

社区版版本是4.2.1:
我在南京有一个机房,在苏州有两个机房,我想采取多一个集群多zone形式部署,在南京一个zone,苏州可以是一个zone或者两个zone,然后的话通过obproxy访问,在南京用南京部署得obproxy,苏州用苏州部署得obproxy访问,要求访问的时候做到就近访问,比如南京的obproxy访问的一定是南京的zone,苏州的同理,这个部署在一个集群的情况下如何能够保证多zone的就近访问呢,我是采取3zone形势好还是两zone呢,有什么案例或者详细的操作可以给一下案例吗,
听起来像是 苏州地区的银行的客户 ![]()
-
客观机房是三机房,两个同城,一个异地。在传统数据库方案里就是同城高可用,异地灾备。使用OB 的效果也差不多。
-
如果不缺机器对可用性、稳定性和性能要求很高的话,部署5副本,5台机器起步。苏州每个机房2副本,南京机房一个副本。 苏州两个机房可以同时提供读写服务,南京机房的不提供读写服务。实在需要,可以做只读查询。应该用不上。因为苏州2机房4个副本足够满足业务读需求了。
-
如果缺机器,那就三副本,每个机房一个副本。同样是苏州两机房双活,南京机房的最多只提供只读查询(读写分离)。这个抵抗风险的能力比前面要低一些。
-
如果还有机器或者南京机房配置还行,在南京机房在单独部署一个单节点的OB 备集群,主备集群同步模式最大性能。
以上是最有可能的架构。
1 个赞
不是,在同一个集群的基础上,我想要在两地都进行读写,主要是要南京的obproxy可以读写南京的zone,苏州的obproxy直接读写苏州的zone,这个应该怎么指定保证呢
三个地方访问的表是相同的吧,如果是同一个表应该不行的。默认都是读写leader,leader只会在一个zone。
如果是不同租户还可以设置优先zone来实现。
obproxy 只是 sql 路由,只是业务读写的入口。在 ob 内部对于一个具体的表的分区而言,写入点只会有一个地方。
obproxy 路由策略里是可以绑定 LDC 特性,这个只是用于 弱一致性读(也就是读写分离的读)场景。obproxy 并不能决定数据写入在哪个 zone。
OB的这个分布式 不是 分库分表的那个,想哪里写入就哪里。
我知道只能读写主副本,但是https://open.oceanbase.com/blog/1100257下面的可以在两个zone都有主副本啊,如果此时两个zone中任意·一个都能有所有的主副本,这样理论上不就可以两地读写吗
是的。对于一个具体的分区 只有一个主副本,但是不同表的不同分区可以分布在任意 机房(ZONE),宏观层面就表现为多个节点机房的同时读写(双活或多活)。唯独南京机房由于是少数派副本所在地,不建议有主副本写入(可以写,性能会相对差一些)。可以参考下面文章。
那如果我想要对两地两个zone对同一张表的数据进行读写操作可以吗,这两个都是主副本。
- 你在两个机房单独链接本机房的obproxy写入这个表是可以的,那只是应用觉得是两个机房同时写入。
- 如果这个表是非分区表,则它的主副本只会出现在其中一个 Zone。另外一个Zone的针对这个主副本的写入请求会在 OB 集群的节点之间再次跳转。
- 如果这个表是分区表,通过负载均衡是有可能同一个表不同分区的主副本分布在两个Zone,那么在OB内部也是针对这个表在两个Zone同时写入。但是,你不能控制哪个分区(数据)应该在哪个Zone。
1:我不是需要应用觉得,而是真实就是访问本zone的。
