【 使用环境 】生产环境
【 OB or 其他组件 】V4.2.1.3
【 使用版本 】
【问题描述】清晰明确描述问题
【复现路径】问题出现前后相关操作
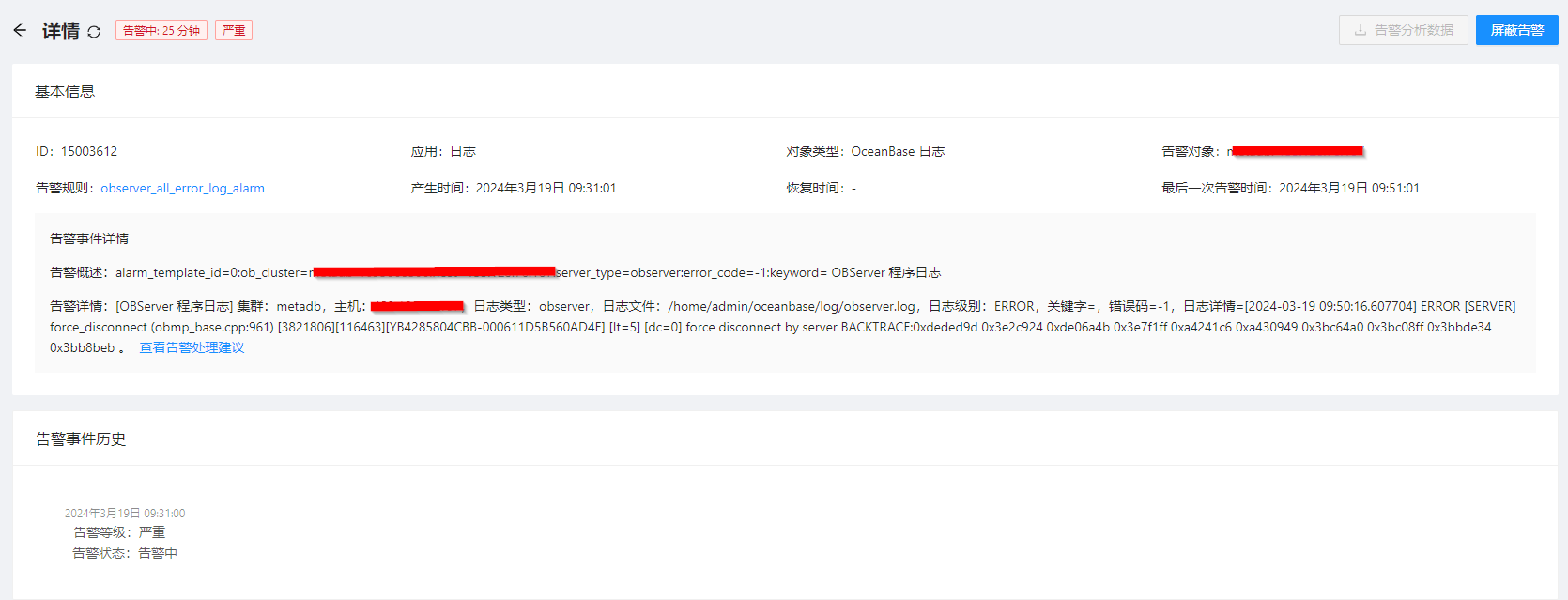
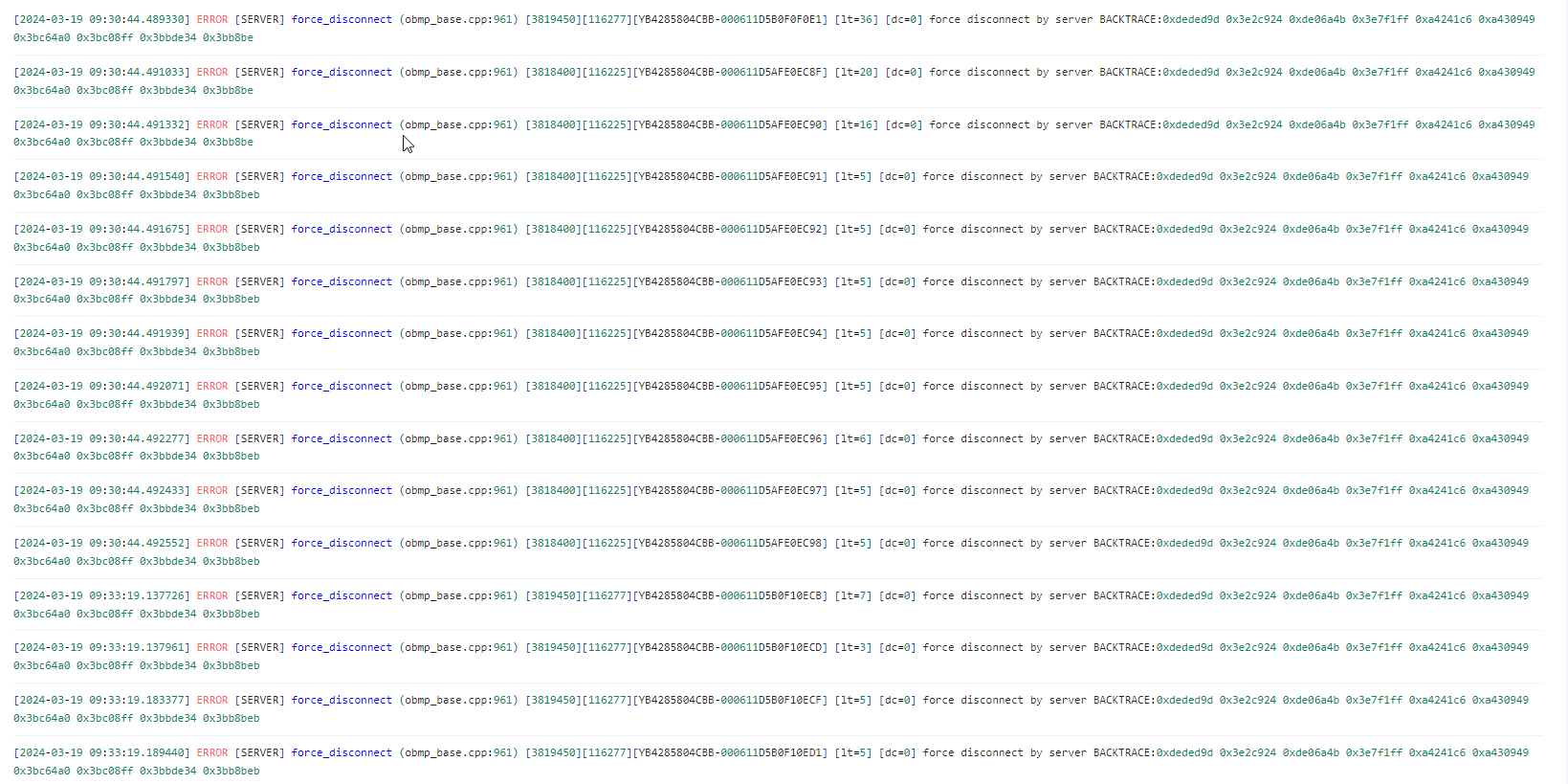
此类告警,会使什么问题呢,会经常出现,但不影响使用,哪些情况会有这个报错?通过报错也看不出来什么有效的信息
【 使用环境 】生产环境
【 OB or 其他组件 】V4.2.1.3
【 使用版本 】
【问题描述】清晰明确描述问题
