cluster_name,count(1) from ob_hist_sql_audit_sample partition(P20240324) group by cluster_name;
+-----------------+----------+
| cluster_name | count(1) |
+-----------------+----------+
| catl_cloudDB_ce | 4672981 |
| XMdbcloud | 1494 |
+-----------------+----------+
2 rows in set (0.78 sec)
mysql> select cluster_name,count(1) from ob_hist_sql_audit_sample partition(P20240325) group by cluster_name;
+-----------------+----------+
| cluster_name | count(1) |
+-----------------+----------+
| catl_cloudDB_ce | 1613409 |
| XMdbcloud | 1031 |
+-----------------+----------+
2 rows in set (0.47 sec)
mysql> select cluster_name,count(1) from ob_hist_sqltext partition(P20240324) group by cluster_name;
+-----------------+----------+
| cluster_name | count(1) |
+-----------------+----------+
| catl_cloudDB_ce | 110518 |
| XMdbcloud | 1373 |
+-----------------+----------+
2 rows in set (0.22 sec)
mysql> select cluster_name,count(1) from ob_hist_sqltext partition(P20240325) group by cluster_name;
+-----------------+----------+
| cluster_name | count(1) |
+-----------------+----------+
| catl_cloudDB_ce | 79958 |
| XMdbcloud | 1247 |
+-----------------+----------+
2 rows in set (0.18 sec)
看起来catl_cloudDB_ce这个集群一天的sql采集数据量比较大,注意到ob_hist_sql_audit_stat_0和ob_hist_sql_audit_sample都是百万级别。其中ob_hist_sql_audit_stat_0是用于sql诊断页面的基础数据的,ob_hist_sql_audit_sample这张表主要存储的是慢sql/并行sql/事务相关的采样sql。这里边可能可减少的数据是ob_hist_sql_audit_sample,需要再往下再挖一下看看具体的采样类型是啥。
select cluster_name,cause_type, count(1) from ob_hist_sql_audit_sample partition(P20240324) group by cluster_name, cause_type;
select cluster_name,cause_type, count(1) from ob_hist_sql_audit_sample partition(P20240325) group by cluster_name, cause_type;
比如可以调整一下慢sql进入的阈值,
去对应集群的节点上执行:
# 默认monagent.ob.slow.sql.threshold慢sql的采集阈值是100ms, 这个改动成1000ms,对于分析sql问题也基本够用了
/home/admin/ocp_agent/bin/ocp_agentctl config -u monagent.ob.slow.sql.threshold=1000ms
当然直接停止sql的采集是最直接有效降低agent内存的方法,关闭了sql采集,top sql就没数据了,想分析sql问题就不好在ocp上看了,其他的监控功能都不受到影响。看你们的取舍吧,我只提供方法:
能不能通过增加ocp_monagent 内存 来规避这个问题?
主机内存还有富裕的话是可以再增加agent内存来规避的。
你说的这个超过阈值 就会重启ocp_monagent ,这个阈值在哪里可以调整?
老师,我使用 go tool pprof -http=127.0.0.1:8081 heap.pb.gz 之前,是否需要先安装go语言包