

我想使用社区版部署一组生产环境的oceanbase,主要是在两地部署,可以三中心,也可以两中心,数据量大概在百亿左右,上限不会超过千亿,具体两地是一地读写,一地可以读,有什么推荐的部署架构吗,主要关注点是分几个zone,每个zone需要多少台机器,每台机器推荐什么配置,,读写分离应该如何实现呢,如何设置通过proxy访问就直接读写分离
我理解是有两个问题,一个是部署模式,一个是如何设置读写分离。
- 部署模式
部署模式推荐两地三中心,分几个 zone 就有几份副本,副本越多可用性越高,成本也越高。三中心根据您的可用性需求,可以分成三副本或者五副本。
以两地(region)三中心三 zone 三副本为例,可以设置 zone 的优先级为 zone1,zone2;zone3。含义是 region1 有两个 zone,zone1 和 zone2,这两个 zone 的优先级高于另一个 region2 里的 zone3。这样,主副本都会分布在第一个 region2 的 zone1 和 zone2 上,所有的写操作都会在 region1 上完成。然后通过配置弱一致性读,让 region2 里的 zone3 可以提供只读服务。详见:OceanBase分布式数据库-海量数据 笔笔算数
机器的硬件配置要求详见:OceanBase分布式数据库-海量数据 笔笔算数
至于每个 zone 有几台机器,要看具体数据量和每台节点磁盘空间的关系。数据量没上去之前,可以暂时先在每个 zone 内少分配几台节点,数据量上去之后再动态扩展就好了,OB 会完成自动的节点间负载均衡。
- 如何设置读写分离
可以在上面提到的 region2 里的 zone3 上放一个专用的 proxy,通过配置项中的 obproxy_read_consistency 设置下默认走弱读就好了。详见:OceanBase分布式数据库-海量数据 笔笔算数 或 OceanBase分布式数据库-海量数据 笔笔算数
最后推荐直接在官网上搜索关键字,会有相关的资料~
好的,但是像你所说的那样,我可以配置两地两个obproxy集群,observer分3个zone,然后我让访问zone3的那个obproxy集群设置成弱一致性读,但是弱一致性读可能会出现一些数据不准确的现象吧,这种现象多吗,如何能够避免这种现象呢
- proxy 就是一个独立的进程,不是集群。
- 弱一致性读会有读不到最新数据的可能,一般用于对数据一致性要求不高的场景。
- 如果您的场景是读多写少,且对读操作的数据一致性要求特别高,可以考虑使用一个叫做 “复制表” 的功能,复制表可以在任意一个副本上读取到最新的数据,能够规避您说的问题。您可以自己在 OB 官网上搜一下这个关键字。
好的,是我的表述有问题,我的obproxy集群的意思是高可用多个obproxy节点,那这种关于弱一致性的实现范围有测试吗,因为我理解等到observer的leader副本同步过去到follow副本以后就会一致了,这个同步时间有一个大概的范围吗,或者说如果读的多对一致性要求高的话就还是强一致性读比较好吧
我理解同步时间受限于两个 region 的距离以及光速。
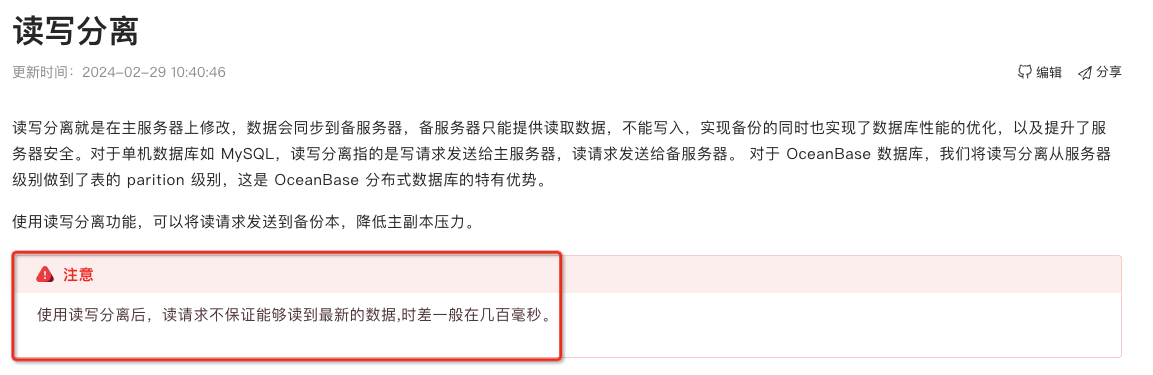
如果要进行弱读的 follower 副本和 leader 副本都在同一个 region,或者两个逻辑上的 region 实际都在同一个物理地域的话,同步时间一般是几个毫秒。真的异地的话,几十到几百个毫秒都有可能。
保守来说,会延迟几百毫秒。这里就直接参考 OB 官网上的数字吧~
如果是 AP 分析类的报表业务,一般用弱读问题不大。但是实时交易支付之类的业务,还是需要用强一致性读。用弱读还是强读,还是要看您的具体业务对实时性和数据一致性的要求~
好的,谢谢,具体细节我再看下文档吧,那这个说的大概时间是在几百毫秒,如果是我的长连接的话几百毫秒以后读会读到弱一致性的缓存数据吗,还是就是同步后的链接都是会读到最新数据的吧
读到的是最新的数据。OB 只会通过 plan cahce 去缓存执行计划,不会像某些数据库一样去缓存查询结果的数据。所以几百毫秒以后,SQL 执行引擎会用新的数据去重新进行计算。
好的,谢谢