所以还是没法在两地两个zone对同一张表的同一个数据进行读写是吧,所谓的多主副本概念是指的业务通过分库分表从而对同一张表分成多张表从而可能分布在多个区域在多个区域读写主副本,但是这个两个zone不是对同一条数据进行操作,而是就算从一个地区访问也会转到另外一个zone去读写是吧。
当你说到同一个数据的时候,就是对的了。
你的意思是同一个数据只会有一个主副本是吧,就算有多个zone,他还是只在某一个zone有主副本,只要是涉及到这个数据的读写,无论在哪里访问还是会转到这个zone的这唯一一个主副本对吧,但是将同一张表不同数据换划分到不同的zone的主副本此时都可以读写,我这样说对吧
对的。后面说的就是 OB 的分区表用法。分区表是一个表有多个分区,不同分区的主副本可以分散开。
OB的Paxos协议以及其他产品类似的Raft协议 本质上都是 单点写入 的协议。
大部分客户利用OB 构建双活和多活方案这一步就完全满足业务需求了。只有少数 互联网巨头的场景对性能要求更高,同时在业务层面将一个业务表拆分为多个物理表(分库分表),然后控制不同物理表的写入点在不同的机房,这就是单元化。分库分表跟传统mysql结合就是淘宝电商的单元化(5年前的架构),分库分表跟OB三地五中心结合就是支付宝的单元化。单元化的关键就是控制应用写入数据库的入口跟数据库内部主(OB叫主副本,MySQL叫Master)保持一致并联动。
少数OB客户用单元化一个原因是客户自身在两个远距离的城市有数据中心并各带多个机房,某些业务可以南北 分开提供访问,数据分散到多个集群和租户,集群部署交叉使用机房(互为容灾机房)。另外一个原因就是分库分表可以分散风险。这类客户业务访问区域比较集中且业务压力并不大。代价就是复杂度高(分库分表带来额外的分布式查询、分布式事务难题)。
所以,要不要双活,要什么程度的双活取决于业务场景需求。
好的,所以不存在真实的多个zone对同一个数据读写,但是可以设置不同区域有一些只读副本,这样还是可以做到对同一份数据多个读,但是写还是在一个地方的唯一主副本对吧。
是的。
好的,感谢
上面设置不同区域有一些只读副本,这样还是可以做到对同一份数据多个读,那我通过obproxy访问的方式如何指定就近读呢,比如az这个one就从a读,b这个zone从b读,这个怎么设置呢
这属于 OBPROXY 的 LDC 路由用法,又是读写分离加就近读,其前提条件是只读查询。注意,对于事务中的查询不会遵循这个。
-
- 部署单独用的 obproxy。
-
- 设置 obproxy 的
proxy_idc参数为对应zone里的observer 的 idc 名称。
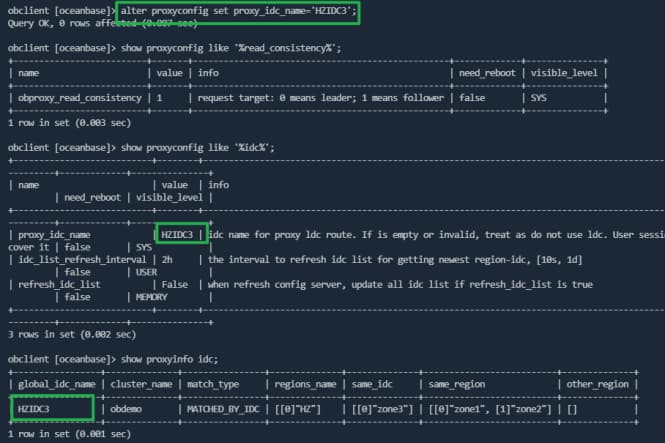
- 设置 obproxy 的
-
- 设置 obproxy 的
obproxy_read_consistency=1 。
- 设置 obproxy 的
-
- 业务连接对用zone 的 obproxy 。
也就是说我在a zone中部署一组obproxy集群,我用proxyro用户登录一下obclient,然后按照你描述的那样修改一下,再用a zone的读的话就会去a zone里面读,,但是事务有可能去b zone里面读是吧,但是如果同步成功了的话azone应该也有这个事务了啊,这个为什么不会走a zone读呢,还有就是我在部署安装设置的时候就要指定哪些区域是只读副本吧,以上这方面有没有什么案例或者比较详细一点的参考文档之类的吗