【复现路径】问题出现前后相关操作
此类告警,会使什么问题呢,会经常出现,但不影响使用,哪些情况会有这个报错?通过报错也看不出来什么有效的信息
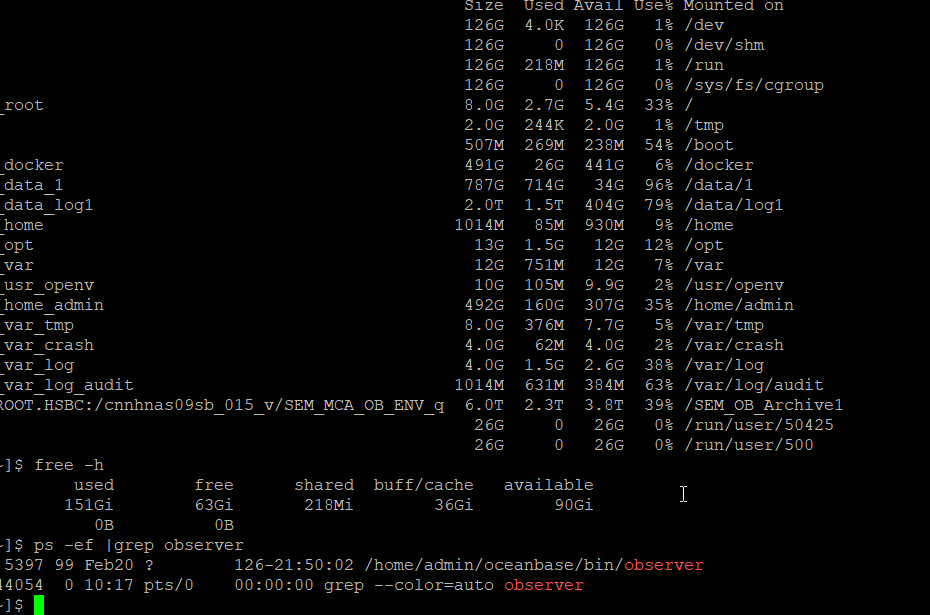
可以发下完整的observer日志和当前的资源情况(df -h && free -h && ps -ef |grep observer)
clog 才是80%,超过了开始复用的
数据盘是96%了
应该不是和这些有关
清理了些空间还有相关告警嘛?
是的,还是存在
metadb 集群 都是集群内部再用的,没有业务,客户,用这个